- 本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
- 成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
- 黑龙江大学大一在校生
- 华南理工大学大一在校生
- 我们是来自
6个地方的同学,我们在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究操作系统技术…
@[toc]
【往期回顾】
① 2月23日 《老子到此一游系列》之 老子为什么是老子 —— ++综述视角解读压缩编码++
② 3月11日 《老子到此一游系列》之 老子带你看懂这些风景 —— ++多维探秘通用无损压缩++
③ 3月25日 《老子到此一游系列》之 老子见证的沧海桑田 —— ++轻翻那些永垂不朽的诗篇++
④ 4月4日 《老子到此一游系列》之 老子游玩了一条河 —— ++细数生活中的压缩点滴++
⑤ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——一文穿透多媒体过往前沿++
⑥ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——这些小风景你不应该错过++
⑦ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——浅析稀疏表示医学图像++
⑧ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——计算机视觉数据压缩应用++
⑨ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——点燃主缓存压缩技术火花++
⑩ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——即刻征服3D网格压缩编码++
⑪ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——云计算数据压缩方案++
⑫ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——大数据框架性能优化系统++
⑬ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——物联网摇摆门趋势算法++
【本期看点】
HCompress在多层存储环境中大放光彩揭秘消费类电子设备软件更新压缩算法AIMCS如何压缩短字符串
【技术DNA】
【智慧场景】
| ********** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
| 场景 |
自动驾驶 / AR |
语音信号 |
流视频 |
GPU 渲染 |
科学、云计算 |
内存缩减 |
科学应用 |
医学图像 |
数据库服务器 |
人工智能图像 |
文本传输 |
GAN媒体压缩 |
图像压缩 |
文件同步 |
| 技术 |
点云压缩 |
稀疏快速傅里叶变换 |
有损视频压缩 |
网格压缩 |
动态选择压缩算法框架 |
无损压缩 |
分层数据压缩 |
医学图像压缩 |
无损通用压缩 |
人工智能图像压缩 |
短字符串压缩 |
GAN 压缩的在线多粒度蒸馏 |
图像压缩 |
文件传输压缩 |
| 开源项目 |
Draco / 基于深度学习算法/PCL/OctNet |
SFFT |
AV1 / H.266编码 / H.266解码/VP9 |
MeshOpt / Draco |
Ares |
LZ4 |
HCompress |
DICOM |
Brotli |
RAISR |
AIMCS |
OMGD |
OpenJPEG |
rsync |
引言
- 现代诸如科学应用程序这类的数据密集型计算应用,在执行 I/O 上耗费了大量时间。尽管有着高性能计算(HPC)的解决方案(它的底层数据由存储在基于磁盘的并行文件系统(PFS)的文件表示),但 CPU 和 RAM 的速率却早已远超了 HPC 的存储能力,于是这就产生了不对等性,从而造成了 I/O 瓶颈。
- 那么,奔着解决此项瓶颈的目的,我们可以采取引入中间件的方式,比如像
数据缓存、数据预取、数据聚合这类数据访问优化措施,将 I/O 消耗转移至一个中间的临时空间(主存、缓冲区、SSD等)中;此外,还可以在系统架构中包含中间的、专门的资源,例如 I/O 转发器、突发缓冲区以及更接近计算节点的数据暂存节点。最后,使用多种数据缩减优化操作,压缩是其中一项。关键点是,以上所有解决方案的有效与否均取决于中间临时存储(ITS)的可用空间量和利用率。ITS 的容量越大,越有助于避免我们上述的 I/O 瓶颈。
- 在将数据存储到磁盘或是从磁盘检索到数据之前,用 CPU 周期对数据进行压缩或者解压缩,从而减少数据占用,缩短 I/O(计算机接口)时间。一些解决方案可能会草率地将相同的压缩应用于所有层,这将导致错过优化机会,因为每个层可能受益于不同的压缩算法。如果有效地利用了数据压缩,它将提高各层的总体容量,从而提高 I/O 优化的有效性。
- 在程序将运行时,用大部分时间用于执行数据在内部存储器和外部存储器或其他周边设备之间的输入和输出,并不能有效地利用数据压缩。就像一个人投篮很厉害,但他运球和传球做的并不好,总是会脱手或被截断,无疑在此浪费大多时间。最大化 ITS 空间的资源和容量利用率比以往任何时候都更加迫切。
- 故为了最大化 ITS 空间量和利用率,大体有两种正交的方式:第一是增设新的硬件,第二是减少重定向到 ITS 的数据量。增设新硬件比较直接也很好理解,比如说
高带宽内存(HBM)、非易失性RAM(NVRAM)和固态硬盘(SSD)等,将它们组织在一个多层存储层次中(更高层次速度更快,但容量更小);减少数据量最常用的是数据压缩,在合适的场景和环境下匹配对应的压缩技术是尤其需要关注的。自然而然地,我们就会联想到:如果二者同时进行,不就可以相互受益了吗? 愿望总是美好的,然而现实情况是,现有的软件要么不压缩就直接将数据放在各个层中,要么就是天真地将相同的压缩应用于所有层(很早之前我们提到过,压缩如果应用不当,最终结果相比原始可能反而会变大)。于是,相关学者设计并实现了 HCompress,它是一个分层数据压缩引擎,可协调利用多层存储和数据压缩来提高应用程序性能,下面我们即对其展开研究。
应用
Hcompress是图像压缩包,用于太空望远镜科学研究所。Hcompress用于压缩STScI数字化巡天并且还用于压缩哈勃数据档案。该技术为天文图像提供了非常好的压缩,并且速度很快,在压缩或解压缩512x512图像需要大约1秒。可以压缩2字节整数图像,采用少量输入格式。

正式应用前的铺垫
VPIC 仿真测验
- 矢量粒子单元(VPIC) 是一个用于在多维空间中建模动力学等离子体的通用仿真代码,简单来说,我们可以通过观察它的不同表现来验证多层存储和压缩的参与效果,同时为后续的实验猜想提供参考。

- 这里在上期所述的Ares集群框架的基础上使用 Hermes 库执行分层缓冲,测试结果如下,x 轴是不同的配置,y 轴以秒为单位,次级 y2 轴显示了压缩比:
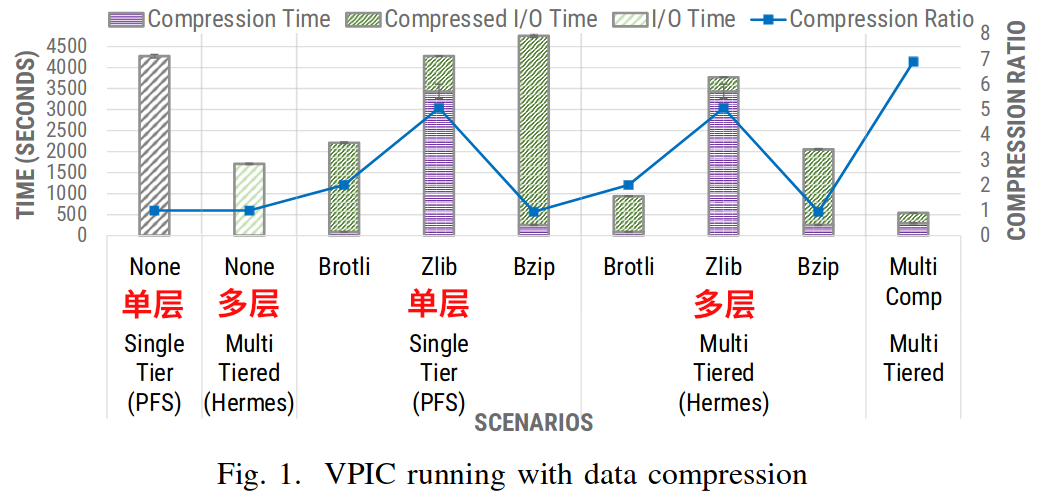
- 结果显示,在没有多层缓冲和压缩的情况下,VPIC 需要 4270 秒才能完成;而当启用
多层缓冲(即 Hermes)时,VPIC 的运行时间相比作为基线的 PFS 优化了 2.5 倍,当启用压缩时,我们可以看到显著的性能变化,尤以 Google Brotil 效果最优,减少了 1.93 倍的耗费时间,实现了 2 倍的压缩比,但却只花费了 90 秒的压缩时间,相比动辄几千秒的总时间,可以说是微不足道了。而使用 Zlib 时,压缩的优势被延长的压缩时间所抵消,实现了 5 倍的压缩比,但花费了 3431 秒的总时间。若使用 Bzip 就属于不适当的一类,VPIC 的数据类型不能被其压缩。
多层次的优点
- 多层层次可以受益于额外的容量。将压缩库与分层存储达到最优匹配。多层解决方案的性能取决于它们将更多数据放在上层的能力,能提供更低的延迟和更高的带宽。数据压缩不是为多层存储量身定制的,压缩或解压通常受益于
压缩时间与减少 I/O 时间之间的平衡。分层的数据压缩库,可以通过和谐地利用多层存储和数据压缩来提高应用程序的性能。
- 而 HCompress 便旨在通过将多层系统与数据压缩智能结合,从而提高 ITS 的利用率。
HCompress 直击痛点
- HCompress(开源地址:scs-io / hcompress — Bitbucket) 是一个数据压缩引擎,它利用存储层次的多层特性整体优化 I/O 操作来提高程序性能,思想灵感即来源于我们之前所述的 VPIC 仿真过程,核心之处就在于它实现并采用了一种
智能的、层次感知的压缩与数据放置算法(HCDP)。HCompress 使用了一个输入数据分析器、一个可以访问压缩库语料库的压缩管理器、一个系统监视器、一个压缩性能预测器和一个 HCDP 选择引擎。总结一下,HCompress 的优势可以概括为以下三点:
- 层次感知:基于不同层性能特点,为每层选择适当的压缩算法,物尽其用
- 动态:以可忽略的成本动态选择压缩库,并透明地出于程序的各种需求重新配置自己
- 灵活:统一了所有压缩库的接口,可在一个通用平台进行交互,且允许添加新的库
设计架构
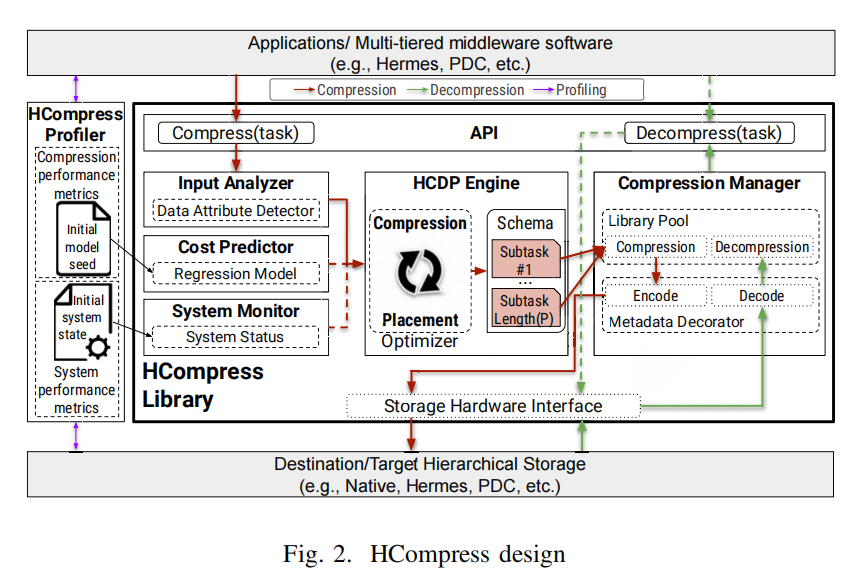
- 上图给出了 HCompress 的系统结构,包括主库和一个外部分析工具。程序可以使用这些库(
libhcompress.so)来链接并调用其原生 API (compress() / decompress())。在红色箭头所指出的压缩流程下,程序使用 HCompress 库 API,然后将相关数据传递给输入分析器(IA)进行分析,输入分析器可以识别数据属性,即数据类型、数据分布和表示格式。压缩成本预测器(CCP)则为上述属性的每个组合维护一个预期的压缩成本表。系统监视器(SM)监视当前的系统状态,即可用层和它们各自的剩余容量。HCDP 引擎最后基于以上我们列出的三项标准,也就是数据属性、预测成本、系统状态,计算出最佳压缩和放置模式。压缩管理器(CM)和存储硬件接口(SHI)负责相互协调,根据已指定的压缩模式使用相应元数据对原始数据进行编码,实现压缩与还原的过程。
分级压缩和数据放置引擎 HCDP
- HCDP 是 HCompress 的大脑,负责为传入的 I/O 任务设计压缩和防止模式。
HCDP 算法
- 当接收到一个任务时,引擎会递归地匹配并放置目标层的所有组合数据和压缩库。算法逻辑如下:
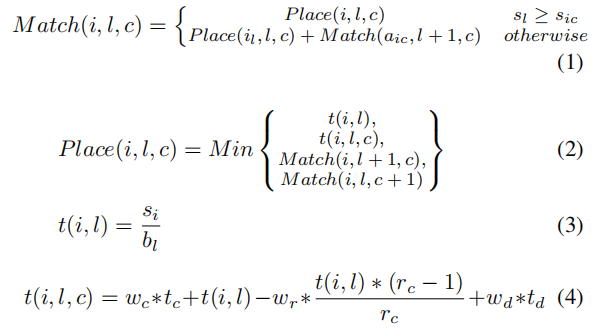
压缩管理器 CM
CM 负责管理几个压缩库的接口,它将几个 API 统一在一个通用接口下,再用丰富的元数据修饰压缩数据。
统一压缩库
在 HCompress 中,压缩库的统一由压缩库池(CLP)完成,CLP 包含三个主要部分:
- 压缩库接口:定义了一组虚拟函数,将压缩库的功能与通用签名封装在一起。
- 压缩库实现
- 压缩库工厂:根据给定的输入选择特定的实现,原生包含这些压缩库:
bzip2、zlib、huffman、brotil、lzma、lz4、lzo、pithy、snappy 和 quicklz.
- 工厂是调用者实例化实现的唯一地方,这使得 CLP 可以轻松地动态调用新库,而无需更改调用者的现有代码,复杂度为 O(1),可以说是十分理想了。
HCDP 算法元数据
- 由于
HCDP 引擎可以为不同的输入数据和存储层选择不同的压缩库,因此 HCompress 需要维护应用的压缩库、如何应用它(即输入缓冲区的偏移量)以及未压缩数据的原始大小。
数据压缩对多层存储的影响
- 应用HCompress减少了写入每一层的数据量,从而减少了总体执行时间。
NVMe(非易失性内存主机控制器接口规范)的原理,它本质是上建立了多个计算机与存储设备的通路。在NVMe协议中,多个通路其实就是多个队列来提升转运数据的数量,NVM 感知缓冲区管理器和存储系统设计器提高了系统吞吐量并降低了跨不同事务和分析处理工作负载的系统成本。条条大路通罗马,但如果可以,你一定不会选择和千军万马过独木桥。而HCompress方案,用更少的NVMe,较少的内存占用,减少了大量总执行时间, 有显著的性能提升,与没有压缩的库相比,最高可提高 8 倍,与其他压缩库相比,至少提高 1.72 倍。
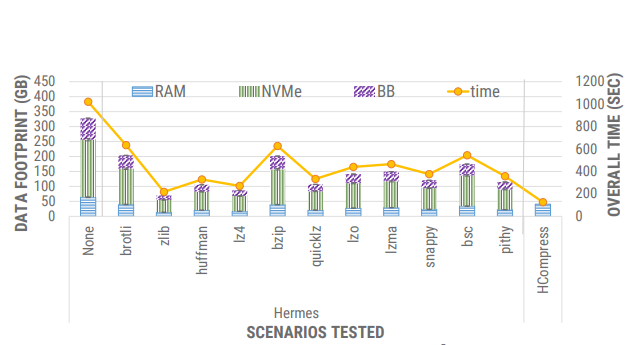
多层存储对数据压缩的影响
- 来自于压缩时间与 I/O 的减少之间的平衡。不同层和不同库之间存在显著的吞吐量变化由图可见。HCompress 利用了将不同的库,映射到不同的层来识别潜在的潜在性能这一点,并为每一层使用最好的库,从而获得更高的吞吐量。与应用于多层存储的其他压缩库相比,HCompress的吞吐量提高了 1.4-3 倍。
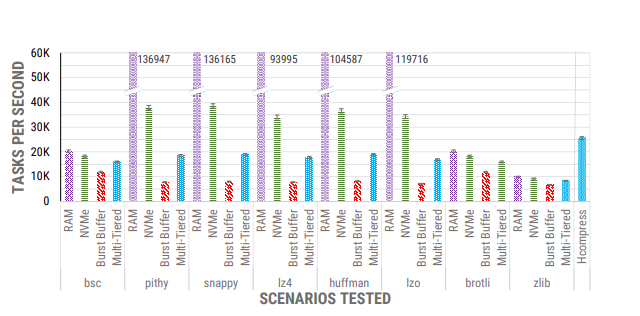
总结
- 为了增加 ITS 的空间,多层存储在存储层次结构中增加了额外的层,而压缩的目的是最小化数据占用。但是它们相互正交、不能共存,为此,提出了 HCompress,它是一个适用于多层存储环境的分层数据压缩引擎。经过验证,HCompress 可以显著提高科学应用和工作流程上的 I/O 性能。 具体数字上来看就是,应用 HCompress 的 I/O 速率 相比 PFS 的基线版本快了 12 倍,比其他优化方案又快了 7 倍。因此,有着十分的前途。
参考文献
[1] Devarajan H, Kougkas A, Logan L, et al. Hcompress: Hierarchical data compression for multi-tiered storage environments[C]//2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2020: 557-566.
[2] S. Byna, J. Chou, O. Rubel, H. Karimabadi, W. S. Daughter et al., “Parallel I/O, analysis, and visualization of a trillion particle simulation,” in Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE, 2012, pp. 1–12.
[3] H5hut (HDF5 Utility Toolkit).
[4]Lee J Y, Kim T H, Ko S J. Motion prediction based on temporal layering for layered video coding[J]. Memory, 1998, 1000: 1.
[5]Arulraj J, Pavlo A, Malladi K T. Multi-tier buffer management and storage system design for non-volatile memory[J]. arXiv preprint arXiv:1901.10938, 2019.
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 4213
4213




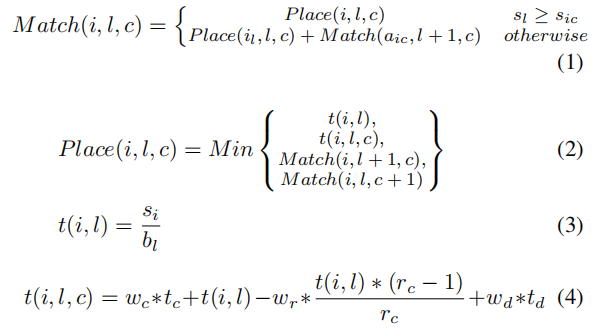


 淘帖
淘帖 显身卡
显身卡




