一、DeepSeek简介
DeepSeek是由中国深度求索公司开发的开源大语言模型系列,其研发始于2023年,目标是为学术界和产业界提供高效可控的AI基础设施。R1系列作为其里程碑版本,通过稀疏化架构和动态计算分配技术,在保持模型性能的同时显著降低了计算资源需求。
模型特点:
- 参数规模灵活:提供1.5B/7B/33B等多种规格
- 混合精度训练:支持FP16/INT8/INT4量化部署
- 上下文感知优化:动态分配计算资源至关键token
- 中文优化:在Wudao Corpus等中文数据集上强化训练
技术突破:
相比传统LLM,DeepSeek-R1通过以下创新实现低资源部署:
- MoE架构:专家混合层动态路由计算路径
- 梯度稀疏化:反向传播时仅更新关键参数
- 自适应量化:运行时根据硬件自动选择最优精度
二、CPU运行DeekSeek-R1:1.5b
2.1 ollama工具简介
使用ollama命令行工具,可以非常方便的下载和运行DeepSeek模型。
Ollama是一个获取和运行大语言模型的工具,官网的简介是:
Get up and running with large language models.
2.2 ollama命令安装
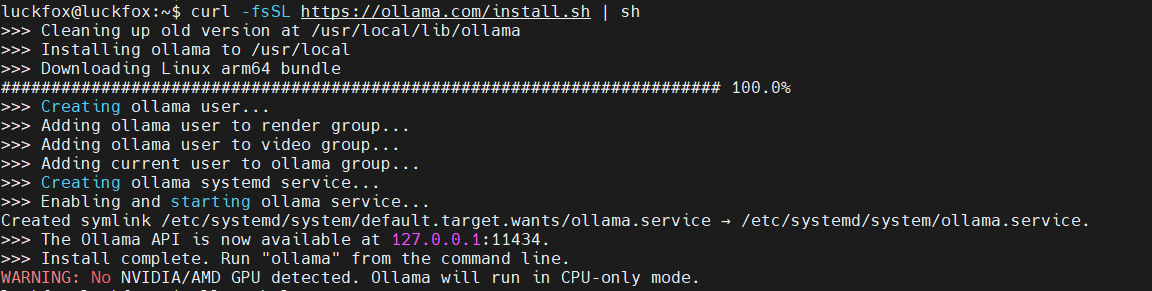
安装ollama非常简单,官网提供了在线安装脚本(install.sh),使用如下命令即可下载在线安装脚本并运行:
curl -fsSL https://ollama.com/install.sh | sh
命令输出如下:
2.3 ollama下载模型
安装好了ollama之后,我们就可以使用ollama下载deepseek-r1:1.5b模型了,使用如下命令:
ollama pull deepseek-r1:1.5b
拉取deepseek-r1 1.5b模型,过程中会下载速度和进度:

稍等一段时间,下载完成:

2.4 ollama运行模型
下载完deepseek-r1:1.5b模型后,就可以使用ollama运行deepseek模型了,使用如下命令:
ollama run deepseek-r1:1.5b
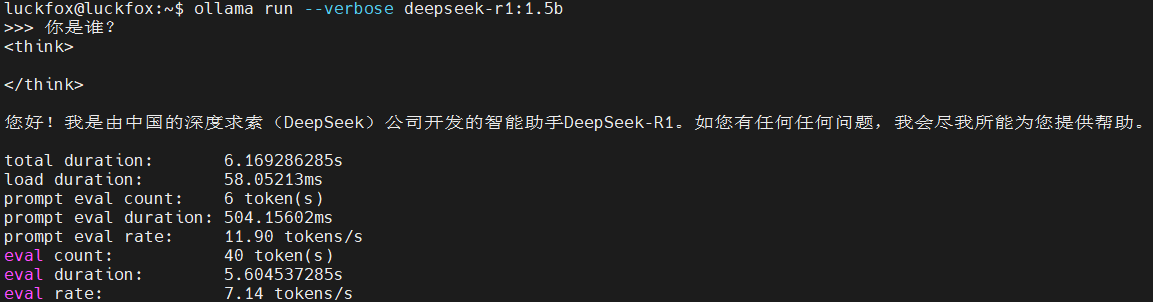
使用--verbose选项可以输出速度等数据,例如,问他“你是谁”,输出信息如下:
接下来,问一个经典的鸡兔同笼问题,结果也可以正确回答:
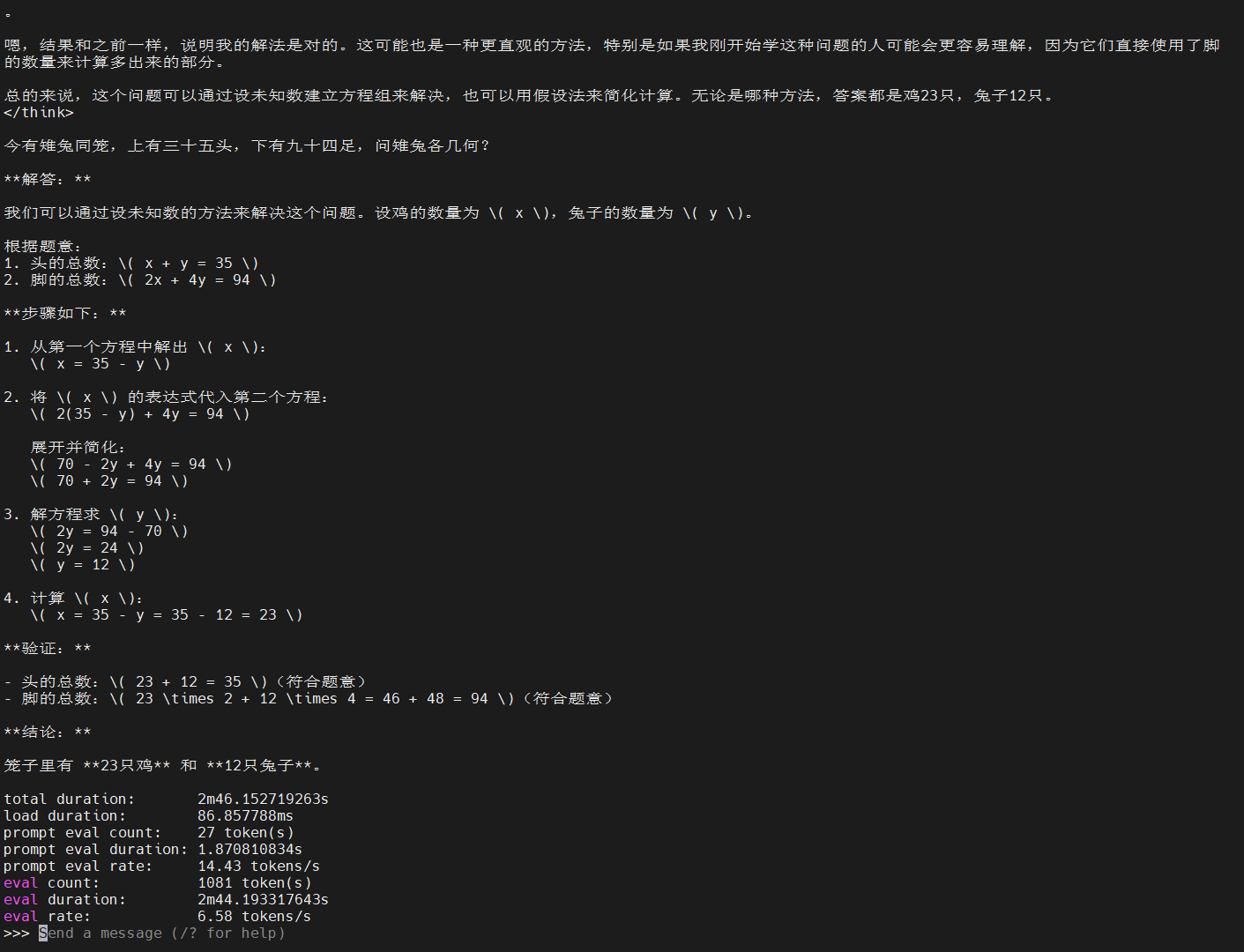
速度6.58 tokens/s,不是很快,但不算很卡。
三、CPU运行DeekSeek-R1:7b
和前面类似的,可以通过 ollama 命令拉取 deepseek-r1:7b 模型,命令为:
ollama pull deepseek-r1:7b
接着尝试运行deepseek-r1:7b模型,默认会出现内存不够的报错:

报错提示模型需要5.5GiB内次,当前可用的只有3.2GiB。
3.1 挂载固态硬盘
首先安装好固体硬盘:

然后上电,启动系统。
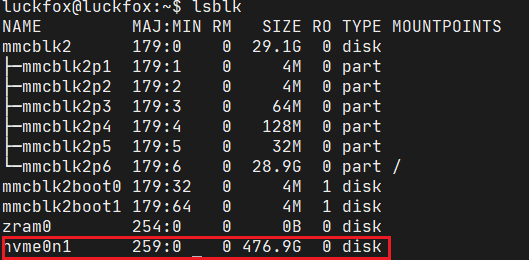
不出意外,执行lsblk命令,能够看到这个固体硬盘对应的块设备:
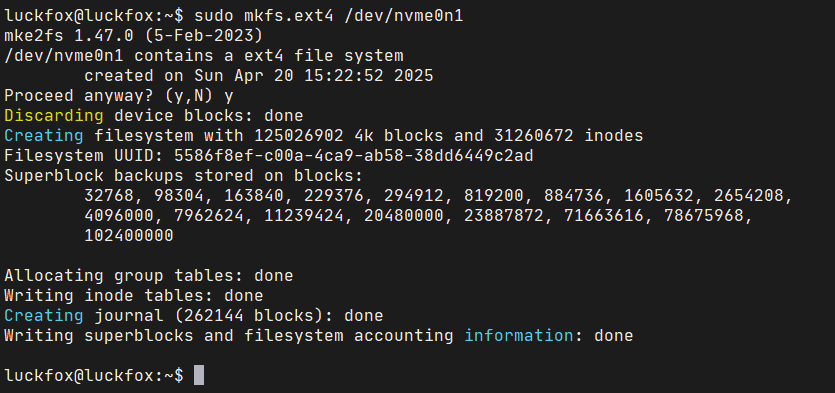
将其格式化为ext4文件系统,执行命令:
sudo mkfs.ext4 /dev/nvme0n1
命令输出如下:
接着创建用于挂载的目录:
sudo mkdir /mnt/ssd
最后,就可以前面格式化好的固态硬盘设备挂载到这个目录了:
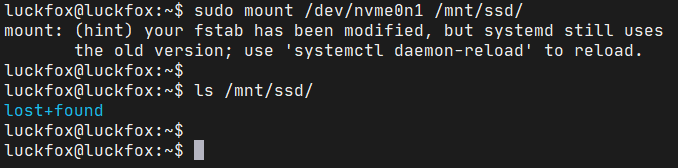
这里可以看到lost+found目录,这个目录是mkfs.ext4命令创建的,看到它说明已经成功挂载了。
3.2 测试固体硬盘
使用dd创建一个4GiB的文件,测试一下固态硬盘的写速度:

类似的可以测试一下,eMMC的写入速度:

测试结果上看,eMMC没有固体硬盘快,这也是为什么要用nvme固态作为后面配置交换分区的原因。
3.3 配置虚拟内存
Linux系统上,可以通过配置虚拟内存解决应用程序内存不够用的问题。配置交换分区的磁盘空间,可以被内核当做内存来用,但相应的速度要比实际的内存慢。
创建/mnt/ssd/swap.bin文件,并将内容格式化为swap格式:

接着,准备将其设置为交换分区,设置之前,查看当前系统内存信息:

可以看到,当前Swap大小为0.
设置交换分区之前,将swap.bin文件的读写权限设置为600:
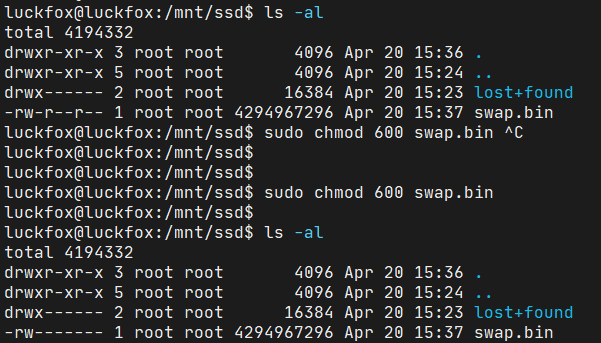
设置刚刚创建的swap.bin文件为交换分区:

设置成功后,可以通过free命令看到Swap内存变为4GiB了。
通过swapon --show命令也可以看到:

3.4 运行deepseek-r1:7b
接着,就可以运行deepseek-r1:7b了:
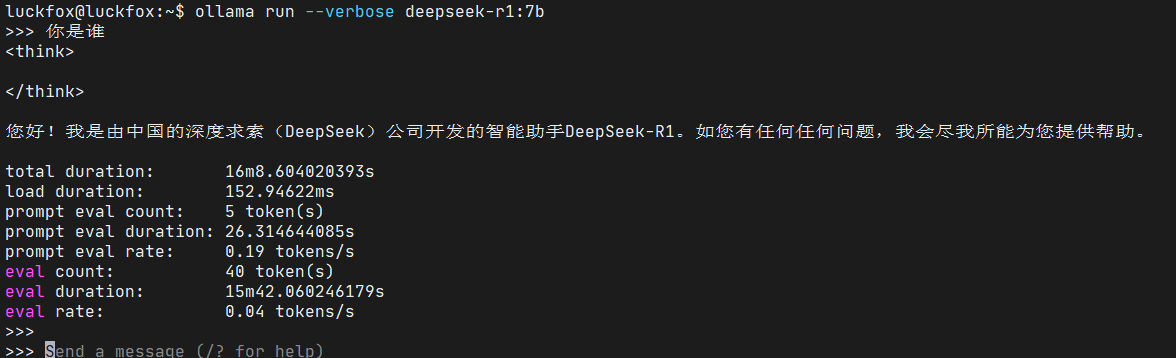
能跑起来,但是非常卡,已经卡的没法用了[doge]。不过也算是一次有意义的尝试。
四、参考链接
- DeepSeek官方文档
- Ollama GitHub仓库
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 1339
1339 淘帖
淘帖




