- 本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
- 成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
- 黑龙江大学大一在校生
- 山东大学大三在校生
- 华南理工大学大一在校生
- 我们是来自
7个地方的同学,我们在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究操作系统技术…
@[toc]
【往期回顾】
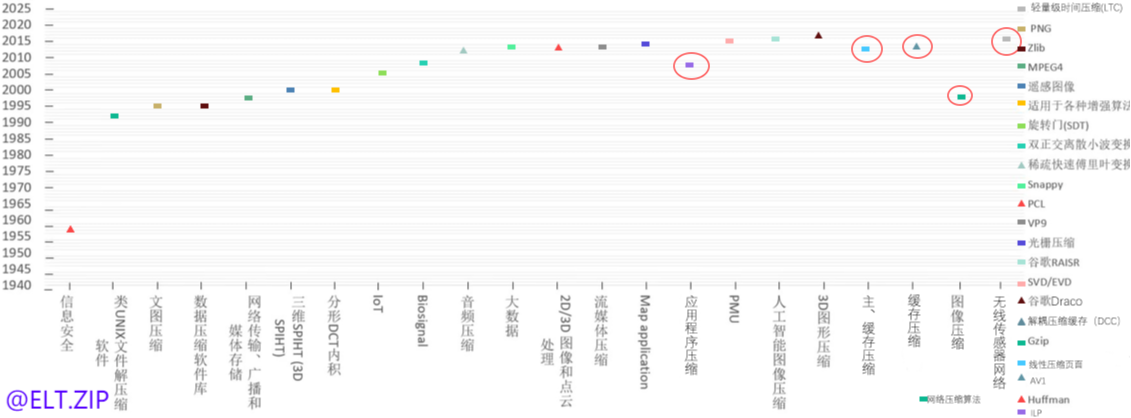
① 2月23日 《老子到此一游系列》之 老子为什么是老子 —— ++综述视角解读压缩编码++
② 3月11日 《老子到此一游系列》之 老子带你看懂这些风景 —— ++多维探秘通用无损压缩++
③ 3月25日 《老子到此一游系列》之 老子见证的沧海桑田 —— ++轻翻那些永垂不朽的诗篇++
④ 4月4日 《老子到此一游系列》之 老子游玩了一条河 —— ++细数生活中的压缩点滴++
⑤ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——一文穿透多媒体过往前沿++
⑥ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——这些小风景你不应该错过++
⑦ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——浅析稀疏表示医学图像++
【本期看点】
高速缓存与压缩技术会碰撞出什么火花呢?图像、医疗、机器人、通信都在这里了你可能少有听说的TinyOS操作系统揭秘 3D 网格压缩的三类方式殿堂级 WARP 寄存器压缩技术
【技术DNA】
【智慧场景】
引言
- 近年来,科学应用和社交媒体产生的数据量呈
指数级增长,仅靠内存系统资源的过度供应无法解决过量的数据处理需求。为了解决这样的问题,采用内存级数据压缩极其有必要,它可有效提高内存系统容量,且不会导致大容量内存的规格 / 存储开销,可同时减小丢包率并提高带宽利用率,从而实现性能与能源效率的提高。因此目前,压缩已被用于缓存和主存。
- 另外,压缩还可减小应用程序占用空间和内存需求,可将内存中暂未使用的部分转换为
低功耗状态,以节省电源。降低了能耗与温度,便缓解了对散热的需求,为在相同功率和温度约束下实现更强的性能提供了条件。
- 随着智能手机的数量超过地球人口,多媒体app越来越普遍,在手机中采用压缩算法势在必行。
相关技术算法
| 名称 |
备注 |
| 冗余位写删除技术(RBR) |
计算输入值与原始存储值之间的位级差异,再应用压缩获得更高压缩比 |
| X-match 硬件压缩算法 |
在内存数据包含频繁的连续零时,显著提高压缩效率 |
| 频繁值压缩算法(FVC) |
对频繁值编码实现压缩,局限性是会遇到频繁值出现概率降低的情况 |
| 频繁模式压缩算法(FPC) |
扫描数据,对未完全利用其位容量的数据类型进行降级 |
| 基本增量即时压缩算法(BDI) |
低复杂度硬件实现、低解压延迟 |
算法应用的体系架构
1. 缓存
什么是缓存? 我们常在各种场合听过、见过、说过这个词,比如手机需要常常清除各种应用缓存垃圾以谋求更富余的存储空间、早年通讯网络还不像现在如此发达的时候,人们为了有更好的观影体验,都会采取先提前把一两个G的资源缓存下来的方式、文档缓存保证了在发生意外断电等情况时内容不会丢失…
诸如以上等类,可见,缓存是计算机体系中的基础部件,保证了系统的正常运转。然而,虽然都叫做缓存,但它们有时是名词有时是动词,实际意义不完全相同。
- 缓存是访问速度比一般随机存取存储器(RAM)更快的一种高速存储器,通常不像系统主存那样使用动态随机存取技术(DRAM),而使用昂贵但较快速的静态随机存取技术(SRAM)。
那么,我们也尝尝有听说缓存又分为一级缓存(*L1 Cache*)、二级缓存(*L2 Cache*)、三级缓存(*L3 Cache*)等,它们的区别又是什么呢?

- LLC(last-level caches)即
末级缓存,是通常由芯片上所有功能单元( CPU 内核、IGP 和 DSP)共享的最高级别缓存,它在降低系统能耗方面有着至关重要的作用。压缩被广泛用于增加磁盘存储的容量,但它也可用于增加内存层次结构中每个级别的有效容量。研究针对缓存层次结构每个级别的缓存压缩,可提高有效容量、减少丢包率,提高性能、降低能耗。缓存压缩比内存中的其他层次结构更难,因为性能对缓存的延迟非常敏感,尤其是对于L1和L2。然而,随着多核系统开始拥有三级以上的多级缓存,对LLC延迟的敏感性降低,从而可以考虑更有效、延迟更长的压缩算法。
DCC(解耦压缩缓存)
-
由于缓存内部的碎片化和有限的标签特性,传统的缓存压缩技术带来的效果有限。因此,提出了解耦压缩缓存(DCC),其利用空间局部性来提高缓存压缩的性能和能耗效率,并且使用解耦的超级块(也称为扇区)与离散的子块分配以减少标签开销,而不增加内部碎片。
-
超级块指的是共享一个地址标签的四个对齐的连续缓存块。超级块中的每个64字节块被压缩,然后压缩成多个16字节的子块。为了减少超级块内的碎片,DCC将地址标记解耦,集合中的任何子块都可以映射到该集合中的任何标记。解耦还允许块的子块是非连续的,这消除了每当压缩块的大小改变时需要重新压缩的开销。因此,大体流程是:DCC使用超级块——四个对其的连续缓存块——减少标记开销。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2QYUEVSn-1651280518550)(https://ycnx.online/wp-content/uploads/2022/04/image-1650952679561.png)]
与传统的缓存压缩技术相比,DCC将标准最大有效容量提高到了压缩前的4倍,平均工作负载为2.2,与以前的缓存压缩技术所需的区域开销相当。而对其进一步优化得到的Co-DCC技术,通过将压缩块共同压缩,更是将平均归一化有效容量提高到了2.6.
-
总体而言,与FixedC、VSC-2X等传统缓存压缩技术,DCC在相当的区域开销基础上实现了性能和能耗效益的翻一番,Co-DCC进一步减少了运行时间与系统能耗,缺点是牺牲了额外的一些复杂度,实验测试结果简单概括为以下几点:
- DCC使用解耦的超级块增加有效的标记数量,并具有较低开销和较小的内部碎片
- DCC将压缩数据存储在离散的子块中,消除了压缩块大小改变时重新压缩的开销
- Co-DCC通过将超级块的块压缩到同一组子块,进一步减少了内部碎片
- 平均来看,DCC和Co-DCC实现了比传统缓存压缩技术更有效的容量,而缓存所需的面积开销分别仅增加了8%和18%
- Co-DCC可以较小复杂度具体集成到商业LLC设计中
2. 主存
主存就是内存,运行时系统资源实际加载到的位置。
嵌入式系统压缩技术CRAMES
- 在嵌入式系统设计过程中,内存是一种
稀缺的资源。增加内存通常会增加包装成本、冷却成本、大小和功耗。因此,提出了一种新型的、高效的基于软件的嵌入式系统RAM压缩技术CRAMES。CRAMES的目标是在不改变硬件或应用程序设计的情况下显著提高有效内存容量,同时保持高性能和低能耗。为了实现这一目标,CRAMES利用了操作系统的虚拟内存基础设施,以压缩格式存储交换出的页面。它动态调整压缩RAM区域的大小,保护能够运行的应用程序免受性能或能耗的影响。除了压缩工作数据集外,CRAMES还可以实现高效的RAM内文件系统压缩,从而进一步增加了RAM容量。
- CRAMES被实现为Linux内核的一个
可加载模块,并在一个电池驱动的嵌入式系统上进行了评估。实验结果表明,CRAMES能够将在原始系统硬件上运行的应用程序的RAM数量增加一倍。对于范围广泛的示例的执行时间和能耗很少受到影响。当物理RAM减少到其原始数量的62.5%,CRAMES使目标嵌入式系统支持相同的应用程序与合理的性能和能耗损失(平均9.5%和10.5%),而没有CRAMES这些应用程序可能不执行或遭受极端的性能退化或不稳定。除了在嵌入式系统中提供了一个用于动态数据内存压缩和RAM内文件系统压缩的新框架外,这项工作还确定了最适合用于低功耗嵌入式系统的基于软件的压缩算法。
3. 缓存和主存
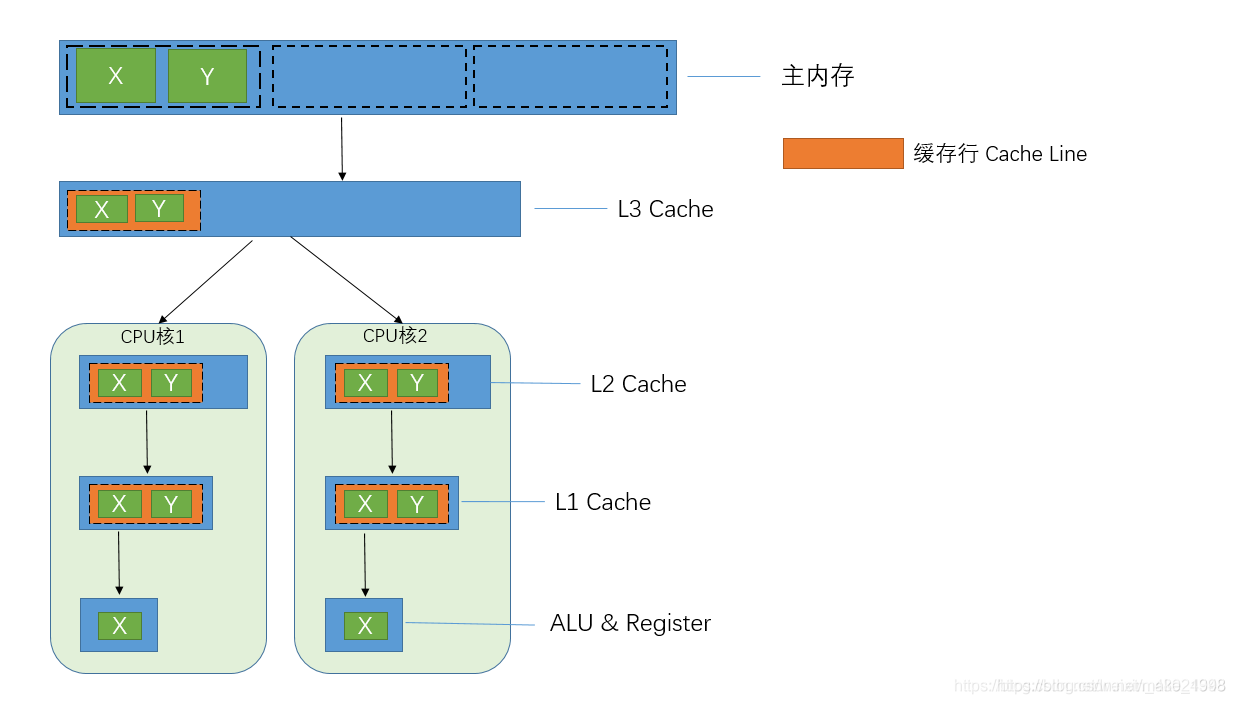
概念补充:缓存行
开始之前,我们先来了解下什么是缓存行。
- 我们知道,计算机不管是在存储内存还是磁盘等结构中的数据时,通常都是习惯采用
一块一块的形式进行存取,因为它是读写数据的最小单位,这就类似于物理中的量子。当CPU访问某个数据时,会假设该数据附近的数据在以后都会被访问到。因此,第一次访问这块区域时,会将该数据连同附近区域的数据(共64字节)一起读进缓存,那么这一块数据就被称为缓存行(Cache Line)。
- 缓存系统以缓存行为单位存储,且目前主流的缓存行大小为
64字节。
线性压缩页面(LCP)
- 线性压缩页面(Linearly Compressed Pages, LCP)是一种
主存压缩框架,它既不会造成压缩的延迟损失,也不需要昂贵的硬件。LCP的含义是:如果页面中的所有缓存行都被压缩到相同的大小,那么压缩页面中的缓存行的位置就是页面中缓存行的索引和压缩缓存行的大小的乘积。通过遵循这样的数学规律,我们便能大大减小在压缩页面时由于定位缓存行所需的计算量,并同时保证LCP在硬件上实现的简单性。
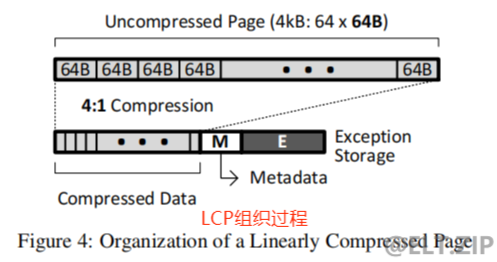
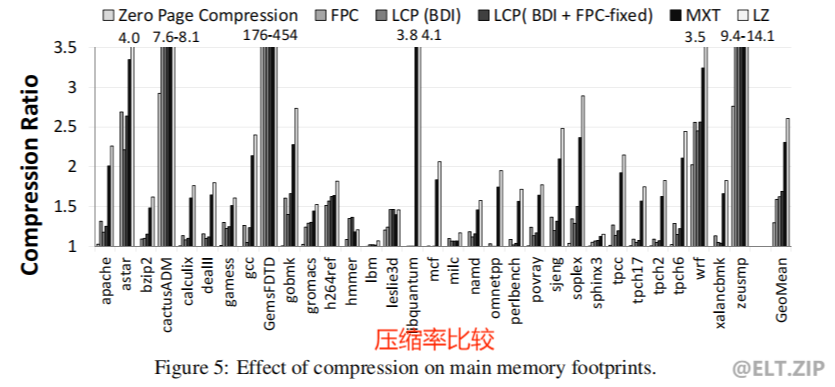
- LCP采用了频繁模式压缩(FPC)和基本增量即时压缩(BDI)两种算法。理论上任何压缩算法都可以结合LCP使用,那为什么偏偏采用它们呢? 原因是它们具有
低复杂度的硬件实现和低解压延迟,从而使整体的复杂度最小化。然后,对LPC进行的相关基准测试表明:LCP可以显著提高有效内存容量(平均提高69%)。另外,LCP在内存控制器和主存之间传输连续压缩缓存行的过程中也有相当的效益,与不使用主存压缩技术的基础系统相比,其降低了CPU平均为46%、GPU平均为48%的内存带宽需求,实现了单核、双核、四核CPU分别为6.1%、13.9%、10.7%的平均工作负载,从而提高了整体性能。
4. 编译器
基于ILP的存储器能耗最小化技术
- ILP全称_integer linear programming_,即
整数线性规划。通过将每种技术都抽象为一个ILP的数学问题,再使用一个商用求解器进行求解,可以有效降低存储能耗。那么,基于相关学者的实践经验,建议可以将其应用于编译器,进而可以考虑最佳的数据压缩、复制和迁移方式。
- 后续为纯算法层面,这里不再过多赘述。
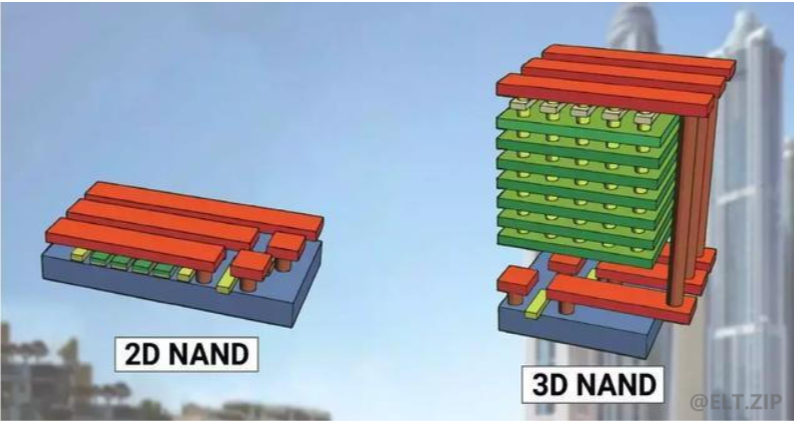
5. 三维存储系统技术
三维存储器旨在克服二维存储器在容量方面的限制,在不牺牲数据完整性的情况下扩展到更高的密度,从而实现更多的存储容量。
3D NAND与L2高速缓存
- 三维存储器3D NAND,与2D NAND不同的是3D NAND使用
多层垂直堆叠,以实现`更高的密度,更低的功耗,更好的耐用性、更快的读/写速度以及更低的每千兆字节成本·。
- 使用3D堆叠的L2高速缓存结构与3D NAND的结构类似。其末级缓存中,使用压缩和电源选通来
节省泄漏能量。他们的技术跟踪对每条高速缓存线的访问频率。当高速缓存线在给定时间内未被访问时,它被认为是非使用的,因此被压缩。其余的线路被认为是经常使用的,不会被压缩。此外,对未使用的高速缓存部分进行电源选通,以节省漏电能量。因此,压缩技术可以在最小化频繁访问的高速缓存线的解压缩开销,同时还可以通过压缩冷高速缓存线来最大化节能。
混合存储立方体
- 混合存储立方体(HMC)设计是在逻辑芯片上执行DRAM的
3D堆叠,并使用硅通孔(TSV)作为不同层之间的互连。HMC的不同层之间可能会发生较大的温度变化,使用基于节流的热管理方案可能会导致性能和效率降低。而数据压缩可以解决这个问题,压缩是在片上存储控制器中执行的,而不是在HMC的逻辑管芯中执行,以避免压缩的能量开销对HMC的影响。读/写压缩块需要较少的突发操作,这降低了HMC内的能量消耗和最高温度。此外,压缩块只存储在HMC的热测试块中以降低热梯度。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VaxeOmDR-1651280518555)(https://ycnx.online/wp-content/uploads/2022/04/image-1651135062650.png)]
6. 非易失性存储器技术
非挥发性存储器,又称非易失性存储器,简称_NVM_,是指存储器所存储的信息在电源关掉之后依然能长时间存在,不易丢失。

使用压缩来减少对NVM内存的位写入,并执行改进的损耗均衡,使用FPC算法来压缩数据,不能压缩的单词以其未压缩的形式写入。在写入操作期间,将新数据位与当前存储的位进行比较,以仅写入经修改的位;在读访问时,如果数据值以压缩的形式存储,则将其解压缩。
通过压缩节省的额外空间被用于执行损耗均衡,使得压缩的数据值被写入到NVM数组中的字的相反侧。这有助于实现通过将写入均匀分布到NVM来实现损耗均衡。由这种技术实现的写最小化和损耗均衡实现了存储器寿命的改善和写等待时间/能量的减少。
PCM存储器
-
相变存储器,简称_PCM_,相变存储器就是利用特殊材料在晶态和非晶态之间相互转化时所表现出来的导电性差异来存储数据的,是NVM的一种。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZnagJTcD-1651280518564)(https://ycnx.online/wp-content/uploads/2022/04/image-1651135232492.png)]
-
基于压缩的MLC/SLC(多/单层单元)混合PCM管理技术将MLC和SLC的优点结合在一起。该技术体现在以下方面:
- 一个2比特的MLC PCM可以在一个单元中存储两个比特,从而提供更高的容量(密度),但其访问延迟较高。
- 相比之下,SLC单元提供的容量较低,但读/写访问速度也比MLC快近四倍。
- 该技术对数据进行压缩,当数据可以压缩到50%以下时,它可以放在同一个单元中,但使用SLC模式,因此提供了更高的性能。
- 当数据不能压缩到50%以下时,以MLC模式存储,代价是访问速度慢。该技术在名义上将PCM空间重新配置为SLC或MLC模式,因此不需要任何剖析或地址重新映射。
DRAM-PCM混合主存储器
- 由于PCM具有较低的写入耐久性和写入消耗较大的延迟/能量,研究人员提出了DRAM-PCM混合主存储器,其中
DRAM用作PCM主存储器的高速缓存。在混合存储系统中使用压缩来提高DRAM的有效容量。
- 在写访问时,该技术从PCM读取现有数据,并
计算新数据和现有数据之间的差值。然后,该差值被压缩并存储在DRAM中。该方法在压缩前将未修改的数据比特转换为零,因此通常提供高压缩比。这种增量压缩方法的权衡在于,在尝试减少PCM写入时,会引入额外的PCM读取。DRAM本身被动态地划分为压缩区域和未压缩区域。只有频繁修改的数据保存在压缩区域中,而性能关键的数据块保存在未压缩区域中,以避免(解)压缩的延迟。
- 该压缩技术技术同时可以分为两个工作阶段:
- 在第一阶段,使用一种算法在“字级别”压缩数据,该算法计算块的连续字之间的差异,如果它们相同,则只存储单个比特。此阶段可优化DRAM缓存访问并减少PCM访问次数。
- 在第二阶段,使用FPC算法在‘比特级’执行压缩,这进一步减少了PCM访问的次数。
7. GPU压缩技术
图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。GPU的生产商主要有NVIDIA和ATI。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ci12THr9-1651280518566)(https://ycnx.online/wp-content/uploads/2022/04/image-1651135416207.png)]
硬件线程加速技术
- 由于主内存或数据依赖导致停顿等瓶颈,GPU资源并未得到充分利用。这提供了
创建硬件线程的机会,这些硬件线程通过执行有用的工作来加速主(常规)线程。该技术生成这样的线程并管理它们的执行。这些“辅助器”的调度和执行由硬件完成,资源(例如寄存器堆)的分配由编译器完成。为了缓解内存带宽瓶颈,辅助扭曲在写入内存之前对缓存块进行压缩,并在将它们放入缓存和寄存器之前对它们进行解压缩。由于它们的数据模式不同,不同的工作负载受益于不同的压缩算法,因此,它们的技术允许使用不同的辅助扭曲来实现不同的算法。与纯硬件实现的压缩相比,该方法使用了现有的未充分利用的资源,不需要额外的专用资源。此外,压缩仅用于带宽受限的工作负载(使用静态简档识别),因为压缩对于计算资源受限的工作负载是无益的,甚至可能由于辅助翘曲开销而损害其性能。
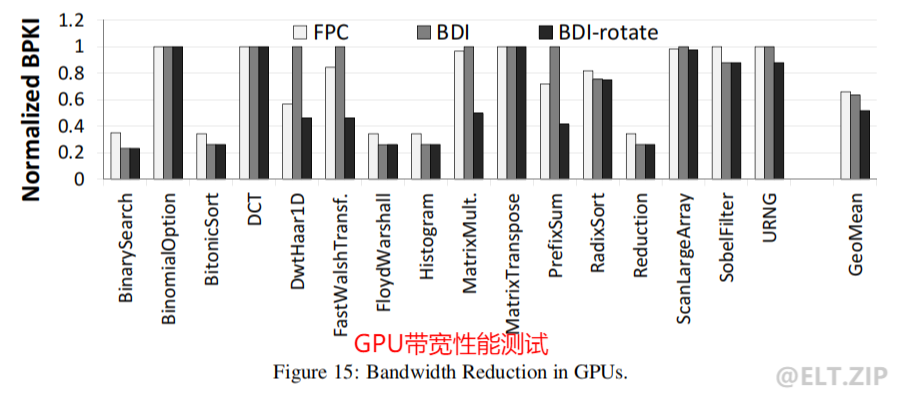
WARP级寄存器压缩技术
- 在GPU中最小的硬件单元是SP(这个术语通常使用thread来代替),而硬件上一个SM中的所有SP在物理上是分成了几个WARP(每一个WARP包含一些thread),WARP中的SP是可以同时工作的,但是执行相同的指令。
- GPU使用大型寄存器堆(RF)来
保存并发执行上下文,然而,这也使得RFS的功耗占GPU功耗的很大一部分。由于GPU WARP中的所有线程都执行相同的指令,因此寄存器堆(RF)访问也发生在WARP单元中。WARP中的线程是使用线程索引来识别的,因此,依赖于线程索引的计算对显示出很强的值相似性的寄存器数据进行操作。因此,在WARP内,两个连续线程寄存器之间的算术差异很小。
- 在此基础上,提出了一种利用BDI算法进行数据压缩的WARP级寄存器压缩技术。GPU已经将RF组织成组,在其技术中,
选择单个寄存器或单个寄存器组作为BDI算法的基准值计算剩余寄存器或存储体的Delta值。寄存器值的压缩允许在每次WARP级寄存器访问上激活更少的寄存器组,这降低了动态能量。此外,由于寄存器内容可以保存在更少的存储体中,因此可以对未使用的存储体进行电源选通,以节省泄漏能量。因此,这种技术节省了GPU的电量。
8. 带宽压缩技术
带宽压缩技术在允许进行多核扩展方面非常有成效。
假设芯片区域被划分为若干个CEA(核等效区),其中一个CEA等于一个处理器核及其一级缓存所占用的面积。
假设一个具有8个核和8个CEA的基准系统,估算在内存通信量相对于基准系统保持恒定的约束下,具有32个CEA的下一代处理器可以支持的核数。
- 在没有缓存压缩的情况下,只能支持11核;
- 相比之下,对于1.3倍、2.0倍和3.0倍的压缩比,单独使用缓存压缩可以分别支持11、13和14核,同时使用链接和缓存压缩可以分别支持13、18和24核。
这表明压缩技术在允许进行多核扩展方面可以非常有效。

9. 实际处理器中的技术
Linux
- Linux 内核提供 zswap 作为一种用于
存储交换页面的虚拟内存压缩方法。
- 当要换出内存页面时,zswap 不会将其移动到交换设备(例如磁盘),而是
将页面压缩并将其存储在系统 RAM 中动态分配的内存池中。因此,zswapp 提供了一个压缩的回写缓存功能。只有当 RAM 空间不足时,LRU(最近最少使用)页面才会被逐出并移动到交换设备。这会延迟甚至可能避免回写到交换设备,从而显著降低系统的 I/O 开销。
IBM
- IBM 的主动内存扩展 (AME) 技术使用压缩方法来扩展 POWER7 系统的内存容量。
- AME 可以减少逻辑分区 (LPAR) 的物理内存需求,从而允许在单个系统中整合多个逻辑分区。 AME 还可用于增加 LPAR 的有效内存容量,而无需增加其使用的物理内存。可以有选择地为系统上的一个或多个 LPAR 启用 AME。压缩 LPAR 的一部分内存会导致形成两个池,即一个压缩池和一个未压缩池,它们的大小是根据工作负载要求来控制的。
Apple OS X
- Apple OS X 提供了“压缩内存”方法,它对不活动或最不重要的应用程序进行压缩以释放内存空间。对于压缩,使用 WKdm 压缩算法 。压缩内存功能
对于使用 SSD(固态驱动器)存储的移动产品特别有用。与将数据交换到磁盘的替代方案会产生大量的处理器和磁盘开销相比,压缩会导致更小的延迟并通过允许处理器和磁盘更频繁地断电来减少电池消耗。压缩内存功能也可以在顶部的虚拟内存,并且可以受益于多核上的并行处理以实现高性能。
参考文献
[1] J. Park,J. Jung, K. Yi,and C.-M. Kyung, “Static energyminimization of 3D stacked L2 cache with selective cachecompression,” inInternationalConferenceonVeryLargeScaleIntegration(VLSI-SoC), 2013, pp. 228–233.
[2] J.-S. Lee, W.-K. Hong, and S.-D. Kim, “Design and evaluationof a selective compressed memory system,” inInternationalConferenceon ComputerDesign (ICCD), 1999, pp. 184–191.
[3] M. J. Khurshid and M. Lipasti, “Data compression for ther-mal mitigation in the Hybrid Memory Cube,” inInternationalConferenceon ComputerDesign (ICCD), 2013, pp. 185–192.
[4] J. Kong and H. Zhou, “Improving privacy and lifetime ofPCM-based main memory,” inInternationalConferenceonDe-pendableSystems and Networks (DSN), 2010, pp. 333–342.[18] A. R. Alameldeen and D. A. Wood, “Adaptive cache com-pression for high-performance processors,” inISCA, 2004, pp.212–223.
[5] E. G. Hallnor and S. K. Reinhardt, “A unified compressedmemory hierarchy,” inHPCA, 2005, pp. 201–212.
[6] F. Douglis, “The compression cache: Using on-line compres-sion to extend physical memory.” inUSENIXWinterConfer-ence, 1993, pp. 519–529.
[7] J.-S. Lee, W.-K. Hong, and S.-D. Kim, “Design and evaluationof a selective compressed memory system,” inInternationalConferenceon ComputerDesign (ICCD), 1999, pp. 184–191.
[8] B. Abali, H. Franke, D. E. Poff, R. Saccone, C. O. Schulz,L. M. Herger, and T. B. Smith, “Memory expansion technology(MXT): software support and performance,”IBMJournalofResearch and Development, vol. 45, no. 2, pp. 287–301, 2001.
[9] G. Pekhimenko, V. Seshadri, Y. Kim, H. Xin, O. Mutlu, P. B.Gibbons, M. A. Kozuch, and T. C. Mowry, “Linearly com-pressed pages: A low-complexity, low-latency main memorycompression framework,” inMICRO, 2013, pp. 172–184.
[10] N. Kim, T. Austin, and T. Mudge, “Low-energy data cacheusing sign compression and cache line bisection,” in2ndAnnual Workshop onMemory Performance Issues (WMPI), 2002.
[11] J.-S. Lee, W.-K. Hong, and S.-D. Kim, “An on-chip cachecompression technique to reduce decompression overhead anddesign complexity,”JournalofsystemsArchitecture, vol. 46,no. 15, pp. 1365–1382, 2000.
[12] S. Mittal, J. S. Vetter, and D. Li, “A Survey Of Architectural Ap-proaches for Managing Embedded DRAM and Non-volatileOn-chip Caches,”IEEE TPDS, 2014.
[13 图形处理器_百度百科]
[14] Yang L, Dick R P, Lekatsas H, et al. Online memory compression for embedded systems[J]. ACM Transactions on Embedded Computing Systems (TECS), 2010, 9(3): 1-30.
[15] Pekhimenko G, Mowry T C, Mutlu O. Linearly compressed pages: A main memory compression framework with low complexity and low latency[C]//2012 21st International Conference on Parallel Architectures and Compilation Techniques (PACT). IEEE, 2012: 489-489.
[16] Ozturk O, Kandemir M. ILP-Based energy minimization techniques for banked memories[J]. ACM Transactions on Design Automation of Electronic Systems (TODAES), 2008, 13(3): 1-40.
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 3246
3246











 淘帖
淘帖
 显身卡
显身卡




