一.前言
前面把本地DeepSeek大模型的Server方式运行成功了,但是有点胡说八道的感觉,一直想着看自己转换一个高级点的模型文件来试试效果,所以今天就继续上次的内容搞自己转换大模型吧,上文传送门:【幸狐Omni3576边缘计算套件试用体验】使用rkllm运行DeepSeek的服务模式体验
二.下载并编译内核,升级NPU驱动
书接上回,根据手册下载sdk文件和搭建sdk编译环境:
- https://wiki.luckfox.com/zh/Luckfox-Omni3576/Download
- https://wiki.luckfox.com/zh/luckfox-Omni3576/Luckfox-Omni3576-SDK
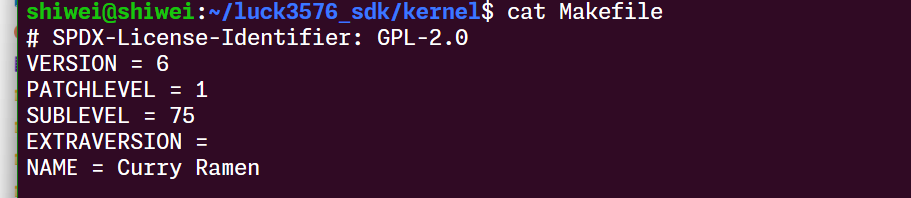
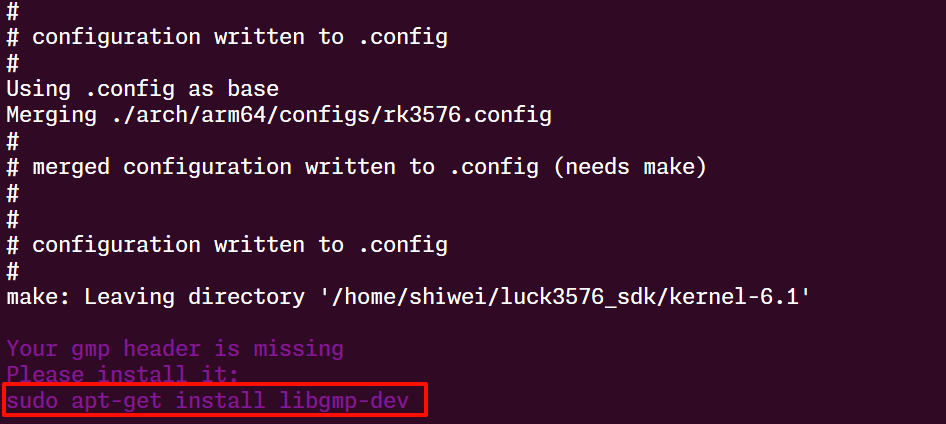
第一次编译可能中间会有缺少的内容,按我截图这样缺什么补什么就行:
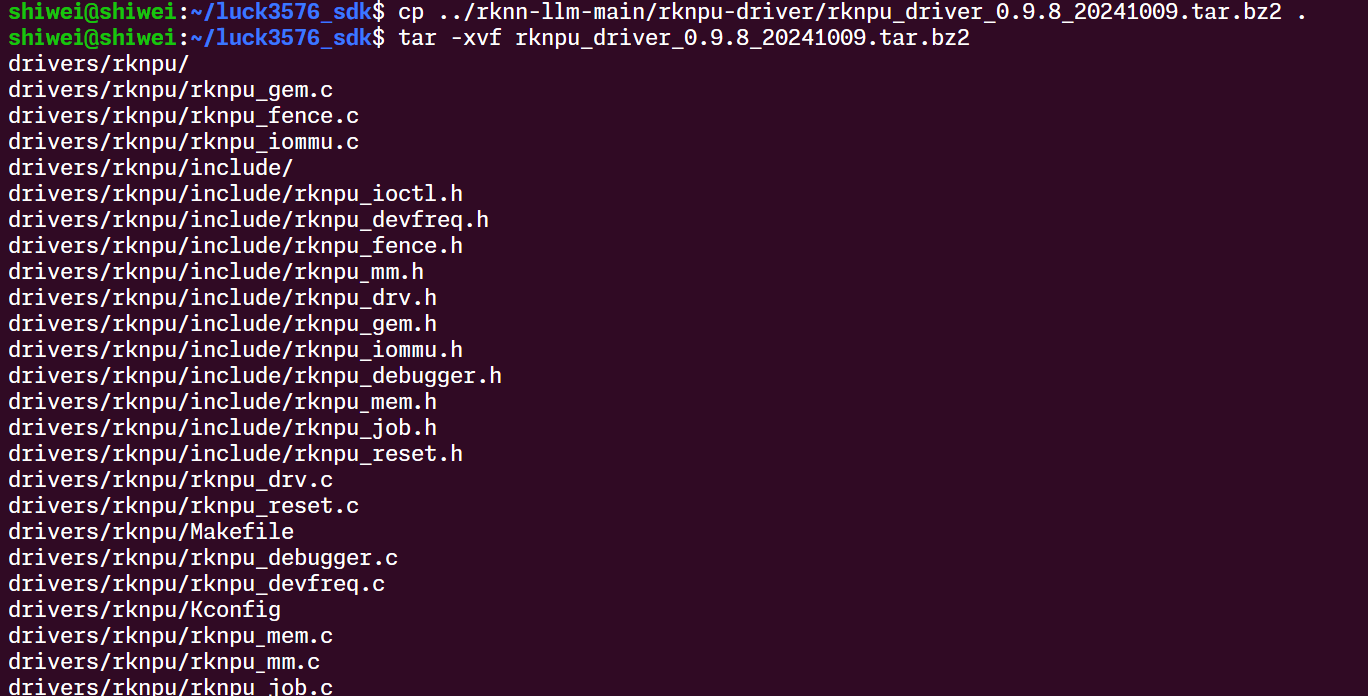
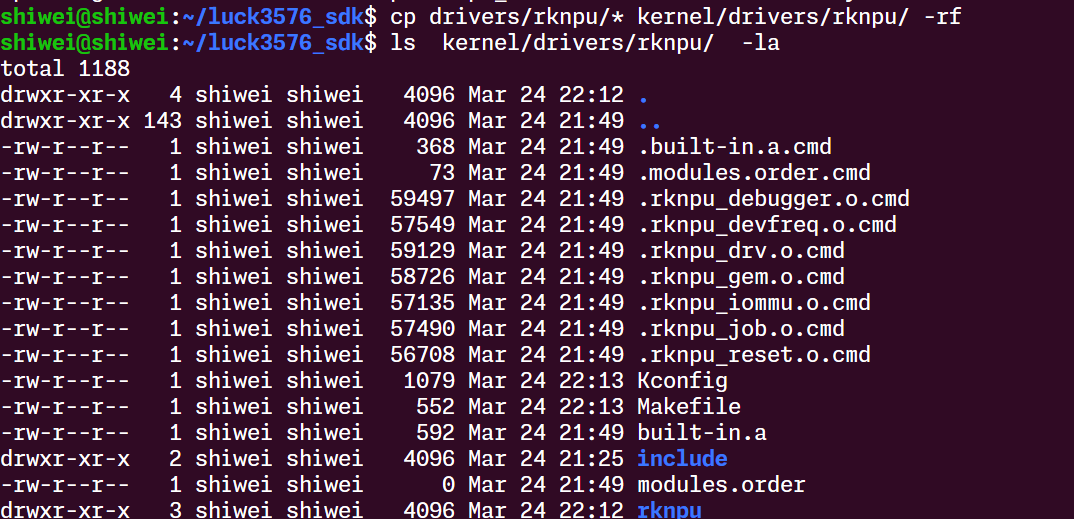
把npu驱动文件打到内核文件里去:
然后就编译成功:
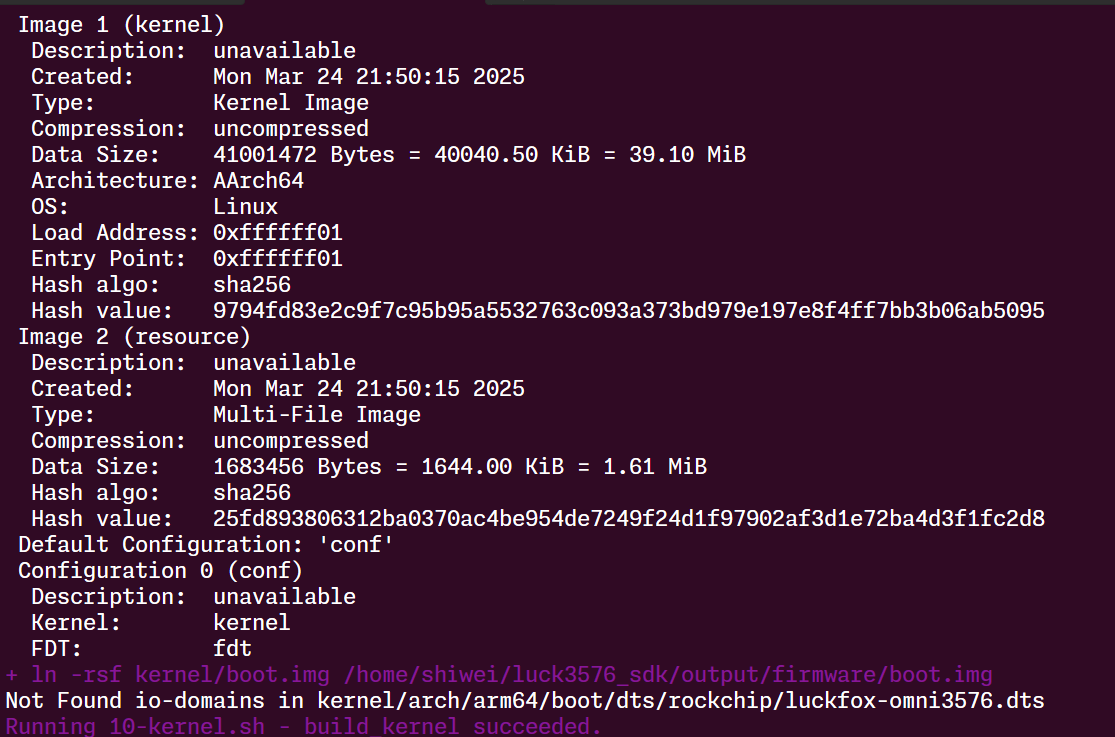
查看内核:

按照文档的烧录方式烧录到板子中,rknpu驱动升级成功:
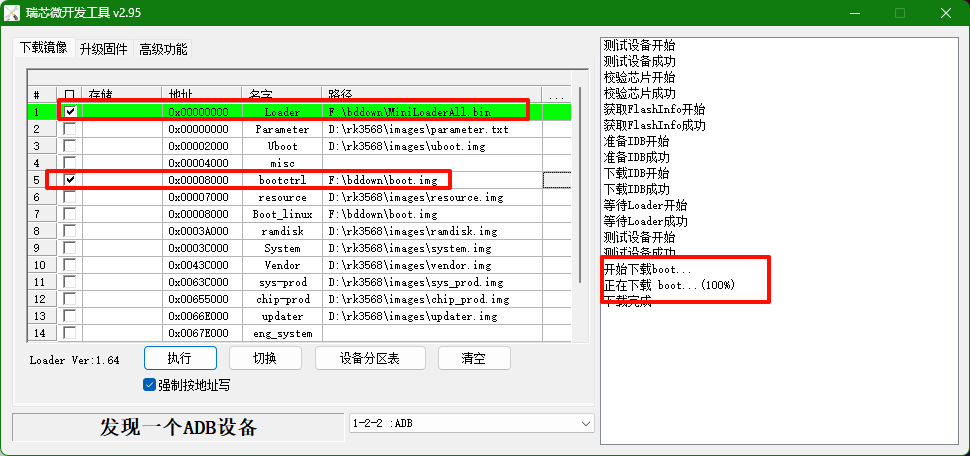
NPU升级成功啦:

接下可以来好好进行模型转换了
三.转换大模型
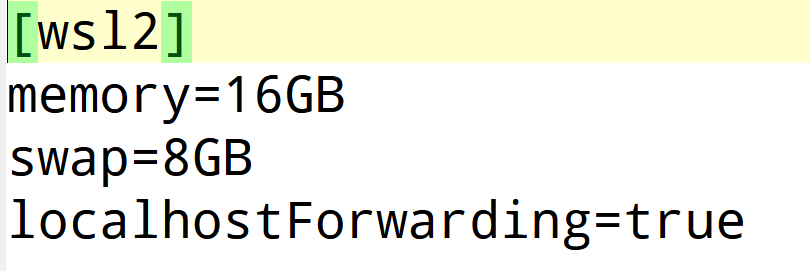
首先使用generate_data_quant.py指令生成数据集,这里注意因为8B模型数据量大,对对内存要求高,所以要提前把内存调大,我用的是wsl版本,已经加大到16G,

转换失败了,应该是被系统杀了:
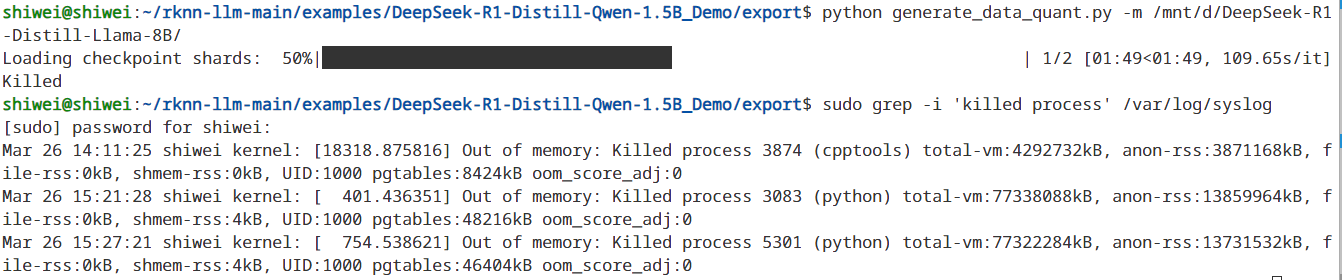
果然还是内存不够,家用电脑看来不太方便去进行模型转换了
跳过数据源看看直接导出看看
简单修改这两个地方:
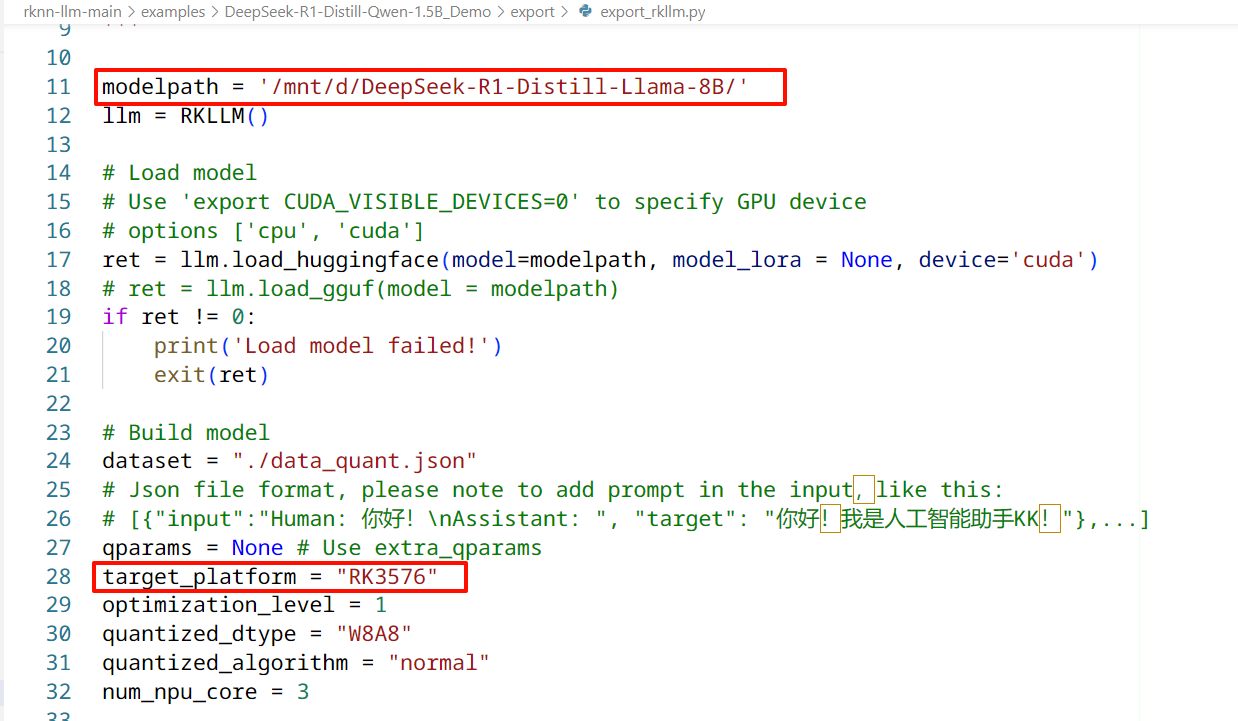
一样不行:
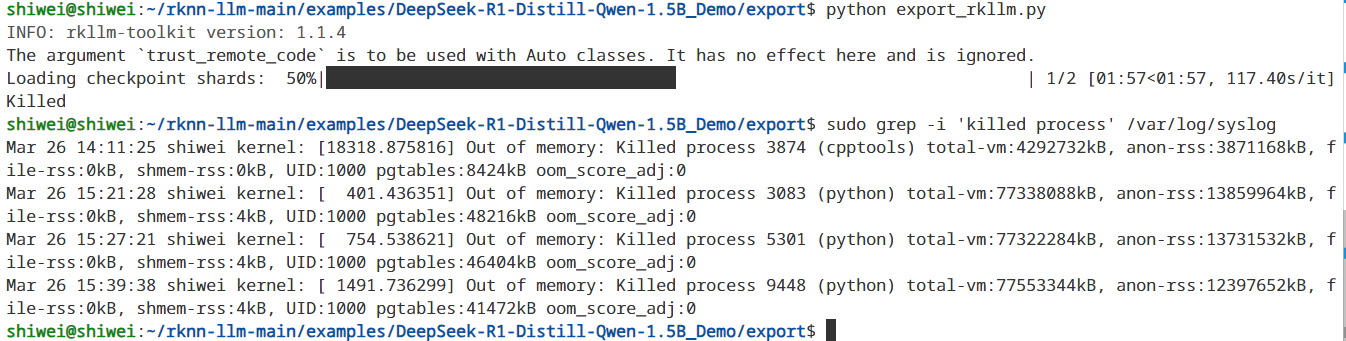
内存都占完了

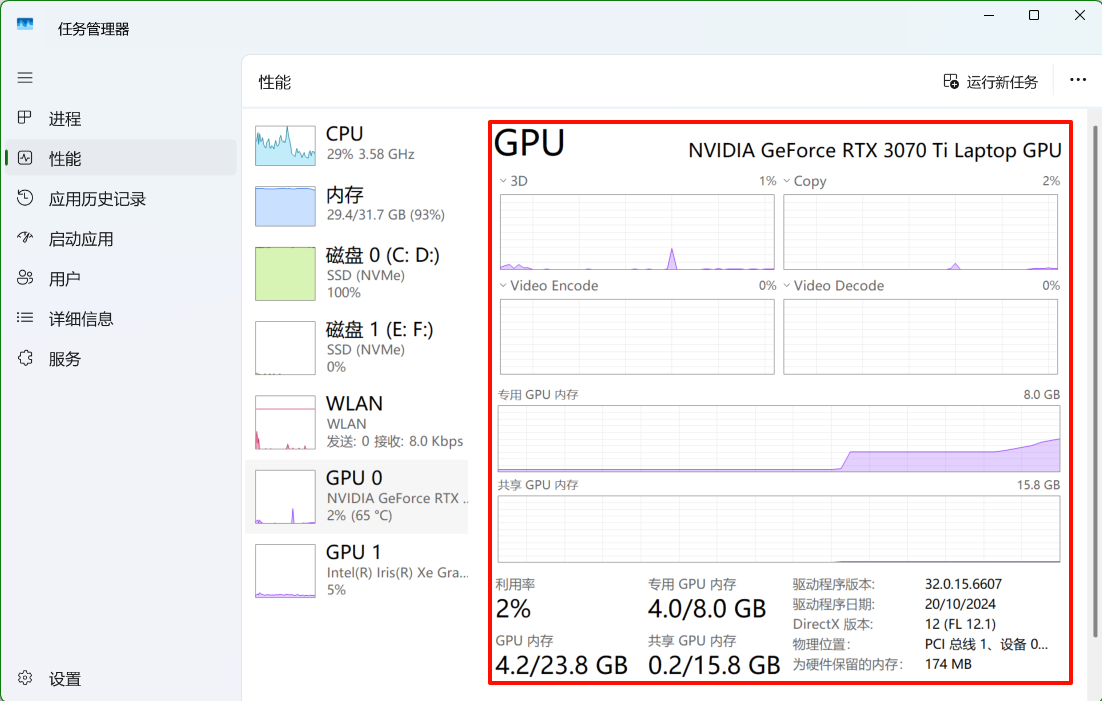
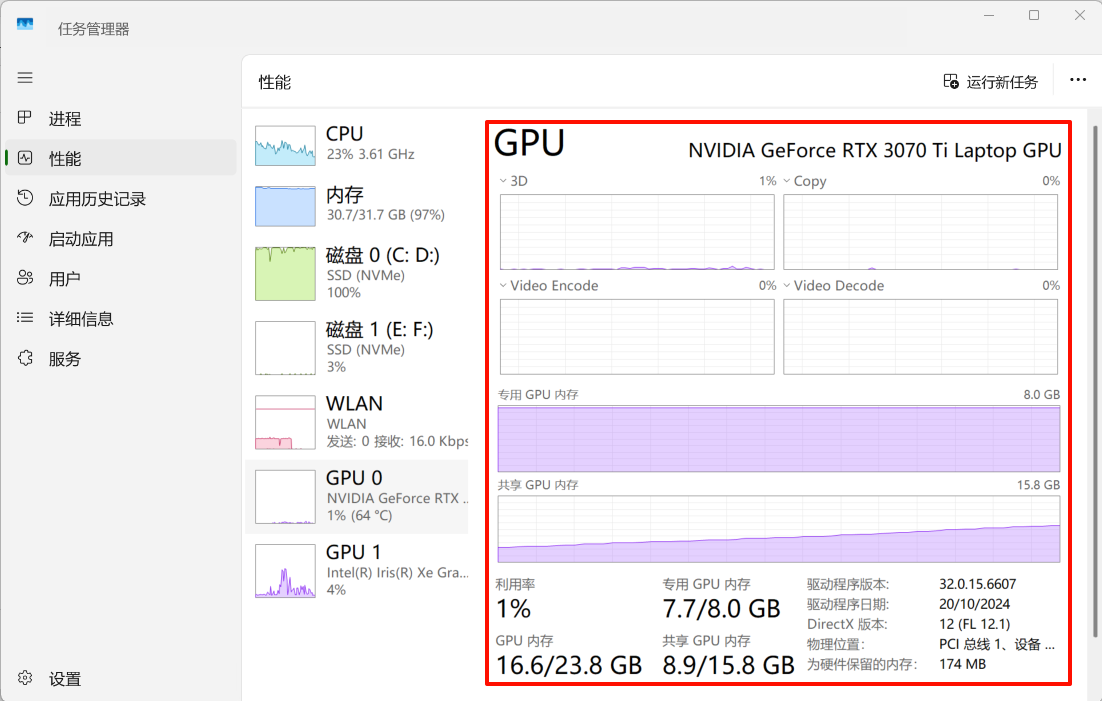

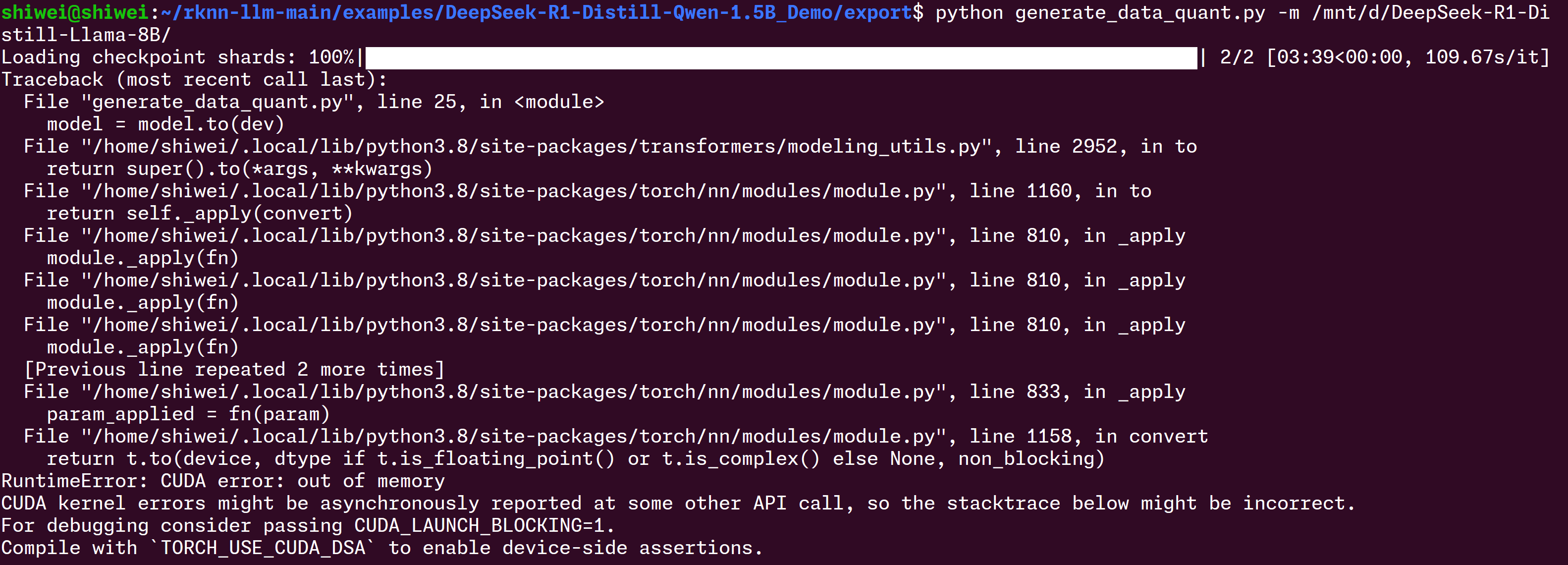
电脑重新开机,所有软件都不开,最终还是逃不过失败的命运,看来这个8B模型对内存和显存的要求是真高:
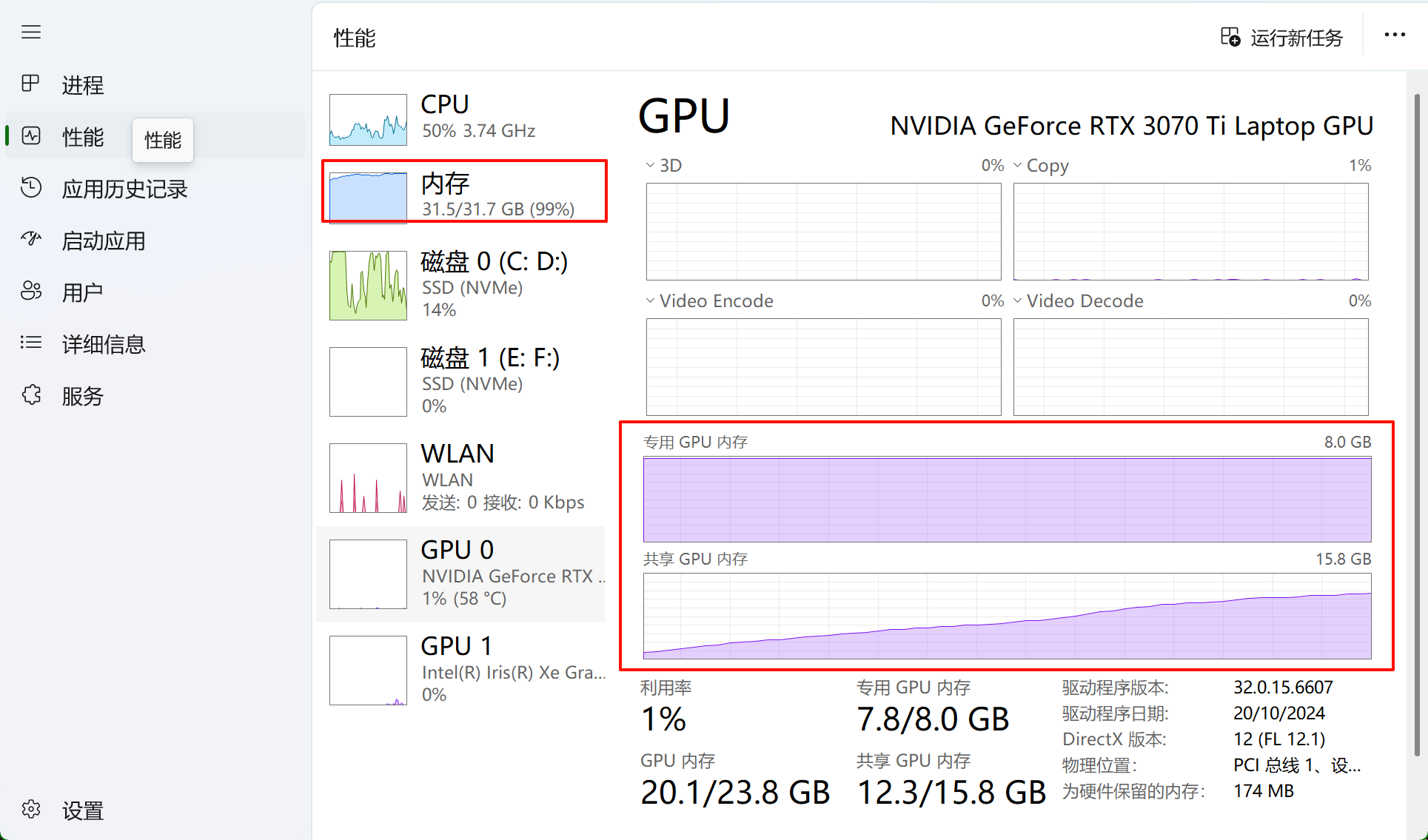
专门重新开机了,把所有软件都取消掉,结果还是不行:
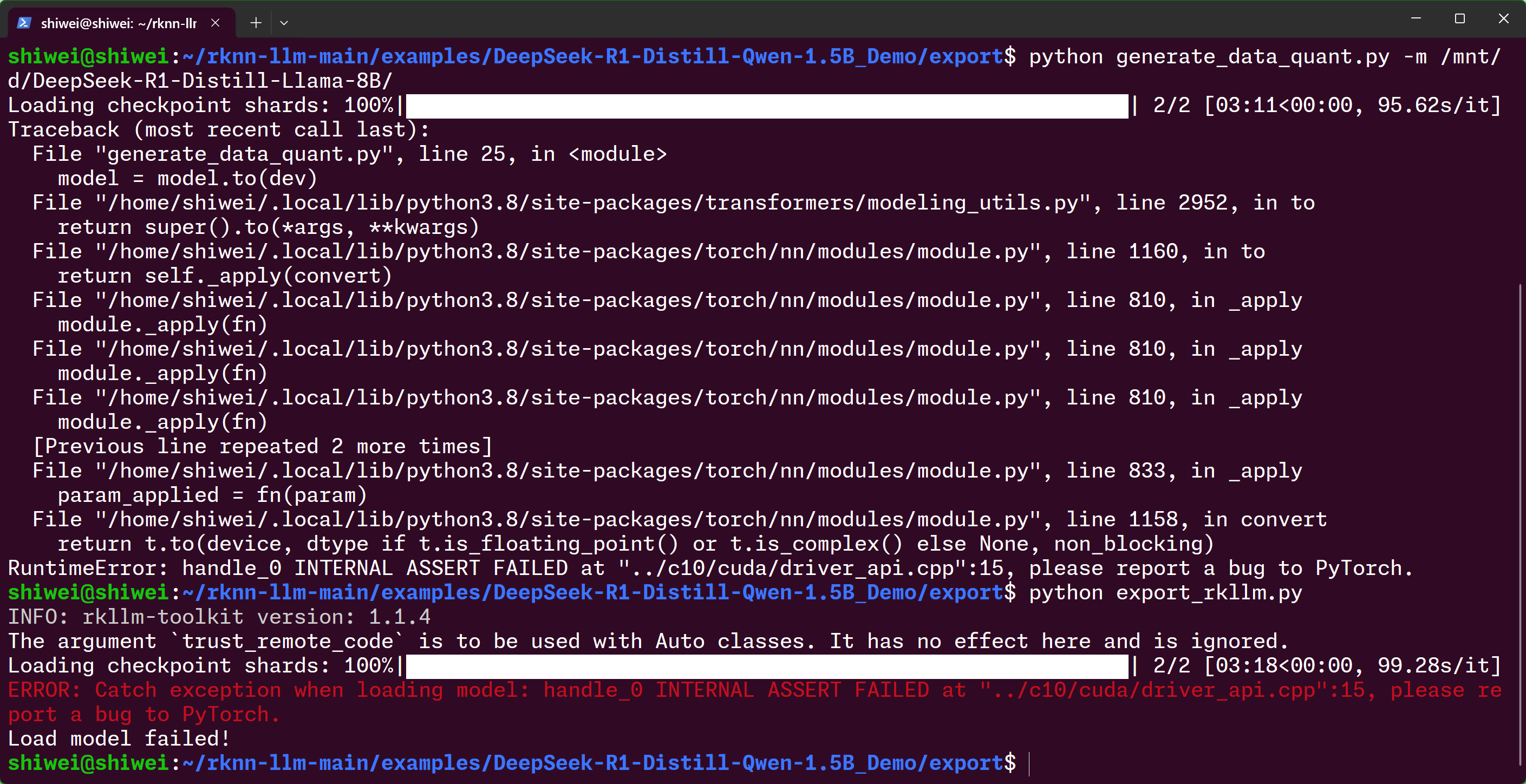
唉,看来自己转换模型感觉行不通,等我买了高配置的电脑再说吧,或者看看有没有有缘人捐赠一下.
四.喇叭硬件连接和测试
接下来还是做一下小智问答吧,首先需要把音频调出来.参考文档:
https://wiki.luckfox.com/zh/luckfox-Omni3576/Debian12/Omni3576-pinout/Audio
开发板自带Mic,找到我的喇叭接在3Pin喇叭插座上,就完成了基础布局,然后启动音频读取最好还有一个小按钮,由于开发板被外壳封住了,所以智能自己从ADC那里引一个按钮接口出来,用ADC采集来模拟按钮按下:



这里再次强烈吐槽这个外壳的设计,简直是一团糟,就不说预留一些给我拉线的孔吧,仅有的3个按键全部封在里面,然后40Pin的外接引脚,喇叭引脚全部封死在里面,那个挡板的孔位搞得严丝合缝,一点空间都不多留搞得现在那个前面的挡板现在都没法装进去,咋地用了外壳就没权利用喇叭这些东西吗,设计师打屁股.

准备找个时间重新设计一下外壳,这个外壳花了这么多钱感觉买了个寂寞,要搞点啥功能还得拆掉.像上面那两个地方拆掉的话,就可以引出串口线和喇叭线了,mic也不至于被堵死.
不说了,还是来调试把,根据文档的内容查看录音和播放设备,都没问题
体验中发现播放声音太小,也不知道是电压的问题还是什么原因,一直调也调不高,试图用tinymix提高音量,发现指令找不到:
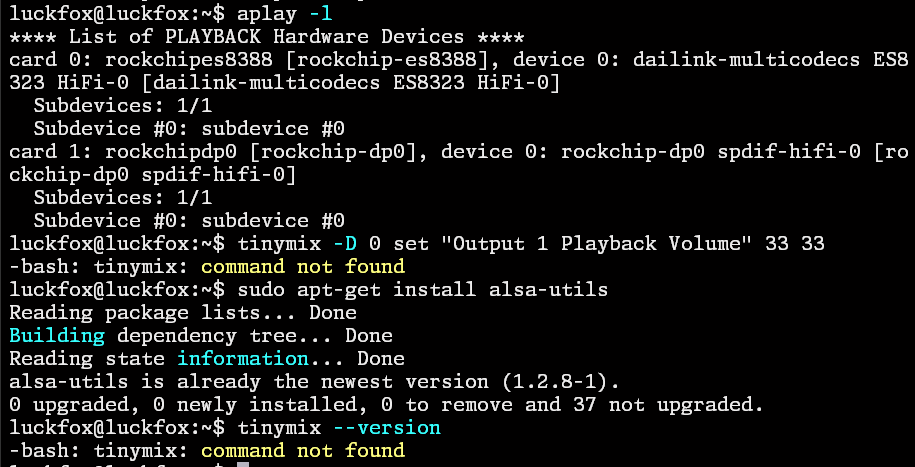
后面发现虽然没有tinymix指令,却有amixer指令,先用amixer contents -c 0查看控件id:
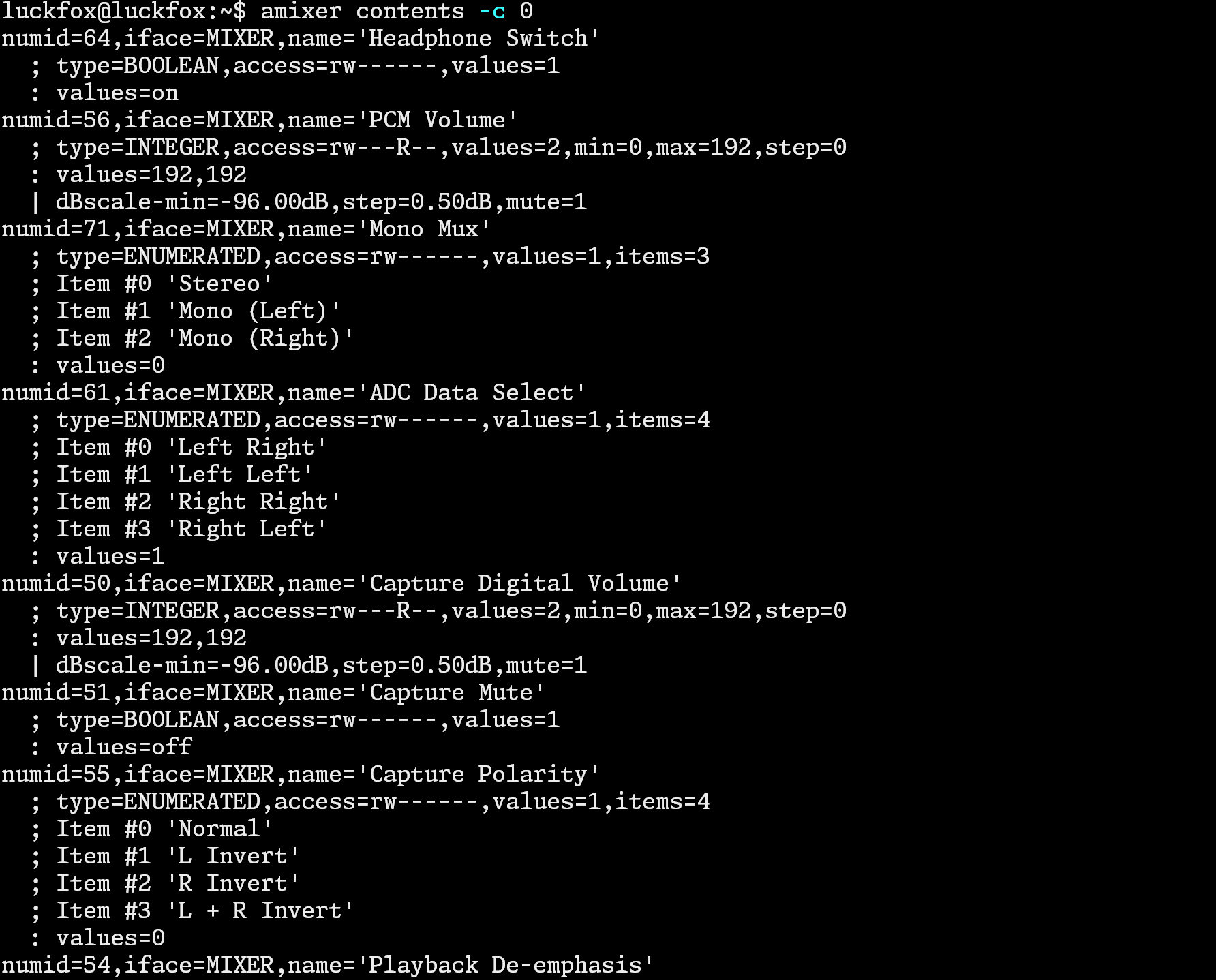
先设置一下录音的音量:

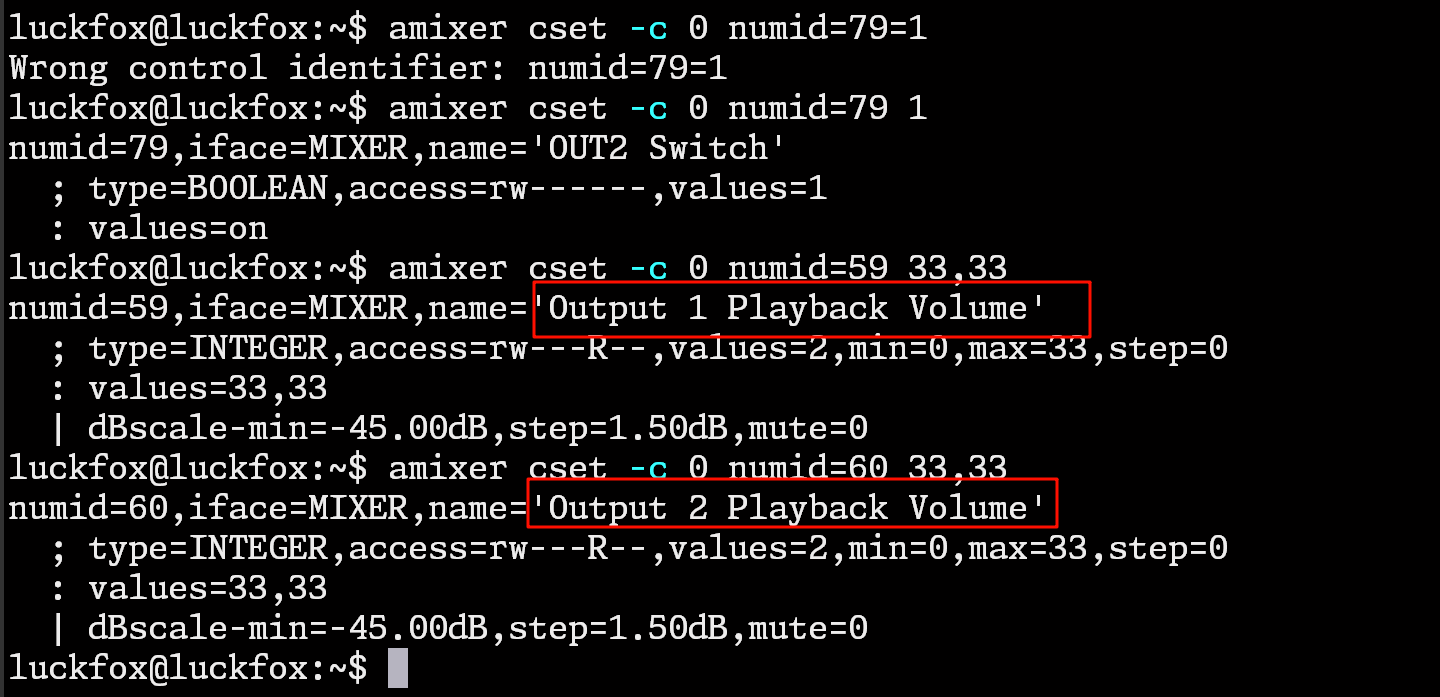
然后设置两边喇叭的音量加到最大:
amixer cset -c 0 numid=60 33,33
amixer cset -c 0 numid=59 33,33
五.小智代码和环境开发
然后导入智能语音助手的python代码,并添加adc采集充当button按键的代码,代码参考地址:https://wiki.luckfox.com/zh/luckfox-Omni3576/Debian12/Omni3576-pinout/ADC
ADC_DIR = "/sys/bus/iio/devices/iio:device0"
def read_value(file_path):
with open(file_path, "r") as file:
return file.read().strip()
def is_pressed():
IN0_raw_value = float(read_value(f"{ADC_DIR}/in_voltage0_raw"))
scale_value = float(read_value(f"{ADC_DIR}/in_voltage_scale"))
IN0_voltage = f"{IN0_raw_value * scale_value / 1000:.2f}"
v_i = IN0_raw_value * scale_value / 1000
if(v_i <0.3 ):
return True
else:
return False
def adc_read_th():
print("Press Ctrl+C to quit")
while True:
scale_value = float(read_value(f"{ADC_DIR}/in_voltage_scale"))
IN0_raw_value = float(read_value(f"{ADC_DIR}/in_voltage0_raw"))
IN1_raw_value = float(read_value(f"{ADC_DIR}/in_voltage1_raw"))
IN0_voltage = f"{IN0_raw_value * scale_value / 1000:.2f}"
IN1_voltage = f"{IN1_raw_value * scale_value / 1000:.2f}"
v_i = IN0_raw_value * scale_value / 1000
if(v_i <0.3 ):
print(f"IN0_Voltage: {IN0_voltage} V, IN1_Voltage: {IN1_voltage} V")
print(">>> 按键按下")
btnevent.set()
time.sleep(5)
time.sleep(0.5)
然后在系统本地启动deepseek的服务端模式,然后将本地的语音发送到deepseek服务上去:
spark_send_text = ""
import requests
server_url = 'http://localhost:8080/rkllm_chat'
is_streaming = False
session = requests.Session()
session.keep_alive = False
adapter = requests.adapters.HTTPAdapter(max_retries=5)
session.mount('https://', adapter)
session.mount('http://', adapter)
def localAI_process():
messages =[]
while True:
textevent.wait()
try:
print(">>get text")
global spark_send_text
data = text_queue.get(timeout=2)
print(">>data is:",data)
spark_send_text += data
except queue.Empty:
print("spark_send_text =",spark_send_text)
if len(spark_send_text) != 0:
user_message = spark_send_text
else:
continue
spark_send_text = ""
textevent.clear()
print("user message =",user_message)
if user_message == "拜拜":
print("============================")
print("The RKLLM Server is stopping......")
print("============================")
break
else:
headers = {
'Content-Type': 'application/json',
'Authorization': 'not_required'
}
data = {
"model": 'your_model_deploy_with_RKLLM_Server',
"messages": [{"role": "user", "content": user_message}],
"stream": is_streaming
}
responses = session.post(server_url, json=data, headers=headers, stream=is_streaming, verify=False)
if not is_streaming:
if responses.status_code == 200:
print("Q:", data["messages"][-1]["content"])
print("A:", json.loads(responses.text)["choices"][-1]["message"]["content"])
answer = json.loads(responses.text)["choices"][-1]["message"]["content"]
print(answer, end="")
rsp_queue.put(answer)
rsp_event.set()
else:
print("Error:", responses.text)
else:
if responses.status_code == 200:
print("Q:", data["messages"][-1]["content"])
print("A:", end="")
for line in responses.iter_lines():
if line:
line = json.loads(line.decode('utf-8'))
if line["choices"][-1]["finish_reason"] != "stop":
answer = line["choices"][-1]["delta"]["content"]
print(answer, end="")
sys.stdout.flush()
rsp_queue.put(answer)
rsp_event.set()
else:
print('Error:', responses.text)
except KeyboardInterrupt:
session.close()
print("\n")
print("============================")
print("The RKLLM Server is stopping......")
print("============================")
break
代码运行过程中需要安装alsaaudio,pyalsaaudio等库:
安装alsaaudio库:
sudo apt-get install python3-alsaaudio
sudo apt-get install alsaaudio
pip install pyalsaaudio

pip install websocket-client
pip install numpy
pip install openai
最后使用python启动代码就完成啦.且看视频效果
六.总结
一直把心心念念的搭建本地deepseek对话机器人搞完了,虽然目前回答的准确率还有效果都有点差强人意,应该在换了高级点的模型之后能好一点吧.
接下来看看能不能把本地的语音转换stt和tts搞出来,这样就不用把语音数据发到远程去转换文字了.
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 1345
1345

 淘帖
淘帖
 显身卡
显身卡





