K230D 支持多种 AI 应用,并且内置于 CanMV 镜像中,分为单模型应用和多模型应用两种,内容涵盖物体、人脸、人手、人体、车牌、OCR、音频(KWS、TTS)等多个应用领域。
这里选择几种 AI 应用进行演示,效果图片如下:
人脸关键部位标记

人脸标记

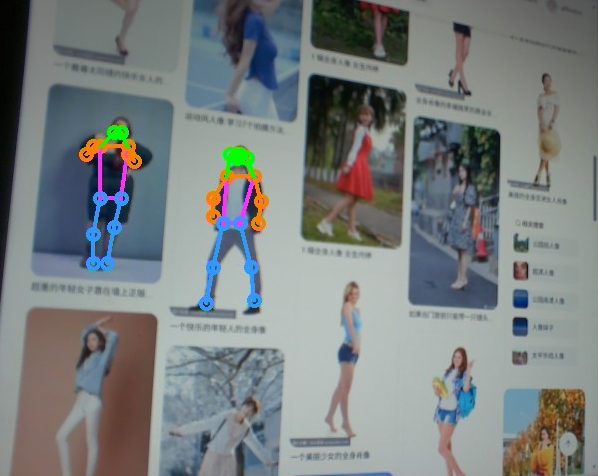
人体躯干标记
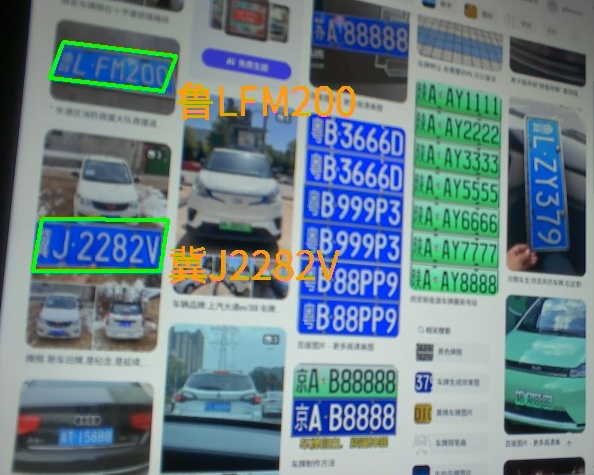
车牌识别
AI Demo 应用的源代码位于 /CanMV/sdcard/examples/05-AI-Demo 目录下,由于 K230D 内存较低,部分 Demo 可能无法运行,具体如下:
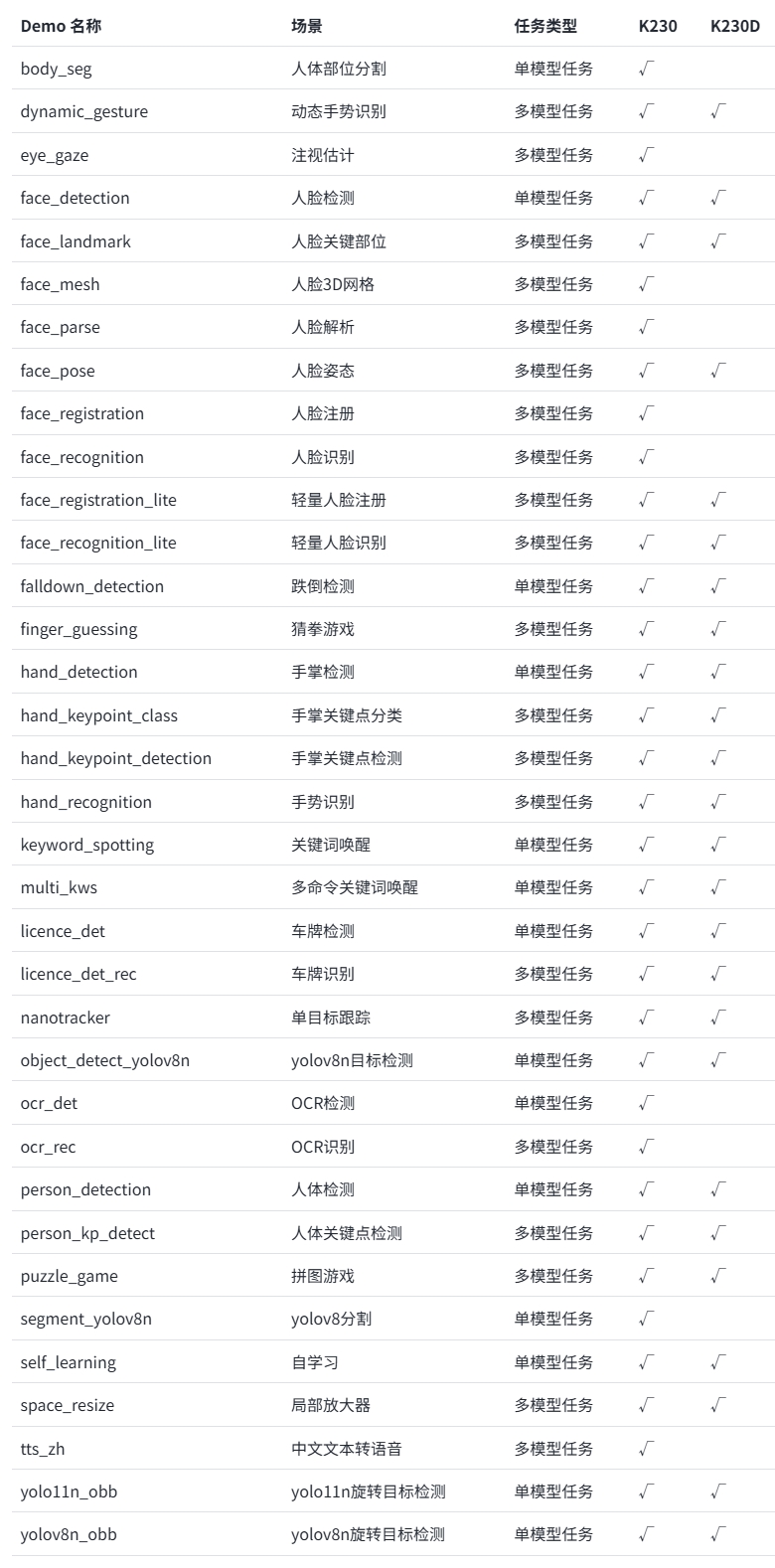
K230D 运行上述 demo 需要更改 __ main __ 中的 display_mode 为 lcd 适配显示输出,同时需要按照注释降低分辨率运行。同时部分 demo 无法在 K230D 上运行
实例程序如下:
人脸关键部位标记
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import image
import aidemo
import random
import gc
import sys
class FaceDetApp(AIBase):
def __init__(self,kmodel_path,model_input_size,anchors,confidence_threshold=0.25,nms_threshold=0.3,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
self.kmodel_path=kmodel_path
self.model_input_size=model_input_size
self.confidence_threshold=confidence_threshold
self.nms_threshold=nms_threshold
self.anchors=anchors
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
self.ai2d.pad(self.get_pad_param(), 0, [104,117,123])
# 设置resize预处理
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程,参数为预处理输入tensor的shape和预处理输出的tensor的shape
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义后处理,results是模型输出的array列表,这里使用了aidemo的face_det_post_process列表
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
res = aidemo.face_det_post_process(self.confidence_threshold,self.nms_threshold,self.model_input_size[0],self.anchors,self.rgb888p_size,results)
if len(res)==0:
return res
else:
return res[0]
def get_pad_param(self):
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
ratio_w = dst_w / self.rgb888p_size[0]
ratio_h = dst_h / self.rgb888p_size[1]
if ratio_w < ratio_h:
ratio = ratio_w
else:
ratio = ratio_h
new_w = (int)(ratio * self.rgb888p_size[0])
new_h = (int)(ratio * self.rgb888p_size[1])
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = (int)(round(0))
bottom = (int)(round(dh * 2 + 0.1))
left = (int)(round(0))
right = (int)(round(dw * 2 - 0.1))
return [0,0,0,0,top, bottom, left, right]
class FaceLandMarkApp(AIBase):
def __init__(self,kmodel_path,model_input_size,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
self.kmodel_path=kmodel_path
self.model_input_size=model_input_size
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
self.matrix_dst=None
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
def config_preprocess(self,det,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
self.matrix_dst = self.get_affine_matrix(det)
affine_matrix = [self.matrix_dst[0][0],self.matrix_dst[0][1],self.matrix_dst[0][2],
self.matrix_dst[1][0],self.matrix_dst[1][1],self.matrix_dst[1][2]]
self.ai2d.affine(nn.interp_method.cv2_bilinear,0, 0, 127, 1,affine_matrix)
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
pred=results[0]
half_input_len = self.model_input_size[0] // 2
pred = pred.flatten()
for i in range(len(pred)):
pred[i] += (pred[i] + 1) * half_input_len
matrix_dst_inv = aidemo.invert_affine_transform(self.matrix_dst)
matrix_dst_inv = matrix_dst_inv.flatten()
half_out_len = len(pred) // 2
for kp_id in range(half_out_len):
old_x = pred[kp_id * 2]
old_y = pred[kp_id * 2 + 1]
new_x = old_x * matrix_dst_inv[0] + old_y * matrix_dst_inv[1] + matrix_dst_inv[2]
new_y = old_x * matrix_dst_inv[3] + old_y * matrix_dst_inv[4] + matrix_dst_inv[5]
pred[kp_id * 2] = new_x
pred[kp_id * 2 + 1] = new_y
return pred
def get_affine_matrix(self,bbox):
with ScopedTiming("get_affine_matrix", self.debug_mode > 1):
x1, y1, w, h = map(lambda x: int(round(x, 0)), bbox[:4])
scale_ratio = (self.model_input_size[0]) / (max(w, h) * 1.5)
cx = (x1 + w / 2) * scale_ratio
cy = (y1 + h / 2) * scale_ratio
half_input_len = self.model_input_size[0] / 2
matrix_dst = np.zeros((2, 3), dtype=np.float)
matrix_dst[0, 0] = scale_ratio
matrix_dst[0, 1] = 0
matrix_dst[0, 2] = half_input_len - cx
matrix_dst[1, 0] = 0
matrix_dst[1, 1] = scale_ratio
matrix_dst[1, 2] = half_input_len - cy
return matrix_dst
class FaceLandMark:
def __init__(self,face_det_kmodel,face_landmark_kmodel,det_input_size,landmark_input_size,anchors,confidence_threshold=0.25,nms_threshold=0.3,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
self.face_det_kmodel=face_det_kmodel
self.face_landmark_kmodel=face_landmark_kmodel
self.det_input_size=det_input_size
self.landmark_input_size=landmark_input_size
self.anchors=anchors
self.confidence_threshold=confidence_threshold
self.nms_threshold=nms_threshold
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
self.dict_kp_seq = [
[43, 44, 45, 47, 46, 50, 51, 49, 48], # left_eyebrow
[97, 98, 99, 100, 101, 105, 104, 103, 102], # right_eyebrow
[35, 36, 33, 37, 39, 42, 40, 41], # left_eye
[89, 90, 87, 91, 93, 96, 94, 95], # right_eye
[34, 88], # pupil
[72, 73, 74, 86], # bridge_nose
[77, 78, 79, 80, 85, 84, 83], # wing_nose
[52, 55, 56, 53, 59, 58, 61, 68, 67, 71, 63, 64], # out_lip
[65, 54, 60, 57, 69, 70, 62, 66], # in_lip
[1, 9, 10, 11, 12, 13, 14, 15, 16, 2, 3, 4, 5, 6, 7, 8, 0, 24, 23, 22, 21, 20, 19, 18, 32, 31, 30, 29, 28, 27, 26, 25, 17] # basin
]
self.color_list_for_osd_kp = [
(255, 0, 255, 0),
(255, 0, 255, 0),
(255, 255, 0, 255),
(255, 255, 0, 255),
(255, 255, 0, 0),
(255, 255, 170, 0),
(255, 255, 255, 0),
(255, 0, 255, 255),
(255, 255, 220, 50),
(255, 30, 30, 255)
]
self.face_det=FaceDetApp(self.face_det_kmodel,model_input_size=self.det_input_size,anchors=self.anchors,confidence_threshold=self.confidence_threshold,nms_threshold=self.nms_threshold,rgb888p_size=self.rgb888p_size,display_size=self.display_size,debug_mode=0)
self.face_landmark=FaceLandMarkApp(self.face_landmark_kmodel,model_input_size=self.landmark_input_size,rgb888p_size=self.rgb888p_size,display_size=self.display_size)
self.face_det.config_preprocess()
def run(self,input_np):
det_boxes=self.face_det.run(input_np)
landmark_res=[]
for det_box in det_boxes:
self.face_landmark.config_preprocess(det_box)
res=self.face_landmark.run(input_np)
landmark_res.append(res)
return det_boxes,landmark_res
def draw_result(self,pl,dets,landmark_res):
pl.osd_img.clear()
if dets:
draw_img_np = np.zeros((self.display_size[1],self.display_size[0],4),dtype=np.uint8)
draw_img = image.Image(self.display_size[0], self.display_size[1], image.ARGB8888, alloc=image.ALLOC_REF,data = draw_img_np)
for pred in landmark_res:
for sub_part_index in range(len(self.dict_kp_seq)):
sub_part = self.dict_kp_seq[sub_part_index]
face_sub_part_point_set = []
for kp_index in range(len(sub_part)):
real_kp_index = sub_part[kp_index]
x, y = pred[real_kp_index * 2], pred[real_kp_index * 2 + 1]
x = int(x * self.display_size[0] // self.rgb888p_size[0])
y = int(y * self.display_size[1] // self.rgb888p_size[1])
face_sub_part_point_set.append((x, y))
if sub_part_index in (9, 6):
color = np.array(self.color_list_for_osd_kp[sub_part_index],dtype = np.uint8)
face_sub_part_point_set = np.array(face_sub_part_point_set)
aidemo.polylines(draw_img_np, face_sub_part_point_set,False,color,5,8,0)
elif sub_part_index == 4:
color = self.color_list_for_osd_kp[sub_part_index]
for kp in face_sub_part_point_set:
x,y = kp[0],kp[1]
draw_img.draw_circle(x,y ,2, color, 1)
else:
color = np.array(self.color_list_for_osd_kp[sub_part_index],dtype = np.uint8)
face_sub_part_point_set = np.array(face_sub_part_point_set)
aidemo.contours(draw_img_np, face_sub_part_point_set,-1,color,2,8)
pl.osd_img.copy_from(draw_img)
if __name__=="__main__":
display_mode="lcd"
rgb888p_size = [640,360]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
face_det_kmodel_path="/sdcard/examples/kmodel/face_detection_320.kmodel"
face_landmark_kmodel_path="/sdcard/examples/kmodel/face_landmark.kmodel"
anchors_path="/sdcard/examples/utils/prior_data_320.bin"
face_det_input_size=[320,320]
face_landmark_input_size=[192,192]
confidence_threshold=0.5
nms_threshold=0.2
anchor_len=4200
det_dim=4
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len,det_dim))
pl=PipeLine(rgb888p_size=rgb888p_size,display_size=display_size,display_mode=display_mode)
pl.create()
flm=FaceLandMark(face_det_kmodel_path,face_landmark_kmodel_path,det_input_size=face_det_input_size,landmark_input_size=face_landmark_input_size,anchors=anchors,confidence_threshold=confidence_threshold,nms_threshold=nms_threshold,rgb888p_size=rgb888p_size,display_size=display_size)
while True:
os.exitpoint()
with ScopedTiming("total",1):
img=pl.get_frame() # 获取当前帧
det_boxes,landmark_res=flm.run(img) # 推理当前帧
flm.draw_result(pl,det_boxes,landmark_res) # 绘制推理结果
pl.show_image() # 展示推理效果
gc.collect()
flm.face_det.deinit()
flm.face_landmark.deinit()
pl.destroy()
人脸标记
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import utime
import image
import random
import gc
import sys
import aidemo
class FaceDetectionApp(AIBase):
def __init__(self, kmodel_path, model_input_size, anchors, confidence_threshold=0.5, nms_threshold=0.2, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
self.kmodel_path = kmodel_path
self.model_input_size = model_input_size
self.confidence_threshold = confidence_threshold
self.nms_threshold = nms_threshold
self.anchors = anchors
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
self.debug_mode = debug_mode
self.ai2d = Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0):
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
top, bottom, left, right = self.get_padding_param()
self.ai2d.pad([0, 0, 0, 0, top, bottom, left, right], 0, [104, 117, 123])
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
post_ret = aidemo.face_det_post_process(self.confidence_threshold, self.nms_threshold, self.model_input_size[1], self.anchors, self.rgb888p_size, results)
if len(post_ret) == 0:
return post_ret
else:
return post_ret[0]
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
if dets:
pl.osd_img.clear()
for det in dets:
x, y, w, h = map(lambda x: int(round(x, 0)), det[:4])
x = x * self.display_size[0] // self.rgb888p_size[0]
y = y * self.display_size[1] // self.rgb888p_size[1]
w = w * self.display_size[0] // self.rgb888p_size[0]
h = h * self.display_size[1] // self.rgb888p_size[1]
pl.osd_img.draw_rectangle(x, y, w, h, color=(255, 255, 0, 255), thickness=2)
else:
pl.osd_img.clear()
def get_padding_param(self):
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
ratio_w = dst_w / self.rgb888p_size[0]
ratio_h = dst_h / self.rgb888p_size[1]
ratio = min(ratio_w, ratio_h)
new_w = int(ratio * self.rgb888p_size[0])
new_h = int(ratio * self.rgb888p_size[1])
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = int(round(0))
bottom = int(round(dh * 2 + 0.1))
left = int(round(0))
right = int(round(dw * 2 - 0.1))
return top, bottom, left, right
if __name__ == "__main__":
display_mode="lcd"
rgb888p_size = [640,360]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
kmodel_path = "/sdcard/examples/kmodel/face_detection_320.kmodel"
confidence_threshold = 0.5
nms_threshold = 0.2
anchor_len = 4200
det_dim = 4
anchors_path = "/sdcard/examples/utils/prior_data_320.bin"
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len, det_dim))
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create()
face_det = FaceDetectionApp(kmodel_path, model_input_size=[320, 320], anchors=anchors, confidence_threshold=confidence_threshold, nms_threshold=nms_threshold, rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
face_det.config_preprocess()
while True:
with ScopedTiming("total",1):
img = pl.get_frame()
res = face_det.run(img)
face_det.draw_result(pl, res)
pl.show_image()
gc.collect()
face_det.deinit()
pl.destroy()
人体躯干标记
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import utime
import image
import random
import gc
import sys
import aidemo
class PersonKeyPointApp(AIBase):
def __init__(self,kmodel_path,model_input_size,confidence_threshold=0.2,nms_threshold=0.5,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
self.kmodel_path=kmodel_path
self.model_input_size=model_input_size
self.confidence_threshold=confidence_threshold
self.nms_threshold=nms_threshold
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
self.SKELETON = [(16, 14),(14, 12),(17, 15),(15, 13),(12, 13),(6, 12),(7, 13),(6, 7),(6, 8),(7, 9),(8, 10),(9, 11),(2, 3),(1, 2),(1, 3),(2, 4),(3, 5),(4, 6),(5, 7)]
self.LIMB_COLORS = [(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 255, 51, 255),(255, 255, 51, 255),(255, 255, 51, 255),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0)]
self.KPS_COLORS = [(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255)]
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
top,bottom,left,right=self.get_padding_param()
self.ai2d.pad([0,0,0,0,top,bottom,left,right], 0, [0,0,0])
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义当前任务的后处理
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
# 这里使用了aidemo库的person_kp_postprocess接口
results = aidemo.person_kp_postprocess(results[0],[self.rgb888p_size[1],self.rgb888p_size[0]],self.model_input_size,self.confidence_threshold,self.nms_threshold)
return results
#绘制结果,绘制人体关键点
def draw_result(self,pl,res):
with ScopedTiming("display_draw",self.debug_mode >0):
if res[0]:
pl.osd_img.clear()
kpses = res[1]
for i in range(len(res[0])):
for k in range(17+2):
if (k < 17):
kps_x,kps_y,kps_s = round(kpses[i][k][0]),round(kpses[i][k][1]),kpses[i][k][2]
kps_x1 = int(float(kps_x) * self.display_size[0] // self.rgb888p_size[0])
kps_y1 = int(float(kps_y) * self.display_size[1] // self.rgb888p_size[1])
if (kps_s > 0):
pl.osd_img.draw_circle(kps_x1,kps_y1,5,self.KPS_COLORS[k],4)
ske = self.SKELETON[k]
pos1_x,pos1_y= round(kpses[i][ske[0]-1][0]),round(kpses[i][ske[0]-1][1])
pos1_x_ = int(float(pos1_x) * self.display_size[0] // self.rgb888p_size[0])
pos1_y_ = int(float(pos1_y) * self.display_size[1] // self.rgb888p_size[1])
pos2_x,pos2_y = round(kpses[i][(ske[1] -1)][0]),round(kpses[i][(ske[1] -1)][1])
pos2_x_ = int(float(pos2_x) * self.display_size[0] // self.rgb888p_size[0])
pos2_y_ = int(float(pos2_y) * self.display_size[1] // self.rgb888p_size[1])
pos1_s,pos2_s = kpses[i][(ske[0] -1)][2],kpses[i][(ske[1] -1)][2]
if (pos1_s > 0.0 and pos2_s >0.0):
pl.osd_img.draw_line(pos1_x_,pos1_y_,pos2_x_,pos2_y_,self.LIMB_COLORS[k],4)
gc.collect()
else:
pl.osd_img.clear()
def get_padding_param(self):
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
input_width = self.rgb888p_size[0]
input_high = self.rgb888p_size[1]
ratio_w = dst_w / input_width
ratio_h = dst_h / input_high
if ratio_w < ratio_h:
ratio = ratio_w
else:
ratio = ratio_h
new_w = (int)(ratio * input_width)
new_h = (int)(ratio * input_high)
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = int(round(dh - 0.1))
bottom = int(round(dh + 0.1))
left = int(round(dw - 0.1))
right = int(round(dw - 0.1))
return top, bottom, left, right
if __name__=="__main__":
display_mode="lcd"
rgb888p_size = [1920, 1080]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
kmodel_path="/sdcard/examples/kmodel/yolov8n-pose.kmodel"
confidence_threshold = 0.2
nms_threshold = 0.5
pl=PipeLine(rgb888p_size=rgb888p_size,display_size=display_size,display_mode=display_mode)
pl.create()
person_kp=PersonKeyPointApp(kmodel_path,model_input_size=[320,320],confidence_threshold=confidence_threshold,nms_threshold=nms_threshold,rgb888p_size=rgb888p_size,display_size=display_size,debug_mode=0)
person_kp.config_preprocess()
while True:
with ScopedTiming("total",1):
img=pl.get_frame()
res=person_kp.run(img)
person_kp.draw_result(pl,res)
pl.show_image()
gc.collect()
person_kp.deinit()
pl.destroy()
车牌识别
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import image
import aidemo
import random
import gc
import sys
class LicenceDetectionApp(AIBase):
def __init__(self, kmodel_path, model_input_size, confidence_threshold=0.5, nms_threshold=0.2, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
self.kmodel_path = kmodel_path
self.model_input_size = model_input_size
self.confidence_threshold = confidence_threshold
self.nms_threshold = nms_threshold
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
self.debug_mode = debug_mode
self.ai2d = Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0):
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
det_res = aidemo.licence_det_postprocess(results, [self.rgb888p_size[1], self.rgb888p_size[0]], self.model_input_size, self.confidence_threshold, self.nms_threshold)
return det_res
class LicenceRecognitionApp(AIBase):
def __init__(self,kmodel_path,model_input_size,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
self.kmodel_path=kmodel_path
self.model_input_size=model_input_size
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
self.dict_rec = ["挂", "使", "领", "澳", "港", "皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", "_", "-"]
self.dict_size = len(self.dict_rec)
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
output_data=results[0].reshape((-1,self.dict_size))
max_indices = np.argmax(output_data, axis=1)
result_str = ""
for i in range(max_indices.shape[0]):
index = max_indices[i]
if index > 0 and (i == 0 or index != max_indices[i - 1]):
result_str += self.dict_rec[index - 1]
return result_str
class LicenceRec:
def __init__(self,licence_det_kmodel,licence_rec_kmodel,det_input_size,rec_input_size,confidence_threshold=0.25,nms_threshold=0.3,rgb888p_size=[1920,1080],display_size=[1920,1080],debug_mode=0):
self.licence_det_kmodel=licence_det_kmodel
self.licence_rec_kmodel=licence_rec_kmodel
self.det_input_size=det_input_size
self.rec_input_size=rec_input_size
self.confidence_threshold=confidence_threshold
self.nms_threshold=nms_threshold
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
self.licence_det=LicenceDetectionApp(self.licence_det_kmodel,model_input_size=self.det_input_size,confidence_threshold=self.confidence_threshold,nms_threshold=self.nms_threshold,rgb888p_size=self.rgb888p_size,display_size=self.display_size,debug_mode=0)
self.licence_rec=LicenceRecognitionApp(self.licence_rec_kmodel,model_input_size=self.rec_input_size,rgb888p_size=self.rgb888p_size)
self.licence_det.config_preprocess()
def run(self,input_np):
det_boxes=self.licence_det.run(input_np)
imgs_array_boxes = aidemo.ocr_rec_preprocess(input_np,[self.rgb888p_size[1],self.rgb888p_size[0]],det_boxes)
imgs_array = imgs_array_boxes[0]
boxes = imgs_array_boxes[1]
rec_res = []
for img_array in imgs_array:
self.licence_rec.config_preprocess(input_image_size=[img_array.shape[3],img_array.shape[2]])
licence_str=self.licence_rec.run(img_array)
rec_res.append(licence_str)
gc.collect()
return det_boxes,rec_res
def draw_result(self,pl,det_res,rec_res):
pl.osd_img.clear()
if det_res:
point_8 = np.zeros((8),dtype=np.int16)
for det_index in range(len(det_res)):
for i in range(4):
x = det_res[det_index][i * 2 + 0]/self.rgb888p_size[0]*self.display_size[0]
y = det_res[det_index][i * 2 + 1]/self.rgb888p_size[1]*self.display_size[1]
point_8[i * 2 + 0] = int(x)
point_8[i * 2 + 1] = int(y)
for i in range(4):
pl.osd_img.draw_line(point_8[i * 2 + 0],point_8[i * 2 + 1],point_8[(i+1) % 4 * 2 + 0],point_8[(i+1) % 4 * 2 + 1],color=(255, 0, 255, 0),thickness=4)
pl.osd_img.draw_string_advanced( point_8[6], point_8[7] + 20, 40,rec_res[det_index] , color=(255,255,153,18))
if __name__=="__main__":
display_mode="lcd"
rgb888p_size = [640,360]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
licence_det_kmodel_path="/sdcard/examples/kmodel/LPD_640.kmodel"
licence_rec_kmodel_path="/sdcard/examples/kmodel/licence_reco.kmodel"
licence_det_input_size=[640,640]
licence_rec_input_size=[220,32]
confidence_threshold=0.2
nms_threshold=0.2
pl=PipeLine(rgb888p_size=rgb888p_size,display_size=display_size,display_mode=display_mode)
pl.create()
lr=LicenceRec(licence_det_kmodel_path,licence_rec_kmodel_path,det_input_size=licence_det_input_size,rec_input_size=licence_rec_input_size,confidence_threshold=confidence_threshold,nms_threshold=nms_threshold,rgb888p_size=rgb888p_size,display_size=display_size)
while True:
with ScopedTiming("total",1):
img=pl.get_frame()
det_res,rec_res=lr.run(img)
lr.draw_result(pl,det_res,rec_res)
pl.show_image()
gc.collect()
lr.licence_det.deinit()
lr.licence_rec.deinit()
pl.destroy()
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 1235
1235
 淘帖
淘帖




