语音识别的部分我们使用whisper来完成。和之前一样,我们先从官方示例入手。
先下载对应仓库,按照仓库中的要求,下载完后要切换到release分支。
cd /data/project
git clone https:
cd whisper-TPU_py
git checkout release
接下来下载对应的模型文件
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/Whisper/tar_downloader.sh
bash tar_downloader.sh
tar -xvf Whisper_bmodel.tar.gz
下载完成后,我们需要将bmodel文件夹拷贝出来
mv Whisper_bmodel/bmodel ./
下面,开始配置环境
export LD_LIBRARY_PATH=/opt/sophon/libsophon-0.5.0/lib:$LD_LIBRARY_PATH
python3 -m venv whisper_env --system-site-packages
source whisper_env/bin/activate
pip3 install -r requirements.txt
python3 setup.py install
完成后,可以尝试运行以下官方提供的测试命令:
bmwhisper ./test/demo.wav --model base --bmodel_dir ./bmodel/ --chip_mode soc
看到以下结果,说明模型已经可以正常运行:

由于官方教程到此为止,后面具体的用法就需要我们来自行探索了。
可以看到仓库根目录中有一个run_demo.sh的脚本,经过测试这个脚本效果和上述代码类似。打开脚本,可以看到脚本中是运行了run.py这个文件,而这个文件中又仅仅是调用了bmwhisper文件夹里transcribe.py文件中的cli()函数。说明实际的代码应该在这个函数中。
通过解读这个函数,我们可以知道这个函数的作用是先获取到运行参数,然后把所有的参数撞到了一个叫做args的变量中,再将这个变量喂给load_model,最后再调用transcribe函数得到结果。
那我们再去transcribe函数看一下,他的返回值是什么样:

可以看到,他返回的值是一个字典,其中text就是识别到的文字。
那么想使用的话就非常简单了,只需要把cli函数稍作修改即可。我们可以把必须参数audio改成可选参数,然后给函数添加一个传入变量,再把该变量赋给args中的audio字段。对于其他参数,如果有需要我们可以修改一下他的默认值。比如语言默认值可以直接修改为中文。最后将result["text"]返回,就可以把cli函数改成一个可以很方便在其他函数中调用的方法了。修改后的函数如下:
def cli(audio):
start_time = time.time()
from . import available_models
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--audio", nargs="+", type=str, help="audio file(s) to transcribe")
parser.add_argument("--model", default="small", choices=available_models(), help="name of the Whisper model to use")
parser.add_argument("--model_dir", type=str, default=None, help="the path to save model files; uses ~/.cache/whisper by default")
parser.add_argument("--bmodel_dir", type=str, default="./bmodel", help="the path to save model files; uses ./bmodel by default")
parser.add_argument("--output_dir", "-o", type=str, default=".", help="directory to save the outputs")
parser.add_argument("--output_format", "-f", type=str, default="all", choices=["txt", "vtt", "srt", "tsv", "json", "all"], help="format of the output file; if not specified, all available formats will be produced")
parser.add_argument("--verbose", type=str2bool, default=True, help="whether to print out the progress and debug messages")
parser.add_argument("--task", type=str, default="transcribe", choices=["transcribe", "translate"], help="whether to perform X->X speech recognition ('transcribe') or X->English translation ('translate')")
parser.add_argument("--language", type=str, default="Chinese", choices=sorted(LANGUAGES.keys()) + sorted([k.title() for k in TO_LANGUAGE_CODE.keys()]), help="language spoken in the audio, specify None to perform language detection")
parser.add_argument("--temperature", type=float, default=0, help="temperature to use for sampling")
parser.add_argument("--best_of", type=optional_int, default=5, help="number of candidates when sampling with non-zero temperature")
parser.add_argument("--beam_size", type=optional_int, default=5, help="number of beams in beam search, only applicable when temperature is zero")
parser.add_argument("--patience", type=float, default=None, help="optional patience value to use in beam decoding, as in https://arxiv.org/abs/2204.05424, the default (1.0) is equivalent to conventional beam search")
parser.add_argument("--length_penalty", type=float, default=None, help="optional token length penalty coefficient (alpha) as in https://arxiv.org/abs/1609.08144, uses simple length normalization by default")
parser.add_argument("--suppress_tokens", type=str, default="-1", help="comma-separated list of token ids to suppress during sampling; '-1' will suppress most special characters except common punctuations")
parser.add_argument("--initial_prompt", type=str, default=None, help="optional text to provide as a prompt for the first window.")
parser.add_argument("--condition_on_previous_text", type=str2bool, default=True, help="if True, provide the previous output of the model as a prompt for the next window; disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop")
parser.add_argument("--temperature_increment_on_fallback", type=optional_float, default=0.2, help="temperature to increase when falling back when the decoding fails to meet either of the thresholds below")
parser.add_argument("--compression_ratio_threshold", type=optional_float, default=2.4, help="if the gzip compression ratio is higher than this value, treat the decoding as failed")
parser.add_argument("--logprob_threshold", type=optional_float, default=-1.0, help="if the average log probability is lower than this value, treat the decoding as failed")
parser.add_argument("--no_speech_threshold", type=optional_float, default=0.6, help="if the probability of the <|nospeech|> token is higher than this value AND the decoding has failed due to `logprob_threshold`, consider the segment as silence")
parser.add_argument("--word_timestamps", type=str2bool, default=False, help="(experimental) extract word-level timestamps and refine the results based on them")
parser.add_argument("--prepend_punctuations", type=str, default="\"\'“¿([{-", help="if word_timestamps is True, merge these punctuation symbols with the next word")
parser.add_argument("--append_punctuations", type=str, default="\"\'.。,,!!??::”)]}、", help="if word_timestamps is True, merge these punctuation symbols with the previous word")
parser.add_argument("--highlight_words", type=str2bool, default=False, help="(requires --word_timestamps True) underline each word as it is spoken in srt and vtt")
parser.add_argument("--max_line_width", type=optional_int, default=None, help="(requires --word_timestamps True) the maximum number of characters in a line before breaking the line")
parser.add_argument("--max_line_count", type=optional_int, default=None, help="(requires --word_timestamps True) the maximum number of lines in a segment")
parser.add_argument("--threads", type=optional_int, default=0, help="number of threads used by torch for CPU inference; supercedes MKL_NUM_THREADS/OMP_NUM_THREADS")
parser.add_argument("--padding_size", type=optional_int, default=448, help="max pre-allocation size for the key-value cache")
parser.add_argument("--chip_mode", default="soc", choices=["pcie", "soc"], help="name of the Whisper model to use")
parser.add_argument("--loop_profile", action="store_true", help="whether to print loop times")
args = parser.parse_args().__dict__
args["audio"] = [audio]
args["model_name"] = args.pop("model")
output_dir: str = args.pop("output_dir")
output_format: str = args.pop("output_format")
loop_profile = args.pop("loop_profile")
os.makedirs(output_dir, exist_ok=True)
model_name = args["model_name"]
if model_name.endswith(".en") and args["language"] not in {"en", "English"}:
if args["language"] is not None:
warnings.warn(
f"{model_name} is an English-only model but receipted '{args['language']}'; using English instead."
)
args["language"] = "en"
temperature = args.pop("temperature")
if (increment := args.pop("temperature_increment_on_fallback")) is not None:
temperature = tuple(np.arange(temperature, 1.0 + 1e-6, increment))
else:
temperature = [temperature]
if (threads := args.pop("threads")) > 0:
torch.set_num_threads(threads)
from . import load_model
model = load_model(args)
pop_list = ["model_name", "model_dir", "bmodel_dir", "chip_mode"]
for arg in pop_list:
args.pop(arg)
writer = get_writer(output_format, output_dir)
word_options = ["highlight_words", "max_line_count", "max_line_width"]
if not args["word_timestamps"]:
for option in word_options:
if args[option]:
parser.error(f"--{option} requires --word_timestamps True")
if args["max_line_count"] and not args["max_line_width"]:
warnings.warn("--max_line_count has no effect without --max_line_width")
writer_args = {arg: args.pop(arg) for arg in word_options}
for audio_path in args.pop("audio"):
print(audio_path)
model.init_cnt()
print()
print("{:=^100}".format(f" Start "))
print(f"### audio_path: {os.path.basename(audio_path)}")
audio_start_time = time.time()
result = transcribe(model, audio_path, temperature=temperature, **args)
writer(result, audio_path, writer_args)
cpu_time = time.time() - audio_start_time - model.time
if loop_profile:
model.print_cnt()
print()
print(f"Total tpu inference time: {model.time}s")
print(f"Total cpu inference time: {cpu_time}s")
print(f"Total time: {cpu_time + model.time}s")
model.time = 0
print("{:-^100}".format(f" Total time: {time.time() - start_time} seconds "))
return (result["text"])
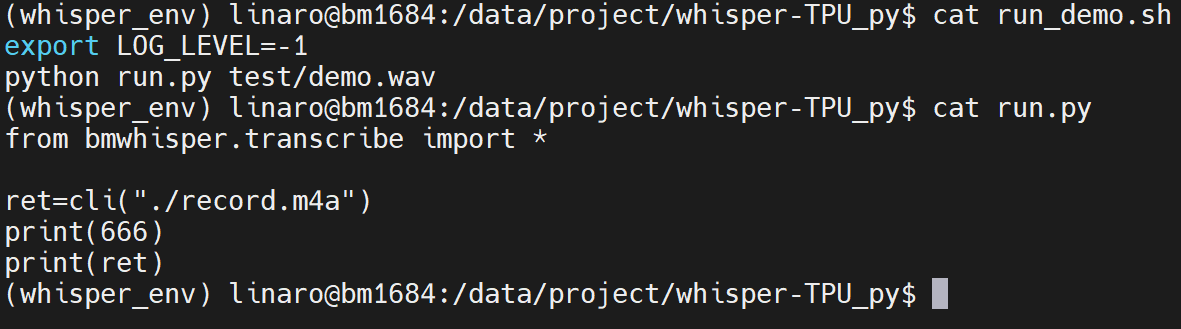
稍微修改下run.py文件,看看能不能方便调用:
from bmwhisper.transcribe import cli
ret=cli("./record.m4a")
print("Start")
print(ret)
自己随便录了一句话,运行以下,看到以下输出,我们已经可以轻松调用whisper。

 电子发烧友论坛
电子发烧友论坛 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 1096
1096




 淘帖
淘帖





