- 本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
- 成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
- 黑龙江大学大一在校生
- 华南理工大学大一在校生
- 我们是来自
6个地方的同学,我们在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究操作系统技术…
@[toc]
【往期回顾】
① 2月23日 《老子到此一游系列》之 老子为什么是老子 —— ++综述视角解读压缩编码++
② 3月11日 《老子到此一游系列》之 老子带你看懂这些风景 —— ++多维探秘通用无损压缩++
③ 3月25日 《老子到此一游系列》之 老子见证的沧海桑田 —— ++轻翻那些永垂不朽的诗篇++
④ 4月4日 《老子到此一游系列》之 老子游玩了一条河 —— ++细数生活中的压缩点滴++
⑤ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——一文穿透多媒体过往前沿++
⑥ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——这些小风景你不应该错过++
⑦ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——浅析稀疏表示医学图像++
⑧ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——计算机视觉数据压缩应用++
⑨ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——点燃主缓存压缩技术火花++
⑩ 4月29日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——即刻征服3D网格压缩编码++
⑪ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——云计算数据压缩方案++
⑫ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——大数据框架性能优化系统++
⑬ 5月10日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——物联网摇摆门趋势算法++
【本期看点】
HCompress在多层存储环境中大放光彩揭秘消费类电子设备软件更新压缩算法AIMCS如何压缩短字符串
【技术DNA】
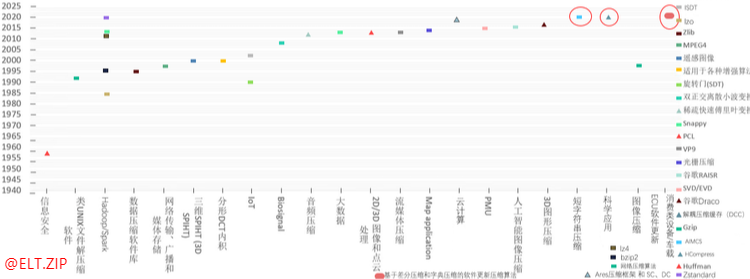
【智慧场景】
| ********** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
******************** |
| 场景 |
自动驾驶 / AR |
语音信号 |
流视频 |
GPU 渲染 |
科学、云计算 |
内存缩减 |
科学应用 |
医学图像 |
数据库服务器 |
人工智能图像 |
文本传输 |
GAN媒体压缩 |
图像压缩 |
文件同步 |
| 技术 |
点云压缩 |
稀疏快速傅里叶变换 |
有损视频压缩 |
网格压缩 |
动态选择压缩算法框架 |
无损压缩 |
分层数据压缩 |
医学图像压缩 |
无损通用压缩 |
人工智能图像压缩 |
短字符串压缩 |
GAN 压缩的在线多粒度蒸馏 |
图像压缩 |
文件传输压缩 |
| 开源项目 |
Draco / 基于深度学习算法/PCL/OctNet |
SFFT |
AV1 / H.266编码 / H.266解码/VP9 |
MeshOpt / Draco |
Ares |
LZ4 |
HCompress |
DICOM |
Brotli |
RAISR |
AIMCS |
OMGD |
OpenJPEG |
rsync |
引言
- “人工智能”大家应该不陌生,这算是近几年的“热词”,而”压缩算法“长期关注我们团队的读者也应该挺熟悉,但是何为“短字符串”呢?非计科专业背景的读者乍一听,可能有点茫然。简而言之,我们聊qq,发微信用的一条条消息笼统的说就是短字符串,从专业角度定义的话,就是平均长度为160个字符的字符串。
- 现在大家对我们今天介绍的主角有了一个基本的认知,那么接下来我们步入正题。
时代背景
- 近年来,在空间通信,⭐卫⭐星⭐回程等领域,短文本在数据通信中的使用急剧增加。为了降低带宽的利用率和成本,必须对短写文本采用新的压缩方法。在本文中我们将介绍一种基于人工智能的无损压缩算法,旨在减少网络上消息传输过程中的数据量。
应用场景
- 空间通信

- inReach(手持式⭐卫⭐星⭐通信器)

- ⭐卫⭐星⭐回程
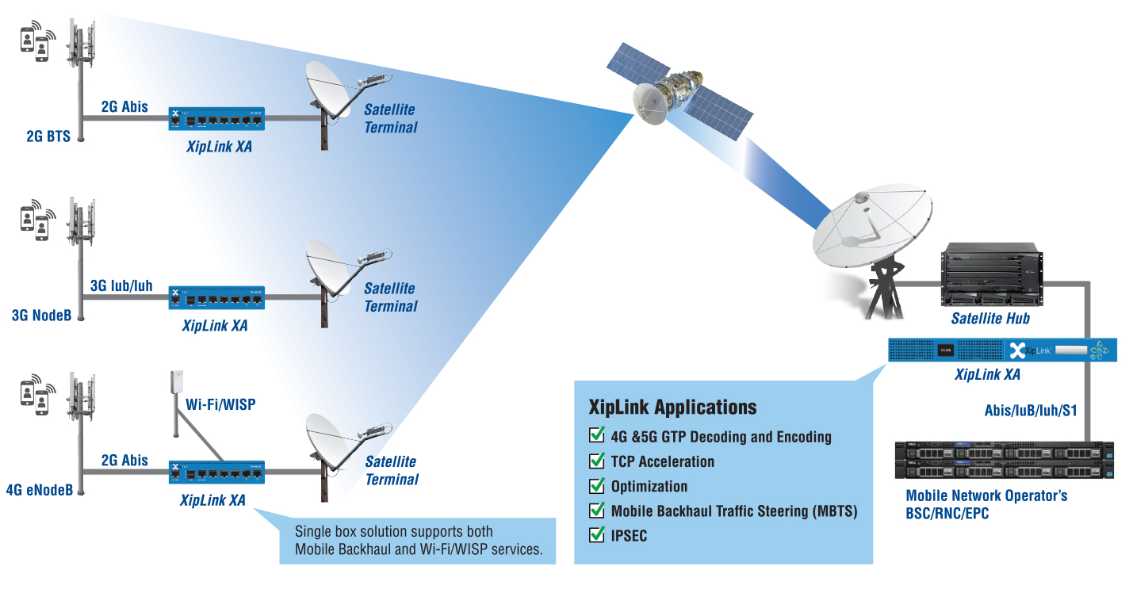
- 带宽匮乏的移动网状网络
技术现状
Huffman编码
- 基本思想:基于字符串中字符的重复次数进行编码,出现频率越高编码越短。
- 局限性:
- 所有的数据和统计信息都必须在压缩时可用。不适合那些连续生成数据的应用程序。
- 压缩少量数据时,无法减少数据的大小,甚至随着开销的增大而增大,压缩后数据超过原始数据大小。
基于单词的字符串压缩方法。
- 基本思想:文本根据其大小进行分类。找到在不同大小文本中形成压缩基本单元以提高压缩性能。
- 基本单元分为三组:
word、vavel和character(word是一组字符,而vavel比character短,但比character长)
- 文本的大小超过 5 MB ——>
word
- 文字大小为 200 KB - 5 MB——>
vavel
- 文本大小为 100 - 200 KB——>
character
- 测试结果:该方法应用于数据大小为 100KB 的批数据
LZW算法
- 它是一种适合字符串压缩的方法。LZW是1977年提出的LZ算法的改进版本。许多压缩软件如
winzip, pkzip, gzip都是基于LZW的。
- 这种方法根据扫描目标文本动态更新构造字符串索引字典。
- 但是,这种方法不适合压缩小字符串因为和哈夫曼编码一样有时字典和压缩数据的大小会超过原始数据的大小
SMAZ
- 这种方法的目的是通过查找人们发送的消息的模式,找出重复次数最多的单词,然后将这些单词映射到索引中。
- 这种方法
减小了短文本消息的大小。例如短文本在推特的比例分别为29%和19%。
- SMAZ的缺点识别发送信息的模式并不容易,特别是使用不同方言的人在与不同类型的人交谈时发送的消息。
其他方案
- 一种利用BP网络预测字符重复的方法,使数据量减少了30%。神经网络被用于减小图像的大小。提出了一种新的
实用的、通用的字符串无损压缩算法——神经马尔可夫预测压缩(NMPC)。
- 该方法基于
贝叶斯神经网络(BNN)和隐马尔可夫模型(HMM)的结合,具有线性处理时间、恒定的内存存储性能和对并行的适应性。然而,这种方法适用于那些大小至少为8 KB的批数据,
结论
- 在大多数讨论的短文本压缩方法中,压缩数据的大小和压缩开销都大于原始数据的大小。
尚未解决问题
- 减少小字符串的大小。
- 是否适合压缩不同语言和口音的文本
- 可以在生成数据流的应用程序中使用
针对所有讨论的挑战和问题,我们提出了一种新的压缩方法。
AIMCS
- AIMCS显著降低了数据的大小。将我们的算法与lzw和霍夫曼方法进行比较,也表明,在字符串的压缩过程中,我们的方法在压缩方面具有更好的性能。压缩时间增加,压缩时间增加,与需要实时文本传输时的传输时间相比不显著。
- AIMCS是一种
基于人工智能的方法,用于压缩小于160字节的微小字符串。
- 我们已经考虑过这个大小的小字符串,因为在像Twitter这样的即时消息传递网络中,一条消息的远小于160字节。

基本方法
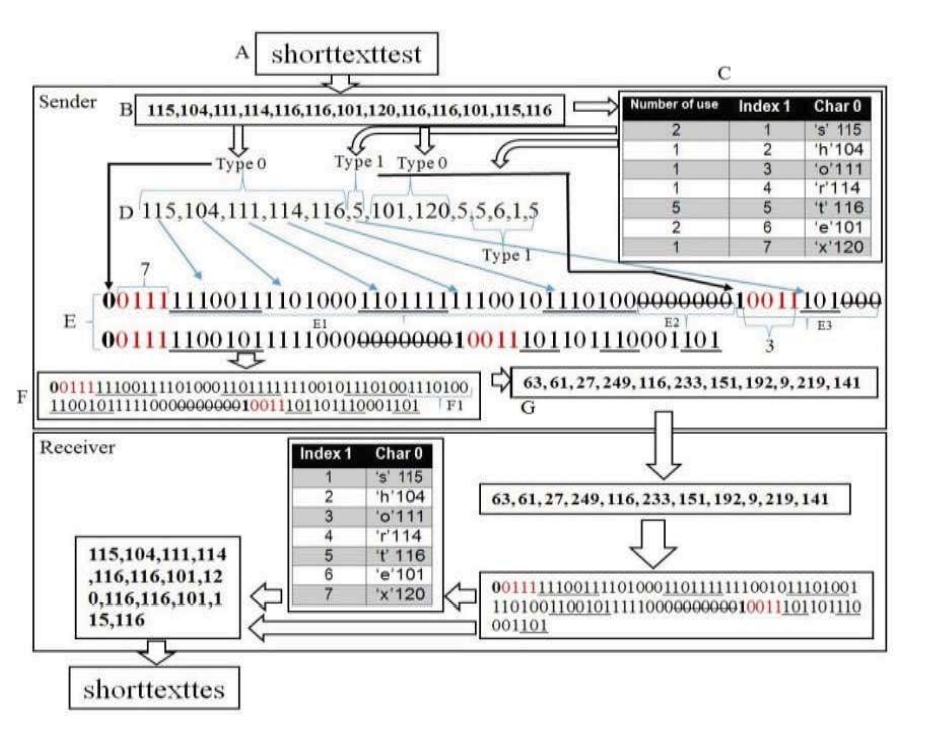
- 我们提出了一个四层压缩小字符串的算法,其中形成了一个表,每个字符都映射到一个索引。因此,在下一次字符的重复使用中,将使用索引而不是字符,这会导致数据大小的减少。
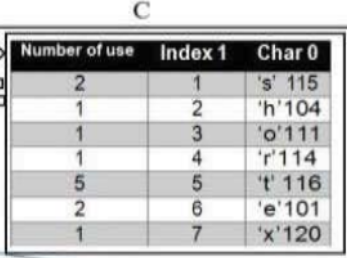
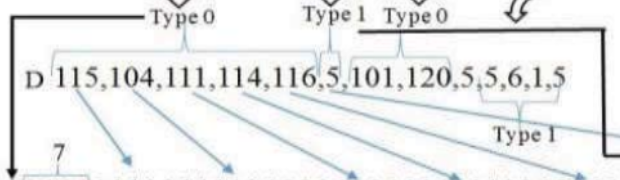
以“shorttexttest”为例
注意事项
- 表C的顺序直接影响压缩率
因为当较短的索引映射到最频繁的字符时,字符串的总大小会减少。
- 表C的顺序必须基于字符的使用数量
重复次数最多的字符必须在第一行,其他字符必须按照重复次数的降序排列。
- 当发送几个字符时,必须检出表C,确保行顺序合适。如果顺序不合适,表必须重新排序才能再次使用。
- 检测重新排序表格所需的时间是我们进行这项研究的主要挑战。
- 我们的最终目标是预测表重排序过程的评估时间,它直接影响压缩比。
- B表的AIMCS在通信过程开始的时候,表是空的,没有要排序的东西,这是表最适合的状态。当发送几个字符(Brecognition或β)时,表必须被检出。
- 通过
排序质量(Sq)公式(1)对表进行求值,n是重复次数,m是行数
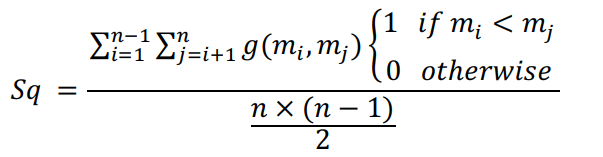
- 上述公式的结果是一个介于0到1之间的数字,分别代表表的最佳状态和最差状态。
- 在表求值的每一步中,在发送
βr 字符后,将Sq公式得到的结果与常数参数a进行比较。
- 如果
Sq > a,则If -condition为true,并且表必须重新排序,并且接收方也必须被告知表的重新排序。
- 如果我们认为a是一个小的数量,那么被记录的机会就会增加,从而增加更多的过载。
- 反之,如果我们认为a很大,表的情况就会很糟糕,会对压缩比产生不利的影响。
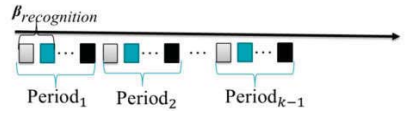
- 由图2可知,“
period”是表的最佳状态到表必须重新排序的状态之间的时间间隔。每个周期还由几个子周期组成,它们分别显示表的最佳状态(白色矩形)、if-condition必须被检查的状态(绿色矩形)和表必须被重新排序的状态(黑色矩形)。时期I和其他时期之间的区别是,在时期1中,表一开始是空的,但在其他时期,表包含一些实体,周期的长度可以不同。
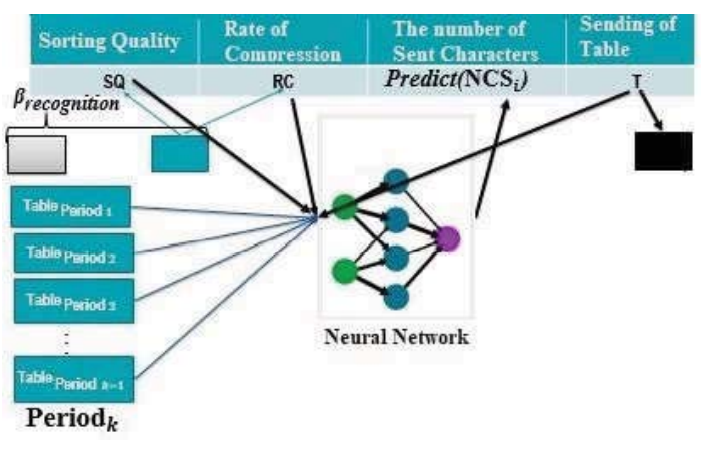
- 在一个周期的第一步,经过ßr字符传输后,计算排序质量和压缩率,将Sq与a进行比较。
- 如果
Sq < a, If -condition为假,另一个ß为必须发送的数据量。
- 如果
Sq > a,表必须重新排序。当if-condition为True时,此表用于提高神经网络学习的准确性。
实验
作者使用 AIMCS 和其它的压缩方法分别压缩一组 ASCII 编码和 Unicode 编码的短文本。这些短文本是在没有任何过滤的情况下从英语、阿拉伯语以及波斯语的 Twitter 和短文本消息中提取的。
实验一:压缩英语字符串(ASCII)得到的结果
| 语言 |
类型 |
算法 |
原始大小(Bytes) |
压缩比(%) |
运行时间(min) |
| English |
SMS |
LZW |
80904070 |
85.60 |
5.43 |
| English |
SMS |
AIMCS |
80904070 |
77.81 |
16.3 |
| English |
Twitter |
LZW |
584630 |
86.79 |
0.04 |
| English |
Twitter |
AIMCS |
584630 |
84.31 |
0.13 |
由上表可知:
- LZW 算法在压缩英文文本的速度要比其它讨论的算法更快
- AIMCS 在压缩英文文本的压缩比其它讨论的算法要低
- AIMCS 在压缩 SMS 和 Twitter 的英文文本时的压缩比要远低于 LZW 压缩这两种文本的压缩比
实验二:压缩阿拉伯和波斯语字符串(Unicode)得到的结果
| 语言 |
算法 |
原始大小(Bytes) |
压缩比(%) |
运行时间(s) |
| Persian |
Huffman |
3243550 |
67.55 |
32.56 |
| Persian |
AIMCS |
3243550 |
58.82 |
35.37 |
| Arabic |
Huffman |
265156 |
68.34 |
1.92 |
| Arabic |
AIMCS |
265156 |
54.93 |
2.23 |
由上表知:
- 在几乎 相同的运行时间 内,AIMCS 的压缩比要明显低于 LZW 算法的压缩比。
- 在压缩 相同大小的文本 时,AIMCS 压缩比要比 Huffman 低 ,极大地降低了传输文本的时间和成本。
实验三:一段时间内压缩900万条推文的压缩比
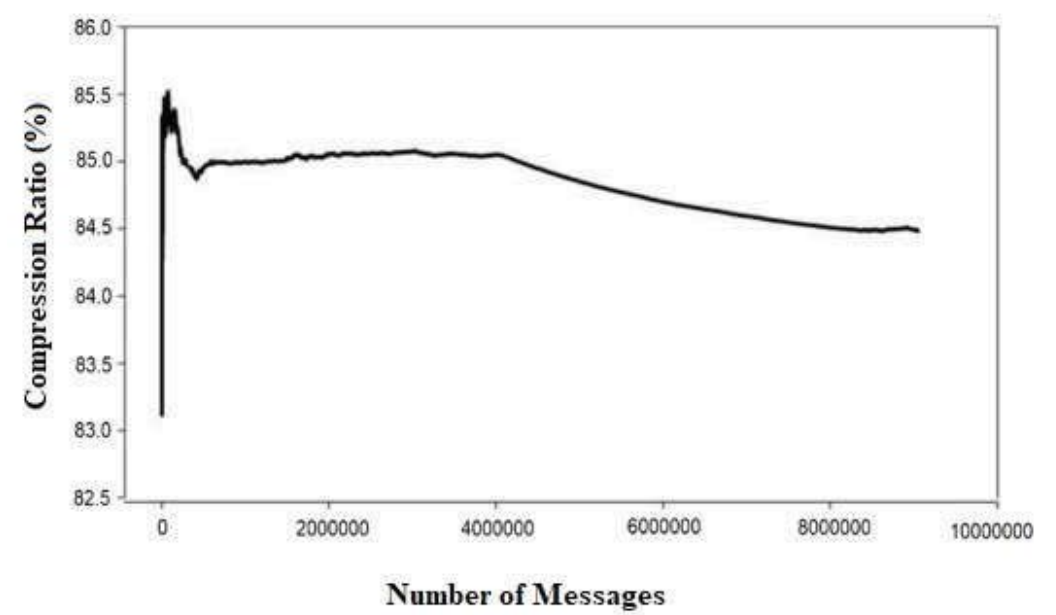
上图描述了 AIMCS 在压缩大量 tweet 的性能。
- 可以看到,随着消息数量的增加,AIMCS 在压缩 tweet 的压缩比会降低,压缩性能会更好。
结果分析
- AIMCS 最初对之前的数据没有足够的了解,无法建立足够大的字典, 可能会因此无法预测之后会出现的字符串。随着字典中条目数量的增加,通过检测字符的种类和重复频率,随着时间的推移,AIMCS的压缩效果将会提升。
- 为了核对
偏移现象(drift phenomenon),将会把预测的字符的数量发送给接收者。如果预测的字符的数量是准确的,将给予一个正向反馈,反之给予一个负向反馈。
- AIMCS 独立于语言和语法,可以用于压缩任何具有语法结构的语言。另外,AIMCS 是通过压缩数据流来进行压缩的,所以词法错误并不会影响 AIMCS 的性能。
实验总结
由于以上优点,AIMCS 也适用于基于雾计算(fog computing)的方法。
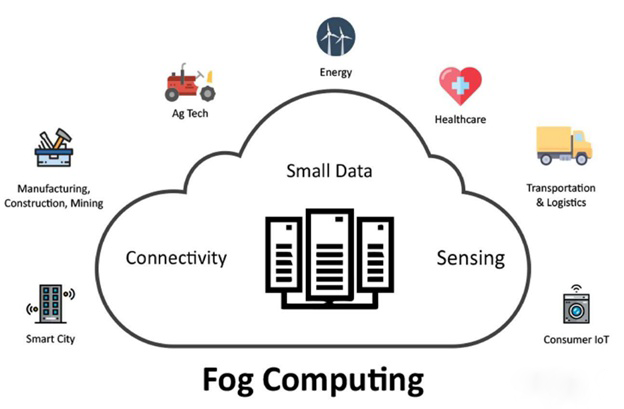
在物联网(IoT)的场景中,许多计算能力有限的小型智能设备需要不断产生极短字符串(tiny strings)的数据,并通过互联网将其发送到远程服务器上进行处理。在这些场景中,生成的原始数据将会由一个名为 Fog Server 的实体进行压缩,该实体位于产生数据的节点和远程服务器之间,以减少 Internet 流量。
AIMCS的局限性
- AIMCS 不太适合字符数量多、重复字符数量少的语言文本压缩
- AIMCS 不适合压缩文本以外的数据
因为AIMCS 设计时的压缩单元是一个字符,压缩其它图像、音频等其它数据,这些数据包含很多与文本压缩不同的参数,这使得 AIMCS 需要在发送端进行大量计算,将会大大减少压缩效率。
引文
[1] Abedi M, Pourkiani M. AiMCS: An artificial intelligence based method for compression of short strings[C]//2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI). IEEE, 2020: 311-318.
[2] Zaccaria A, Del Vicario M, Quattrociocchi W, et al. PopRank: Ranking pages’ impact and users’ engagement on Facebook[J]. PloS one, 2019, 14(1): e0211038.
[3] Pourkiani M, Abedi M. An introduction to a dynamic data size reduction approach in fog servers[C]//2019 International Conference on Information and Communications Technology (ICOIACT). IEEE, 2019: 261-265.
开源项目
整体概述
- 为了提高带宽利用率和降低成本,我们提出了
AIMCS,这是一种专门为压缩短字符串 (平均长度为160个字符)而设计的压缩算法。
AIMCS接收一个短字符串作为输入,并使用索引方法。然后它创建一个表,其中每个字符都映射到一个索引。因此,在下次字符重复使用时,使用索引代替字符,导致数据的大小减少。正如描述中所提到的,这里我们讨论我们在论文中提出的基本压缩算法。因此,α和β参数必须手动设置。例如,我们准备了几个微小的字符串,它们被认为是由发送方连续生成的,并一个接一个地发送给接收方。AIMCS算法的介绍可以在上找到。更多信息也可以在本文和AIMCS主页中找到。
在下面的内容中,我们将展示AIMCS代码如何用于压缩ascii和Unicode小字符串
执行要求
我们在Windows环境下用c#编写了AIMCS算法。必须注意的是,代码执行过程需要。net framework 2和Visual Studio。此外,AIMCSAv1.cs文件必须添加到项目文件中。
- 这里我们提供了两个压缩 ASCII 小字符串的示例。在第一个示例(可以认为是我们的方法的模式)中展示了AIMCS如何压缩一个小字符串。
例 1:
AIMCSAv1 AIMCSSend = new AIMCSAv1();
AIMCSAv1 AIMCSReceive = new AIMCSAv1();
byte[] t_byte = AIMCSSend.Compress("Mytext");
string decompressed = AIMCSReceive.Decompress(t_byte);
- 在第二个例子中,我们展示了
AIMCS如何对几个不同的小字符串进行压缩。
例 2:
- 生成的小字符串可以在附加文件
TinyStringExamples 中找到。在下面的文本中,我们对代码的不同部分进行了解释。
- 必须使用下列 .net 库
using System;
using System.Text;
using System.IO;
using AIMCSA;
- 下面的函数读取小字符串并将它们存储在全局
Temp数组中。readTextFile函数定义在这段代码中的main函数之后。
readTextFile("TinyStringExmples.txt");
- 这部分代码用于打印消息的数量(小字符串)和包含
TinyStringExamples 内容的临时数组的大小。代码如下:
Int32 originalSize = 0;
{
int i = 0;
for (; i < Temp.Length && Temp[i] != null; i++)
originalSize += Temp[i].Length;
Console.WriteLine("The number of strings:" + i.ToString());
Console.WriteLine("\nThe size of original strings:" + '\t' + originalSize.ToString());
}
- 在接下来的部分中,将设置变量的初始值,并分别为发送方和接收方创建压缩类(称为
AIMCS)。如下所示,alpha和beta参数是手动设置的。
double sizeofNewMethod = 0;
int counterChar = 0;
int useResort = 0;
AIMCSAv1 AIMCSSend = new AIMCSAv1();
AIMCSAv1 AIMCSReceive = new AIMCSAv1();
AIMCSSend.beta = 70000;
AIMCSSend.alpha = 0.045;
- 在下面的for循环中,
AIMCS类的对象在每次重复中压缩微小的字符串。第一个if-condition还检查表是否需要重新排序。如果需要重新排序,第二个If条件将重新排序表。
for (int i = 0; i < Temp.Length && Temp[i] != null; i++)
{
byte[] t_byte = AIMCSSend.Compress(Temp[i]);
counterChar += Temp[i].Length;
sizeofNewMethod += t_byte.Length;
string decompressed = AIMCSReceive.Decompress(t_byte);
if (counterChar > AIMCSSend.beta)
{
counterChar = 0;
AIMCSSend.checkUseOfChar();
if (AIMCSSend.needResort)
{
useResort++;
AIMCSSend.needResort = false;
AIMCSSend.Resort();
byte[] newTable = AIMCSSend.makeTableforSending();
sizeofNewMethod += newTable.Length;
AIMCSReceive.Decompress(newTable);
}
}
}
double percent = Math.Round((-1 * (((originalSize - sizeofNewMethod ) / originalSize) - 1)), 3);
Console.WriteLine("\nThe size of strings after getting compressed by AIMCS:" + '\t' + (sizeofNewMethod).ToString() +
'\t' + percent.ToString() + "%" + '\t' + "Sort=" + useResort.ToString());
Console.ReadKey();
public static void readTextFile(String path)
{
path = AppDomain.CurrentDomain.BaseDirectory + "\" + path;
if (!File.Exists(path))
{
using (FileStream fs = File.Create(path))
{
Byte[] info =
new UTF8Encoding(true).GetBytes("The File Should replace this file.");
fs.Write(info, 0, info.Length);
}
}
int index = 0;
string s = "";
using (StreamReader sr = File.OpenText(path))
while ((s = sr.ReadLine()) != null)
Temp[index++] = s;
}
例2的输出:
The number of strings:10101
The size of original strings: 584630
The size of strings compression with new method: 453206 0.775% Sort=6
The size of strings compression with new method: 453206 0.775% Sort=6
- 值得一提的是,该算法可用于压缩任何应用程序上的任何类型的短字符串。
- 对于
Unicode小字符串的压缩,在上述代码中,必须使用AIMCSAv1类而不是AIMCSUv1类。
出处
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号





 7765
7765










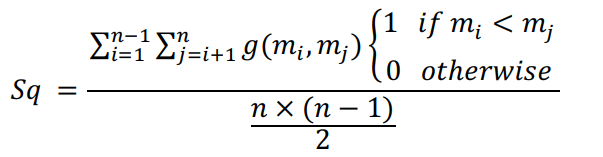





 淘帖
淘帖





