- 本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
- 成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
- 黑龙江大学大一在校生
- 华南理工大学大一在校生
- 我们是来自
6个地方的同学,我们在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究操作系统技术…
@[toc]
【往期回顾】
① 2月23日 《老子到此一游系列》之 老子为什么是老子 —— ++综述视角解读压缩编码++
② 3月11日 《老子到此一游系列》之 老子带你看懂这些风景 —— ++多维探秘通用无损压缩++
③ 3月25日 《老子到此一游系列》之 老子见证的沧海桑田 —— ++轻翻那些永垂不朽的诗篇++
④ 4月4日 《老子到此一游系列》之 老子游玩了一条河 —— ++细数生活中的压缩点滴++
⑤ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——一文穿透多媒体过往前沿++
⑥ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——这些小风景你不应该错过++
⑦ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——浅析稀疏表示医学图像++
⑧ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——计算机视觉数据压缩应用++
⑨ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——点燃主缓存压缩技术火花++
⑩ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——即刻征服3D网格压缩编码++
⑪ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——云计算数据压缩方案++
⑫ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——大数据框架性能优化系统++
⑬ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——物联网摇摆门趋势算法++
⑭ 5月22日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——电子设备软件更新压缩++
⑮ 5月22日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——人工智能短字符串压缩++
⑯ 5月22日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——多层存储分级数据压缩++
⑰ 6月3日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——数据高通量无损压缩方案++
⑱ 6月3日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——快速随机访问字符串压缩++
⑲ 6月13日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——gpu上高效无损压缩浮点数 ++
⑳ 6月13日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部—一种深度神经网压缩算法 ++
㉑ 6月13日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部—硬件加速的快速无损压缩++
【本期看点】
揭秘谷歌应用EROFS到安卓的原因EROFS为何能在文件压缩系统领域大放光彩神秘的LZ4m如何给内存压缩领域带来新的生机
【技术DNA】
【智慧场景】
| ********** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
***************** |
***************** |
******************** |
| 场景 |
自动驾驶 / AR |
语音信号 |
流视频 |
GPU 渲染 |
科学、云计算 |
内存缩减 |
科学应用 |
医学图像 |
数据库服务器 |
人工智能图像 |
文本传输 |
GAN媒体压缩 |
图像压缩 |
文件同步 |
数据库系统 |
通用数据 |
系统数据读写 |
| 技术 |
点云压缩 |
稀疏快速傅里叶变换 |
有损视频压缩 |
网格压缩 |
动态选择压缩算法框架 |
无损压缩 |
分层数据压缩 |
医学图像压缩 |
无损通用压缩 |
人工智能图像压缩 |
短字符串压缩 |
GAN 压缩的在线多粒度蒸馏 |
图像压缩 |
文件传输压缩 |
快速随机访问字符串压缩 |
高通量并行无损压缩 |
增强只读文件系统 |
| 开源项目 |
Draco / 基于深度学习算法/PCL/OctNet |
SFFT |
AV1 / H.266编码 / H.266解码/VP9 |
MeshOpt / Draco |
Ares |
LZ4 |
HCompress |
DICOM |
Brotli |
RAISR |
AIMCS |
OMGD |
OpenJPEG |
rsync |
FSST |
ndzip |
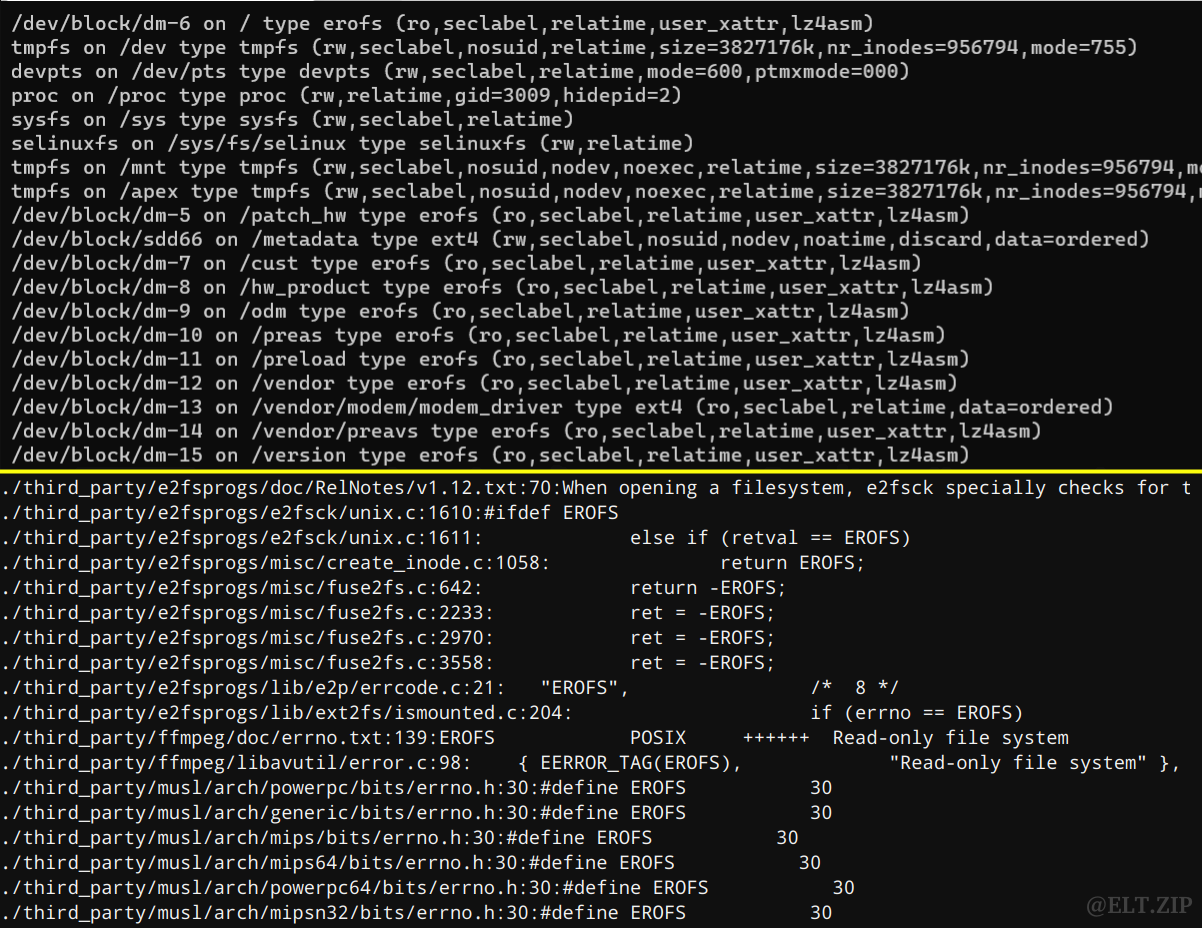
EROFS |
引言
- 在高度信息化的现代社会,
智能手机,已然成为我们生活中不可或缺的一部分。

- 对于日益壮大的
低头族,智能手机的性能就显得尤为重要。

目前的问题
智能手机的存储空间和运行时内存通常有限。
1. 用户感知的存储空间低
- 由于成本限制,智能手机通常是资源稀缺的。同时,
Android 操作系统所占用的空间也在不断增加。与此同时,Android 应用的存储消耗也在不断增长,因此,可供用户使用的低端智能手机的存储容量相当小。此外,许多智能手机的顶级应用往往会消耗大量内存,即使在高端智能手机上,也只留下少量内存用于系统启动操作。
2. 系统设计目的与应用现实相悖
- 只读文件系统的设计目的是尽量减少存储的使用。然而,利用现有的压缩读取只有资源稀缺的智能手机上的文件系统才会导致性能和内存消耗方面的巨大开销,因此,长此以往,国将不国。
3. 旧方案局限性
· Btrfs
- Btrfs 是一个通用的文件系统,因此其内部结构必须考虑有效的数据修改,
不能为了压缩而进行积极的优化。此外,压缩并不是唯一的衡量标准。解压过程中的内存消耗受到限制。 对于像智能手机这样的设备来说,性能和响应能力是不可动摇的重要关键指标。因此,随着高效数据修改的负担,Btrfs 很难同时满足性能和压缩效率的要求。
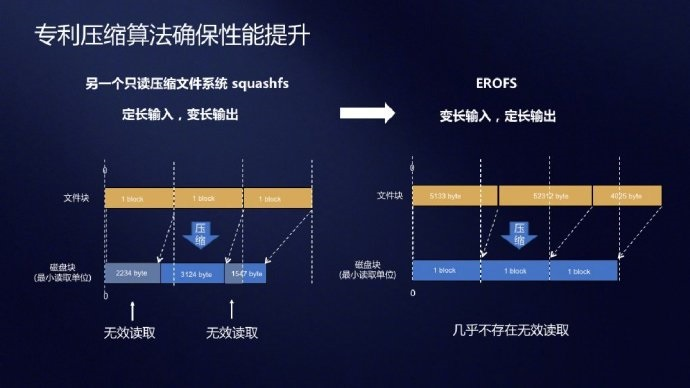
· Squashfs
固定大小的输入压缩
- 现有的文件系统在固定大小的块中压缩原始数据,生成大小可变的压缩数据。
- 这会造成巨大的I/O放大与计算浪费,即使压缩块的数量非常大,文件系统必须读取所有相关的压缩块。同时,对无用数据的解压过程也会造成巨大的 CPU 浪费,从而导致其他正在运行的高性能干扰。
大量的内存消耗和数据移动。
- 在文件读取请求时,Squashfs 会首先查找元数据,得到相关压缩块的数量。 因此,在解压过程中Squashfs 需要大量的临时内存。
新方案 EROFS(增强压缩文件系统)
- Android 基于 Kernel 开发而来,因此一直使用 Linux 的标准文件系统 ext4,但 ext4 的存储镜像结构不能很好地适用于手机闪存。2016 年,华为曾推出优化后的 F2FS(Flash-Friendly File System)文件系统,在用户分区上替代了传统的 ext4,提升了文件读写的流畅度,但运行操作系统只读文件的系统分区并未做改变。为了解决此问题,2018 年,华为进一步推出了自研的 EROFS(Enhanced Read-Only File System),其采用了优化改造的固定输出大小 lz4 压缩算法,首次应用于 EMUI9.1,让设备性能取得了很大程度地提升。而最近,Android 13 原生也宣布跟进。
- 很自然,HarmonyOS 与 OpenHarmony 中也都有着它的身影:
特性
-
利用固定大小的输出压缩。
将文件数据压缩到多个固定大小的块,以显著缓解读放大问题,并尽可能减少不必要的计算。
-
内存高效的解压缩,在很少额外内存开销的情况下实现高性能。
通过利用压缩算法(如 LZ4)的特点,EROFS 设计了不同的内存高效解压缩方案,以减少解压缩过程中额外的内存使用。
-
EROFS 还采用了一套精心确保有保障的用户体验的优化方案。
详解:
1. 固定大小的输出压缩
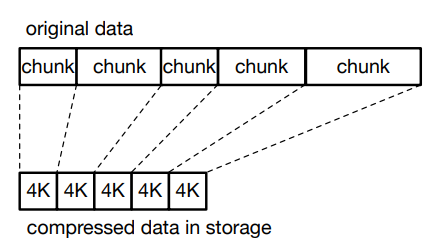
- 原因:为了克服固定大小的输入压缩带来的读放大,EROFS 采用了一种不同的压缩方法:固定大小的输出压缩
- 实现方法:固定大小的滑动窗口
- 流程:压缩算法会被多次调用,直到所有文件数据都被压缩。
- 例如,对于 1MB 的滑动窗口,EROFS 每次向压缩算法提供 1MB 的原始数据。然后算法尽可能地压缩原始数据,直到所有 1MB 的数据都被消耗掉,或者被消耗的数据可以恰好生成 4KB 的压缩数据。(最小的请求底层存储设备的大小是 4KB)剩余的原始数据与更多的数据结合,形成另一个 1MB 的原始数据,用于下一次调用压缩。
- 压缩比:因为固定大小的输出压缩可以尽可能地压缩数据,直到达到输出限制,而固定大小的输入压缩一次只能压缩固定大小的数据。
- 在解压缩过程中,只有包含请求数据的压缩块才会被读取和处理。请求单个原始块时,最多会读取和解压缩两个压缩块。
- 后定大小的输出压缩使得就地解压成为可能,这进一步减少了 EROFS 中的内存消耗。
2. 缓存 I/O 和就地 I/O(I/O——输入/输出)
- 出发点:在实际解压之前,EROFS 需要空间来存储从存储中检索到的压缩数据。每个压缩只检索最多两个压缩块。
- 策略:
- 缓存I/O(部分分解数据块)
- EROFS 管理一个特殊的
索引节点,其页缓存存储按物理块序号索引的压缩块。因此,对于缓存的 I/O, EROFS 会在特殊的 inode 的页面缓存中分配一个页面来发起I/O(输入/输出)请求, 这样压缩的数据就会被存储驱动直接取到分配的页面 。
- Tips:
- 页缓存:
由于读写硬盘的速度比读写内存要慢很多。为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核会以页大小(4KB) 为单位,将文件划分为多数据块,当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为页缓存)与文件中的数据块进行缓存。
- inode:
inode 存储了文件系统对象的一些元信息,对应的文件系统存储块的地址等,知道了 1 个文件的 inode 号码,就可以在 inode 元数据中查出文件内容数据的存储地址。
- 就地 I/O(完全分解的压缩块)
- 在每次读取文件时,
VFS(虚拟文件系统) 会在页面缓存中,为文件系统分配页面,来存放文件数据。对于这些在解压前不包含有意义数据的页面中的任何一个,被称为可重用页面。对于就地 I/O,EROFS 会使用最后一个可重用页面,来初始化 I/O 请求。
- Tips:VFS(虚拟文件系统):
允许操作系统使用不同的文件系统实现的接口。
3. 解压
以单个块为例
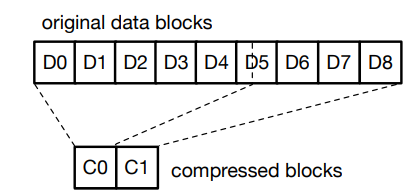
前 5 个块(D0 到 D4)和部分块 D5 被压缩为块 C0,其余块被压缩为块 C1。
下面将介绍三种解压缩方式:
Vmap 解压
解压缩为了获得块 D3 和 D4 中的数据,EROFS 首先从存储器中读取压缩后的块 C0,并将其存储在内存中。然后 EROFS 会按照以下步骤进行解压。
- 找到存储在压缩块(C0)中的所需的块的最大编码,也就是示例中的第五个块(D4)。EROFS 只需要解压前 5 个块(D0 到 D4),而不是解压所有原始数据块。
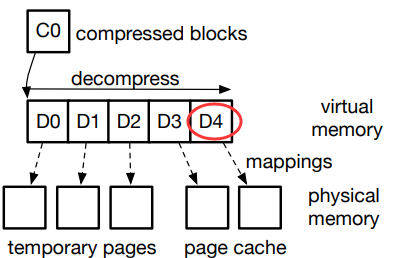
- 对于每一个需要被分解的数据块,找到存储空间来存储它们。在图例中,EROFS 分配了 3 个 临时物理页面来存储 D0、D1 和 D2。对于请求的两个块 D3 和 D4, EROFS 在页面缓存中重用了 VFS 已经分配的两个物理页面。
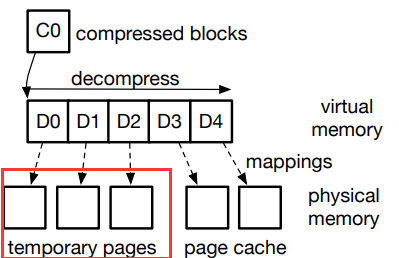
- 由于解压缩算法需要
连续内存作为解压缩的目的地, EROFS 通过 vmap 接口将上一步准备好的物理页面映射到连续虚拟内存区域。
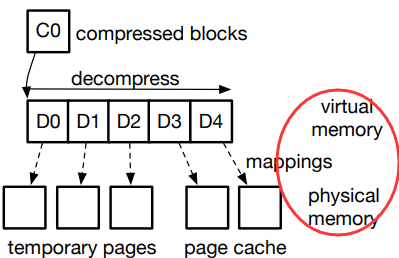
- 如果是就地 I/O,在这种情况下,压缩块(C0)存储在
页面缓存页面中,EROFS 还需要将压缩数据(C0)复制到 一个临时的pre——CPU 页面(下一个方案中会介绍),这样解压后的数据不会在解压过程中覆盖被压缩的数据。
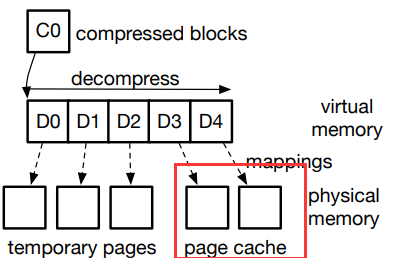
- 最后调用解压缩算法,将压缩块中的数据提取到连续存储区。压缩后,三个临时物理页面和虚拟内存区域都可以回收,请求的数据已经被写入相应的页面缓存页面。
现存问题:
需要动态分配物理内存页,这增加了内存受限设备的内存压力。
使用 vmap 和 vunmap 在每次解压时效率都很低。
针对动态分配内存问题有以下两种优化方案
Per-CPU buffer 解压
EROFS 利用 percpu 缓冲区来缓解解压后的数据少于 4 页时的问题。
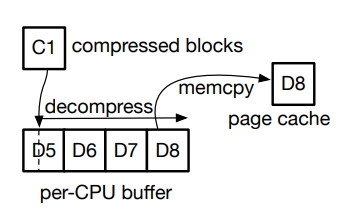
1.一个四页的内存缓冲区被预先分配给每个 CPU 作为每 CPU 缓冲区,对于提取不超过 4 个数据块的解压缩,EROFS 将数据解压缩到 per-cpu 缓冲区。
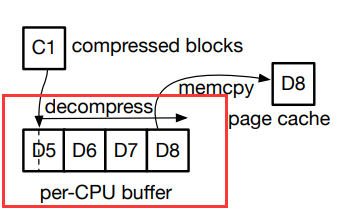
D8 中的数据被请求,C1 中的压缩数据 直接解压缩到 per-cpu 缓冲区。
- 然后将请求的数据复制到页缓存页面。
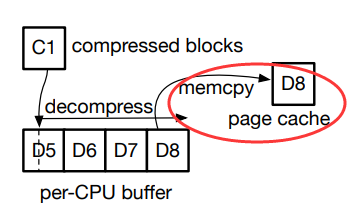
D8 的内容通过 memcpy 复 制到页面缓存页面。
优势:
- per-CPU 缓冲区的长度是由经验决定的,根据此固定长度来提取数据进行缓存;同时,per-CPU 缓冲区可以在不同的解压缩过程中重用,综上可以有效地消除
vmap 的动态内存分配问题。
- pre-cpu 缓冲区解压缩是一种成本效益的权衡,它缓解了 vmap 解压缩中的问题,同时引入了额外的内存副本。
滚动解压
原理:
- EROFS 分配了一个很大的虚拟内存区域以及为每个 CPU 分配 16 个物理页面。 每次压缩前,EROFS 都会使用这 16 个物理页,连同页面缓存的物理页一起填充 VM (虚拟)区域。
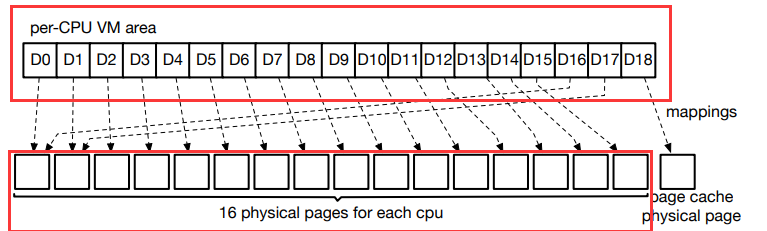
- Tips:
- EROFS 使用 LZ4 作为压缩算法,需要向后看解压后不超过 64KB 的数据。因此,对于一个提取超过 16 页的压缩,EROFS 可以重用映射 16 个虚拟页的物理页(即 64 kb)。
实现滚动
- 在图中,用于存储 D0 到 D15 块的虚拟地址由 16 个物理页面支持。
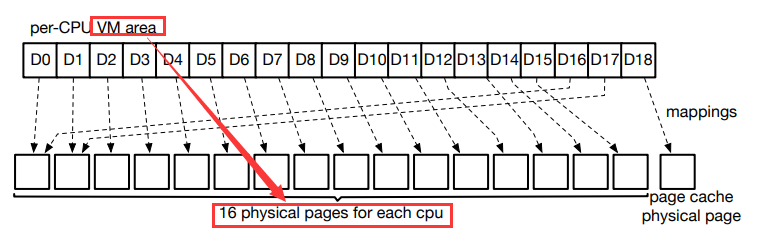
- 由于 D16 中的每个虚拟地址与 D0 中对应的地址之间的距离是 16个物理页面,便开始新一轮滚动。
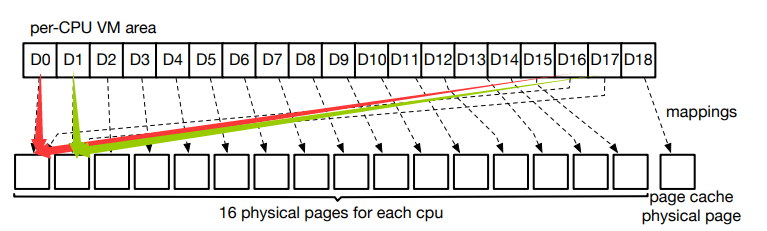
- 因此 D16 的虚拟页可以由与 D0 相同的物理页来支持,D17 通过 D1 使用的物理页以同样的方式进行支持。
- D18 是被读取的文件请求的,使用的是页面缓存的物理页。
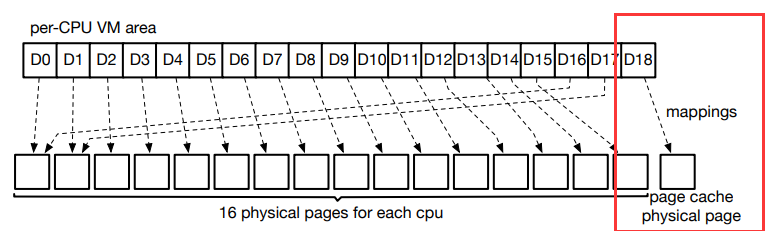
- 综上,通过使用这样的滚动解压缩16个物理页面就足够处理任何解压缩情况了。到目前为止,我们已经初步了解到:EROFS 选用 4k 作为固定输出大小的原因是 —— 4k 是页面管理和存储数据的最小单位,可有效避免 I/O 的放大;选用 lz4 作为压缩算法是看中了它极快的解压速度与良好的压缩比;只有文件数据在 EROFS 中会被压缩,inode 与目录条目等一类的元数据则保持原样。
- 操作系统的文件除了包含文件数据本身,还附加着许多权限与属性。权限与属性放在 inode,实际数据放在数据区块。毫无疑问,数据区块记录着文件的实际内容。而 inode 除了记录文件的扩展属性,还同时记录着对应数据区块所在的号码,并且一个文件会占用一个 inode。超级区块记录了整个文件系统的整体信息,包括 inode 与数据区块的总量、使用量、剩余量以及文件系统的格式与相关信息等。
结构布局
- 与诸多文件系统类似,EROFS 也是有一个
超级区块位于整个结构的前端。在其之后,元数据与实际数据可以按顺序存储也可以以混合形式进行存储。
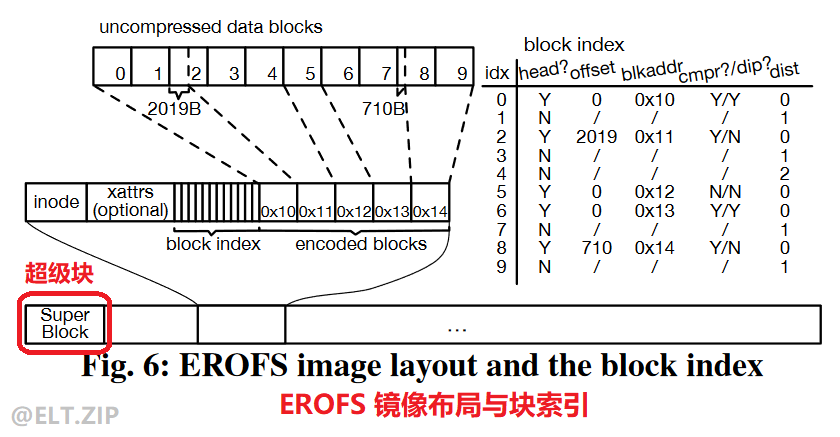
- 如图所示,超级块后方的每一个小块即对应一个文件。对其展开,可以看到开头存储着 inode,紧接着是 xattrs 扩展属性与块索引,最后,表示压缩或未压缩文件数据的编码块存储在每个文件的末尾。块索引用于快速定位读请求的相应编码块,它是一个包含 8 个字节长度条目的数组,每个条目分别对应一个压缩前的数据块,同时指示这个数据块是否为头块( head? ),以用于开始一个新的编码块。如果是头块,则还将存储编码块的地址( blkaddr? )、新编码块中第一个字节的偏移量( offset? )、编码块是否已被压缩( cmpr? )与这个块是否可以被就地解压( dip? );如果不是头块,则必须在未压缩块之前设法确定一个头块,未压缩块与头块的数量差异被记录在 dist 中。
- 整体的结构布局现在差不多已经准备好了,那当我们需要使用这些数据时,EROFS 是怎样进行操作的呢?
- 首先,对于未压缩数据块的读取请求,EROFS 将根据所请求的块号获取块索引的条目。其次,如果是对于头块,EROFS 将从 blkaddr 处解压编码块的数据,若偏移量非零,可能需要从 blkaddr 之前存储的最近的编码块开始解压。另外,对于非头块,EROFS 依据存储的 dist 值反推回对应头块的位置,从头块对应的 blkaddr 处开始解压,直至所请求的块的数据被完全解压。有些数据块在压缩后仍然较大,因此大多考虑不将它们压缩,而是直接以编码块的形式进行存储,避免耗费过多的时间空间成本。以上情况,具体体现在块索引中 cmpr 字段值被设置为 N(false) 的条目。
技术优化方案
1. 索引内存优化
EROFS 可以将数百页的原始数据压缩成仅一个压缩块,但这种情况下,将需要数百个指针去跟踪那些原始数据应当被存储的页面,可能会导致消耗大量内存。为此,EROFS 会尝试使用可重用的页面来存储这些信息。如果有多个 VFS 分配的页面可被重用,便选取最后一页存储压缩数据,剩余页面的指针则会被移动到堆栈上。
2. 调度优化
在像 Btrfs 这样的文件系统中,当压缩数据被读进内存时,会唤醒一个专用线程来解压数据。而解压完成后,用来实现 I/O 的读取器线程才会被唤醒,以从页面缓存中获取被解压完的数据。因此,这种互相之间的调度开销不可忽视。于是,EROFS 采取了全过程都使用读取器线程的策略。
3. 队列解压缩算法
可以同时发出多个请求进行解压缩。当线程 A 请求的数据正在被线程 B 所解压时,线程 A 无需自己再重新解压一遍,可以直接从页面缓存中复用已被线程 B 解压出的数据,从而实现合作重复使用解压缩数据,防止单个数据被多次解压。
4. 镜像修补
尽管 EROFS 压缩的是只读分区,但其中的数据在系统更新等操作时可能仍会变动。即便只简单修改文件数据中的个别几个位,其他大量相关分散数据也可能需要一并被修改,这会致使整个分区的重新压缩。EROFS 提供了可以放在其镜像末端的镜像补丁,免除对已压缩只读分区的修改,而是在原始数据解压完成后应用补丁予以更新修补。
场景性能表现
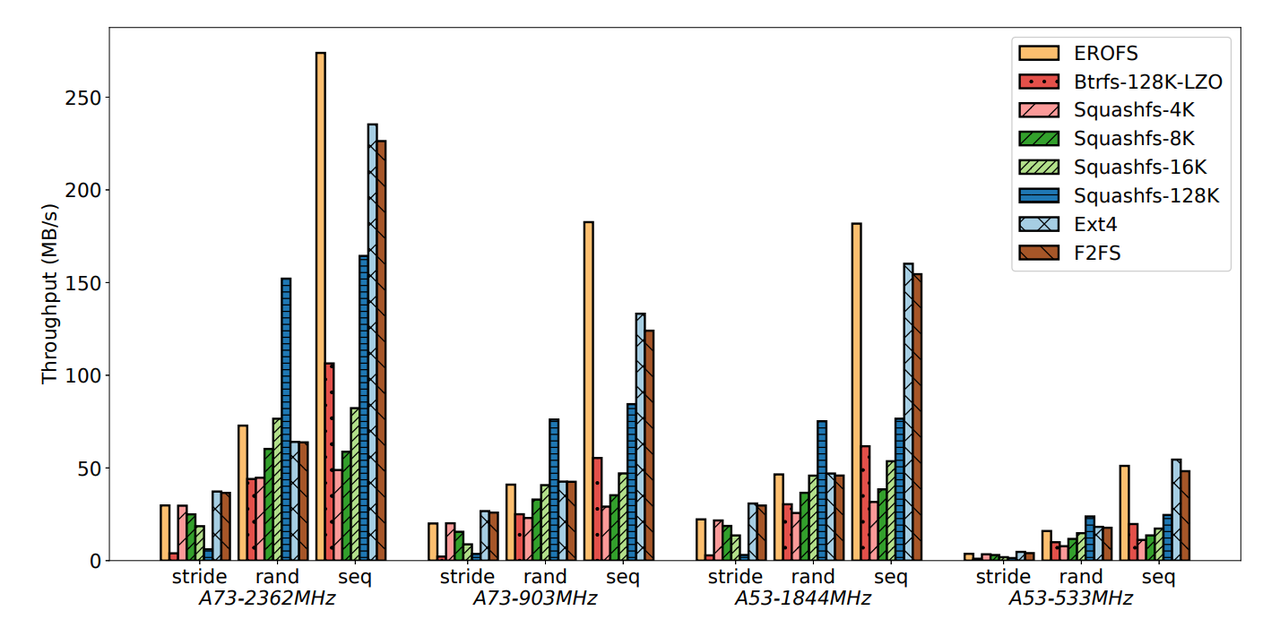
1. 压缩比与内存占用
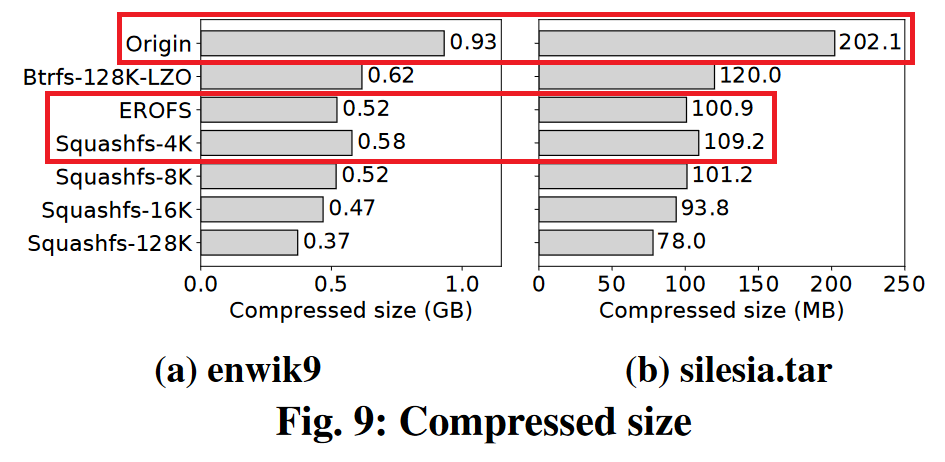
- 使用大小分别为 953.67MB、202.1MB 的 enwik9 与 silesia.tar 作为数据集进行压缩比的测试,结果如下图。可以看到,与 4K 大小输入的 Squashfs 相比,4K 大小输出的 EROFS 的压缩比要优了 10% 和 9%。
- 下图显示了解压缩 enwik9 时所占用的内存量:

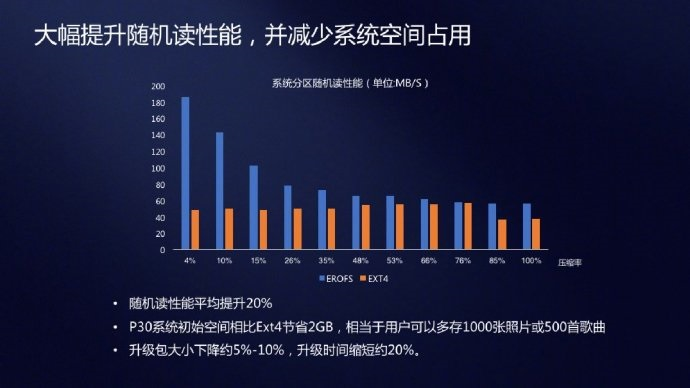
2. 吞吐量与存储空间量
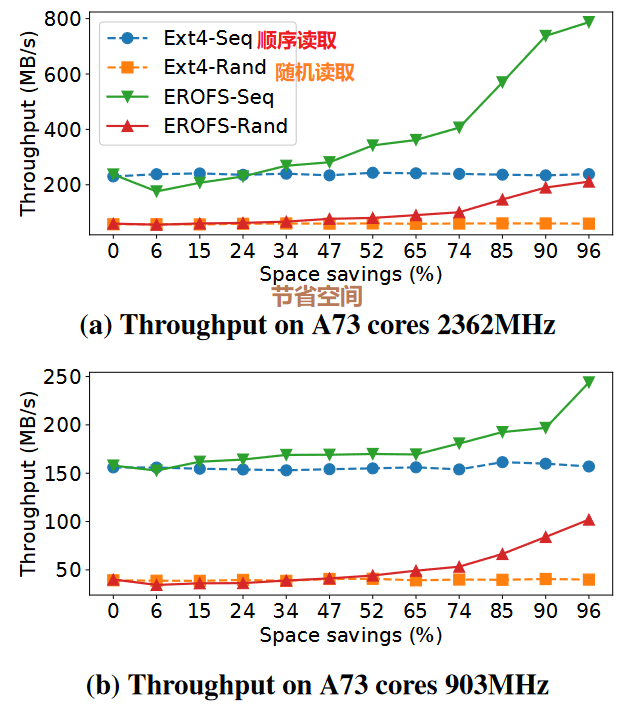
- 上图描述的是 EROFS 和 ext4 在不同条件下吞吐量与存储空间量节省的表现。常规情况下,ext4 的吞吐量保持得较稳定;EROFS 的性能则是边增加边节省空间,整体逐步攀升,当节省空间量足够高时,实现了非常好的吞吐量。当节省空间量较低时,EROFS 对于随机读取的性能类似于 ext4,而对顺序读取的性能相较 ext4 较差。
3. 应用程序启动时间
- 研发人员对多款应用程序的启动时间做了测试评估,结果表明,与 ext4 相比,EROFS 平均将低端手机的 app 启动时间缩短了 5%,高端手机缩短了 2.3%。举其中一项相机 app 为例:
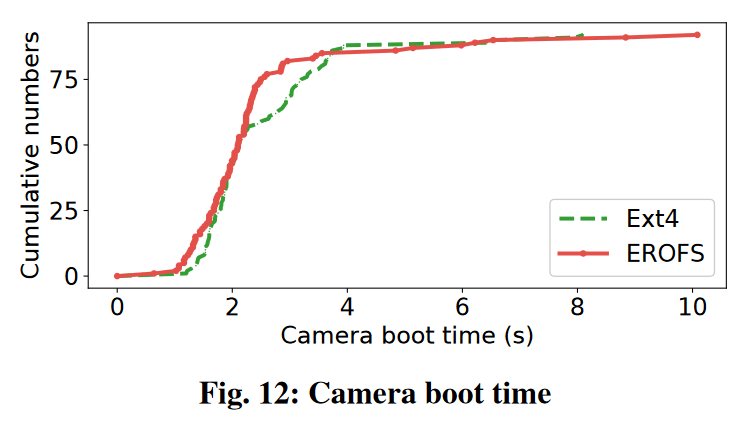
在 90% 以上的启动状态下,EROFS 都优于 ext4,只有偶然会出现非常长的启动时间。
参考文献
[1] Gao X, Dong M, Miao X, et al. {EROFS}: A Compression-friendly Readonly File System for Resource-scarce Devices[C]//2019 USENIX Annual Technical Conference (USENIX ATC 19). 2019: 149-162.
参考会议
[1] USENIX
[2] IEEE Xplore, delivering full text access to the world's highest quality technical literature in engi
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 4291
4291

























 淘帖
淘帖 显身卡
显身卡




