[文章]【学习打卡】【ELT.ZIP】OpenHarmony啃论文俱乐部——综述视角解读压缩编码

-
本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。 -
成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
-
我们是来自4个地方的同学,我们在
OpenHarmony成长计划啃论文俱乐部里,通过啃论文方式学习操作系统技术...
@[TOC]
入门指北
- 压缩编码概览
- 我从来不理解 “压缩算法”,直到有人这样向我解释它

有趣玩件
轻松上手
- 《 伟大的计算原理 》


正式开始之初,我们便很轻易地从欧sir推荐的书目《 伟大的计算原理 》中获得了“ 文件压缩 ”的相关信息,通俗地阐述了各类不同压缩方法的简单实现原理,非常适合于作为对初学者的引入。
《 A Survey On Data Compression Techniques: From The Perspective Of Data Quality, Coding Schemes, Data Type And Applications 》
《 数据压缩技术调查:从数据质量、编码方案、数据类型和应用的角度 》

- Analysis
从标题可知,这是一篇从数据质量、编码方案、数据类型和应用角度解读数据压缩技术的综述。
摘要部分是通常性的对文章发表背景及目的的叙述:++“ 数字世界中数据的爆炸性增长导致了需要高效的技术来存储和传输数据。由于资源有限,数据压缩(DC)技术被提出,以最小化被存储或通信的数据的大小。由于DC概念能够有效利用可用存储区域和通信带宽,因此在几个方面发展了许多方法。为了分析DC技术及其应用程序是如何发展的,我们对许多现有的DC技术进行了详细的调查,以满足目前在数据质量、编码方案、数据类型和应用程序方面的要求。还进行了比较分析,以确定所审查的技术在其特征、基本概念、实验因素和局限性方面的贡献。最后,本文深入探讨各种开放问题和研究方向,探索未来发展的前景。”++
从简单的一段摘要中,我们轻松获得了文章即将涵盖的技术领域,给读者提供了合适的技术背景铺垫,明确了定义:数据压缩技术是为了最小化数据大小来应对不断爆炸性增长的数据的存储传输。 - 接下来,是文章的目录结构:


目录是对一篇文章整体框架的梳理,便于读者掌握文章组织安排方式和迅速找到想发掘的点。


进入正文,首先,介绍部分不光是对开头摘要内容的拓展延伸,更多的是声明了后文中即将出现的专业概念词汇,强调基本的领域知识储备,避免读者在后续遇到困难。由于入门指北已经奠定了一定基础,文字内容可以简单浏览了解;图表部分则具有很大价值,初学者很大程度上分辨不清各相关概念之间的区别与联系,而图表则提供了良好的解决方案,如:


第一张图就以文章标题所述的方式对不同压缩技术按照相应类别进行了分类,因此后文会以这样的编排方式进行解读:
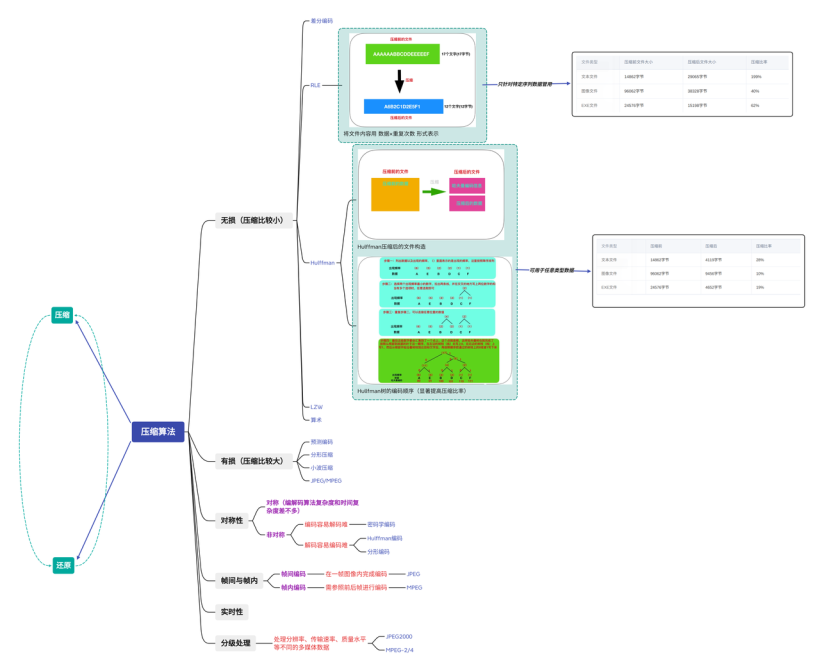
- 从数据质量上大体分为无损压缩和有损压缩
- 从编码方案上可分为常用的哈夫曼编码、算数编码、字典编码(如LZ系列)、游程编码(RLE)等
- 按数据类型便是文本(LZMA)、图像(JPEG)、音频(MP3)、视频(H.264)
- 应用方向上又可分为无线传感网络、医学影像、其他等特殊应用
第二张表从多方面比较了不同压缩技术的特点,详见其中。
纵览全文,通用衡量各压缩技术性能使用的主要是\color{#f00}{Compression Ratio(CR)、Peak Signal to Noise Ratio(PSNR)}两项指标,即压缩比和峰值信噪比,这是一个重点。压缩比比较好理解,就是数据压缩后的大小比上压缩前的大小,所以理论上压缩比越小,某种压缩算法一定程度上越占优势;那什么是峰值信噪比呢?这个概念从简单的字面意思上也能有个大致的感觉,我们不妨去搜索一下,在百度百科中得到了官方的定义:“ ++峰值信噪比是一个表示信号最大可能功率和影响它的表示精度的破坏性噪声功率的比值的工程术语。由于许多信号都有非常宽的动态范围,峰值信噪比常用对数分贝单位来表示。++” 什么意思呢?其实这里的“噪声”既非指日常生活中的“噪声”也非指物理学上的“噪声”,结合信息学或前文《 伟大的计算原理 》中的相关内容,我们得到以下理论:++噪声是通信模型中的一个重要元素。任何在传输通道中改变信号,从而导致解码出错误消息的干扰都是噪声。如雾气和黑暗干扰了船只之间的信号通信;电报站之间过长的距离减弱了信号的强度;雷电干扰了调频广播的传输;DVD上的划痕会导致读取失败等++,因此\color{#f00}{PSNR}的值越高越好。
由于本文是一篇综述,因此有很多技术点可供我们发掘,下面以有限的篇幅介绍图像压缩的相关技术原理与研究方向
小波变换(Wavelet transform)
小波变换是目前比较流行的图像压缩算法,也是近30年来一个迅速发展的新领域。我们知道,JPEG图像压缩通过舍弃部分人眼基本会忽略的颜色信息位,以减小原始图像的大小,由于无法恢复原始的图像位,因此,常用的JPEG算法是一种有损压缩算法。而小波变换能够巧妙地将空间域和频域特性相结合,从而实现图像的无损压缩,所以小波变换是图像领域的重点和难点。小波变换用于图像压缩的核心是系数编码,压缩的实质是对系数的量化压缩。

小波变换原理
- 寻求空间L(R)上的标准正交小波基
- 将信号在小波基上分解,便于进行分析和处理
- 可通过分解系数重建原来的信号
由于小波变换的多方面特点,导致其在数字信号的处理上不方便,因此实际应用常采用离散小波变换(DWT),同时小波变换也要跟随图像的性质从一维推广到二维。任何图像都可以分为低频和高频部分,低频包含了图像的主要信息,高频主要是图像的细节纹理。
将一副图像根据二维小波变换算法进行变换后,将会得到一系列不同分辨率的图像。低频部分部分是表现一幅图像最主要的部分,如果只保留低频部分丢弃高频部分,图像数据便可压缩。

</参考代码>
#include <stdio.h>
#include <math.h>
#include <gsl/gsl_sort.h>
#include <gsl/gsl_wavelet.h>
int main (int argc, char **argv)
{
(void)(argc); /* avoid unused parameter warning */
int i, n = 256, nc = 20;
double *orig_data = malloc (n * sizeof (double));
double *data = malloc (n * sizeof (double));
double *abscoeff = malloc (n * sizeof (double));
size_t *p = malloc (n * sizeof (size_t));
FILE * f;
gsl_wavelet *w;
gsl_wavelet_workspace *work;
w = gsl_wavelet_alloc (gsl_wavelet_daubechies, 4);
work = gsl_wavelet_workspace_alloc (n);
f = fopen (argv[1], "r");
for (i = 0; i < n; i++)
{
fscanf (f, "%lg", &orig_data[i]);
data[i] = orig_data[i];
}
fclose (f);
gsl_wavelet_transform_forward (w, data, 1, n, work);
for (i = 0; i < n; i++)
{
abscoeff[i] = fabs (data[i]);
}
gsl_sort_index (p, abscoeff, 1, n);
for (i = 0; (i + nc) < n; i++)
data[p[i]] = 0;
gsl_wavelet_transform_inverse (w, data, 1, n, work);
for (i = 0; i < n; i++)
{
printf ("%g %g\n", orig_data[i], data[i]);
}
gsl_wavelet_free (w);
gsl_wavelet_workspace_free (work);
free (data);
free (orig_data);
free (abscoeff);
free (p);
return 0;
}
研究方向
小波系数零树(EZW)的嵌入式图像编码
特性:
- 按重要性创建比特流,产生完全嵌入的代码,因此简单、有效
- 定义的二进制决策可以将图像与空图像或灰色图像区分
- 达到目标速率时,可以终止编码和解码过程
优点:缺乏先验训练和精度率控制,可应用于渐进传输、图像浏览、多媒体等领域
无损加密后压缩(ETC)技术
优点:可在确保图像安全性的同时实现更高的压缩性能
借助上文的小波变换原理,我们首先利用二维DWT(离散小波变换)将原始数据分割成重要与不重要的部分。这部分的结果为DWT近似子带(LL)和确切的小波子带(LH、HL、HH),其中L代表低,H代表高。分解后,使用伪随机数生成器(PRNG)序列生成的伪随机数对LL进行加密。在对LL进行加密后,再对确切子波带LH、HL、HH进行有效的加密和压缩。近似子带的系数是关键的,而确切子带则被视为不那么关键。LL使用加法模数256进行加密,确切子波带使用系数排列进行加密。加密后,这些条带被排列为LL、LH、HL和HH。该通道提供了一种单独压缩频带的有效技术。首先,利用SVD对加密的子频带进行量化,并利用霍夫曼编码进行无损压缩。
参考文献
[4] 阳婷, 官洪运, 章文康,等. 基于小波变换的图像压缩算法的改进[J]. 计算机与现代化, 2014(10):4.
Brotli 概述
- Brotli 的编码器库提供了 12 个质量级别(从 0 到 11)。它们是⽤压缩速度换取压缩效率的压缩模式:更⾼质量的级别速度较慢,但会产⽣更好的压缩⽐。
- 一个 Brotli 压缩⽂件由 \color{#f00}{元块(meta-blocks)}集合组成。每个元块最多可容纳 16MiB,由两部分组成:一个
数据部分(data part),它存储 LZ77 压缩的放⼊块,以及一个标题(header),每++个块的压缩遵循经典的①LZ77 压缩⽅案并由②计算具有良好的熵的 LZ77 解析和计算 LZ 短语的简洁编码这两个主要阶段组成++。
Brotli 的优势
Brotli 的优势体现在哪里呢?可以参考下图 Brotli 与其它压缩算法在三种不同情况下的对比情况。
- 测试环境:以下结果的测试计算机搭载 Intel® Xeon® CPU E51650 v2,运行频率为 3.5 GHz,具有六个内核和六个额外的超线程上下⽂。运行 linux 3.13.0。所有编解码器均使⽤相同的编译器 GCC 4.8.4 在 O2 级别优化进行编译。
情况1:压缩Canterbury语料库的11个文件
此表显示了 Canterbury语料库上压缩算法的结果。Canterbury 语料库包含 11 个文件,我们显示了测量属性的几何平均值:压缩比、压缩速度和解压缩速度。


情况2:压缩包含 93种不同语言的 1285个HTML文档
压缩算法对从 Internet 爬网的文档样本的结果。该示例包含 1285 个 HTML 文档,其中包含 93 种不同的语言。

情况3:压缩 enwik8文件
enwik8 文件上不同压缩算法的结果。

结果
- 质量级别(quality setting)为1的 brotli的压缩速度和解压缩速度与与质量级别为1的deflate相同,但brotli的压缩比deflate提高了 12% ~ 16%。
- 质量级别为9的 brotli 与 质量级别为9的deflate也大致相同,但 enwik8的解码速度提高了28%,压缩比提高了 13% ~ 21%。
- 质量级别为11的 brotli压缩速度明显快于 zopfli,压缩比高出 20% ~ 26%。
参考
- Brotli: A General-Purpose Data Compressor
- Comparison of Brotli, Deflate, Zopfli, LZMA, LZHAM
and Bzip2 Compression Algorithms - OSCHINA
LZ77 编码简介
- LZ 编码由以色列研究者 Jacob Ziv 和 Abraham Lempel 提出,是无损压缩的核心思想。LZ 是一个系列的算法,而其中最基本的就是两人在 1977年所发表的论文《A Universal Algorithm for Sequential Compression》 中提出的 LZ77 算法。
- LZ77 压缩是一种基于字典及滑动窗口的无损压缩技术,广泛应用于通信传输。
- LZ77 算法不同于 Huffman 编码等基于统计的数据压缩编码,需要得到先验知识——信源的字符频率,然后进行压缩。
- LZ77的核心思想:利用数据的重复结构信息来进行数据压缩。
LZ77 的基本原理
- LZ77 以经常出现的字母组合(或较长的字符串)构建字典中的数据项,并且使用较短的数字(或符号)编码来代替比较复杂的数据项。数据压缩时,将从待压缩数据中读入的源数据与字典中的数据项进行匹配,从中检索出相应的代码并输出。从而实现数据的压缩
- 在 LZ77 方法中,词典就是先前已编码序列的一部分。编码器通过一个滑动窗口来查看输入序列,如下图所示。

-
这个滑动窗口包括两个部分:、查找缓冲区(Search Buffer) 和 先行缓冲区(Look Ahead Buffer)
- 查找缓冲区:包含了最近已编码序列的一部分
- 先行缓冲区:包含待编码序列的下一部分
这里查找缓冲区包含了 8 个符号,先行缓冲区包含 7 个符号。但在实际情况中,缓冲区要大很多。
-
LZ77 中的相关参数解释:
① 匹配指针 先在 查找缓冲区 中找到移动指针,知道找到与先行缓冲区第一个字符a相匹配字符a。++此时该指针与先行缓冲区的距离称为 偏移量(off)++ 。这里的 偏移量off 就是7。
② 编码器之后查看指针位置之后的符号,查看其是否与先行缓冲区的符号相匹配。++从第一个符号(匹配指针以开始所指向的位置)开始,与先行缓冲区的符号匹配,匹配到的连续符号的长度称为 匹配长度(len)++。例如这里,从匹配指针所指的位置开始的符号串 abra 与 先行缓冲区中的符号串 abra 相匹配,下一位查找缓冲区的 x 与 先行缓冲区 a 不匹配,所以这里的 匹配长度len 是 4.。
③ 编码器在查找缓冲区中搜素最长匹配串。找到最长的匹配串后,编码器即可用三元组 <off,len,c> 对其进行编码。这里 off 是偏移量 ,len 是匹配长度,++c 是先行缓冲区中跟在该匹配项串之后的符号的码字++。例如这里 匹配串 是 abra,则先行缓冲区匹配串后的码字是 r。
LZ77 算法
- LZ77 算法执行流程如下:
步骤 1:从输入的待压缩数据的起始位置,读取未编码的源数据,从滑动窗口的字典数据项中查找最长的匹配字符串。若结果为 T,则执行步骤 2,若结果为 F,则执行步骤 3;
步骤 2:输出函数 F(off,len,c)。然后将窗口向后滑动到 len++,继续步骤 1;
步骤 3:输出函数 F(0,0,c),其中 c 为下一个字符。并且窗口向后滑动(len + 1)个字符,执行步骤 1。 - 下面是代码实现:
/*lz77.c*/
#include <netinet/in.h>
#include <stdlib.h>
#include <string.h>
#include "bit.h"
#include "compress.h"
/*compare_win 确定前向缓冲区中与滑动窗口中匹配的最长短语*/
static int compare_win(const unsigned char *window, const unsigned char *buffer,
int *offset, unsigned char *next)
{
int match,longest,i,j,k;
/*初始化偏移量*/
*offset = 0;
/*如果没有找到匹配,准备在前向缓冲区中返回0和下一个字符*/
longest = 0;
*next = buffer[0];
/*在前向缓冲区和滑动窗口中寻找最佳匹配*/
for(k=0; k<LZ77_WINDOW_SIZE; k++)
{
i = k;
j = 0;
match = 0;
/*确定滑动窗口中k个偏移量匹配的符号数*/
while(i<LZ77_WINDOW_SIZE && j<LZ77_BUFFER_SIZE - 1)
{
if(window[i] != buffer[j])
break;
match++;
i++;
j++;
}
/*跟踪最佳匹配的偏移、长度和下一个符号*/
if(match > longest)
{
*offset = k;
longest = match;
*next = buffer[j];
}
}
return longest;
}
/*lz77_compress 使用lz77算法压缩数据*/
int lz77_compress(const unsigned char *original,unsigned char **compressed,int size)
{
unsigned char window[LZ77_WINDOW_SIZE],
buffer[LZ77_BUFFER_SIZE],
*comp,
*temp,
next;
int offset,
length,
remaining,
hsize,
ipos,
opos,
tpos,
i;
/*使指向压缩数据的指针暂时无效*/
*compressed = NULL;
/*写入头部信息*/
hsize = sizeof(int);
if((comp = (unsigned char *)malloc(hsize)) == NULL)
return -1;
memcpy(comp,&size,sizeof(int));
/*初始化滑动窗口和前向缓冲区(用0填充)*/
memset(window, 0 , LZ77_WINDOW_SIZE);
memset(buffer, 0 , LZ77_BUFFER_SIZE);
/*加载前向缓冲区*/
ipos = 0;
for(i=0; i<LZ77_BUFFER_SIZE && ipos < size; i++)
{
buffer[i] = original[ipos];
ipos++;
}
/*压缩数据*/
opos = hsize * 8;
remaining = size;
while(remaining > 0)
{
if((length = compare_win(window,buffer,&offset,&next)) != 0)
{
/*编码短语标记*/
token = 0x00000001 << (LZ77_PHRASE_BITS - 1);
/*设置在滑动窗口找到匹配的偏移量*/
token = token | (offset << (LZ77_PHRASE_BITS - LZ77_TYPE_BITS - LZ77_WINOFF_BITS));
/*设置匹配串的长度*/
token = token | (length << (LZ77_PHRASE_BITS - LZ77_TYPE_BITS - LZ77_WINOFF_BITS - LZ77_BUFLEN_BITS));
/*设置前向缓冲区中匹配串后面紧邻的字符*/
token = token | next;
/*设置标记的位数*/
tbits = LZ77_PHRASE_BITS;
}
else
{
/*编码一个字符标记*/
token = 0x00000000;
/*设置未匹配的字符*/
token = token | next;
/*设置标记的位数*/
tbits = LZ77_SYMBOL_BITS;
}
/*确定标记是大端格式*/
token = htonl(token);
/*将标记写入压缩缓冲区*/
for(i=0; i<tbits; i++)
{
if(opos % 8 == 0)
{
/*为压缩缓冲区分配临时空间*/
if((temp = (unsigned char *)realloc(comp,(opos / 8) + 1)) == NULL)
{
free(comp);
return -1;
}
comp = temp;
}
tpos = (sizeof(unsigned long ) * 8) - tbits + i;
bit_set(comp,opos,bit_get((unsigned char *)&token,tpos));
opos++;
}
/*调整短语长度*/
length++;
/*从前向缓冲区中拷贝数据到滑动窗口中*/
memmove(&window[0],&window[length],LZ77_WINDOW_SIZE - length);
memmove(&window[LZ77_WINDOW_SIZE - length],&buffer[0],length);
memmove(&buffer[0],&buffer[length],LZ77_BUFFER_SIZE - length);
/*向前向缓冲区中读取更多数据*/
for(i = LZ77_BUFFER_SIZE - length; i<LZ77_BUFFER_SIZE && ipos <size; i++)
{
buffer[i] = original[ipos];
ipos++;
}
/*调整剩余未匹配的长度*/
remaining = remaining - length;
}
/*指向压缩数据缓冲区*/
*compressed = comp;
/*返回压缩数据中的字节数*/
return ((opos - 1) / 8) + 1;
}
/*lz77_uncompress 解压缩由lz77_compress压缩的数据*/
int lz77_uncompress(const unsigned char *compressed,unsigned char **original)
{
unsigned char window[LZ77_WINDOW_SIZE],
buffer[LZ77_BUFFER_SIZE]
*orig,
*temp,
next;
int offset,
length,
remaining,
hsize,
size,
ipos,
opos,
tpos,
state,
i;
/*使指向原始数据的指针暂时无效*/
*original = orig = NULL;
/*获取头部信息*/
hsize = sizeof(int);
memcpy(&size,compressed,sizeof(int));
/*初始化滑动窗口和前向缓冲区*/
memset(window, 0, LZ77_WINDOW_SIZE);
memset(buffer, 0, LZ77_BUFFER_SIZE);
/*解压缩数据*/
ipos = hsize * 8;
opos = 0;
remaining = size;
while(remaining > 0)
{
/*获取压缩数据中的下一位*/
state = bit_get(compressed,ipos);
ipos++;
if(state == 1)
{
/*处理的是短语标记*/
memset(&offset, 0, sizeof(int));
for(i=0; i<LZ77_WINOFF_BITS; i++)
{
tpos = (sizeof(int)*8) - LZ77_WINOFF_BITS + i;
bit_set((unsigned char *)&offset, tpos, bit_get(compressed,ipos));
ipos++;
}
memset(&length, 0, sizeof(int));
for(i=0; i<LZ77_BUFLEN_BITS; i++)
{
tpos = (sizeof(int)*8) - LZ77_BUFLEN_BITS + i;
bit_set((unsigned char *)&length, tpos, bit_get(compressed,ipos));
ipos++;
}
next = 0x00;
for(i=0; i<LZ77_NEXT_BITS; i++)
{
tpos = (sizeof(unsigned char)*8) - LZ77_NEXT_BITS + i;
bit_set((unsigned char *)&next, tpos, bit_get(compressed,ipos));
ipos++;
}
/*确保偏移和长度对系统有正确的字节排序*/
offset = ntohl(offset);
length = ntohl(length);
/*将短语从滑动窗口写入原始数据缓冲区*/
i=0;
if(opos>0)
{
if((temp = (unsigned char *)realloc(orig,opos+length+1)) == NULL)
{
free(orig);
return 1;
}
orig = temp;
}
else
{
if((orig = (unsigned char *)malloc(length+1)) == NULL)
return -1;
}
while(i<length && remaining>0)
{
orig[opos] = window[offset + i];
opos++;
/*在前向缓冲区中记录每个符号,直到准备更新滑动窗口*/
buffer[i] = window[offset + i];
i++;
/*调整剩余符号总数*/
remaining --;
}
/*将不匹配的符号写入原始数据缓冲区*/
if(remaining > 0)
{
orig[opos] = next;
opos++;
/*仍需在前向缓冲区中记录此符号*/
buffer[i] = next;
/*调整剩余字符总数*/
remaining--;
}
/*调整短语长度*/
length++;
}
else
{
/*处理的是字符标记*/
next = 0x00;
for(i=0; i<LZ77_NEXT_BITS; i++)
{
tpos = (sizeof(unsigned char)*8) - LZ77_NEXT_BITS + i;
bit_get((unsigned char *)&next, tpos,bit_get(compressed,ipos));
ipos++;
}
/*将字符写入原始数据缓冲区*/
if(opos > 0)
{
if((temp = (unsigned char*)realloc(orig,opos+1)) == NULL)
{
free(orig);
return -1;
}
orig = temp;
}
else
{
if((orig = (unsigned char *)malloc(1)) == NULL)
return -1;
}
orig[opos] = next;
opos++;
/*在前向缓冲区中记录当前字符*/
if(remaining > 0)
buffer[0] = next;
/*调整剩余数量*/
remaining--;
/*设置短语长度为1*/
length = 1;
}
/*复制前向缓冲中的数据到滑动窗口*/
memmove(&window[0], &window[length],LZ7_WINDOW_BITS - length);
memmove(&window[LZ77_WINDOW_SIZE - length], &buffer[0], length);
}
/*指向原始数据缓冲区*/
*original = orig;
/*返回解压缩的原始数据中的字节数*/
return opos;
}