图像识别也属于是AI的一个非常基本的经典应用。在主打AI功能的BM1684X上自然也是得到了广泛的支持。
算能官方提供了一个叫做Radxa-Model-Zoo的仓库,这个仓库里包含了许多AI方面的应用范例,当然也包含多个图像识别模型。
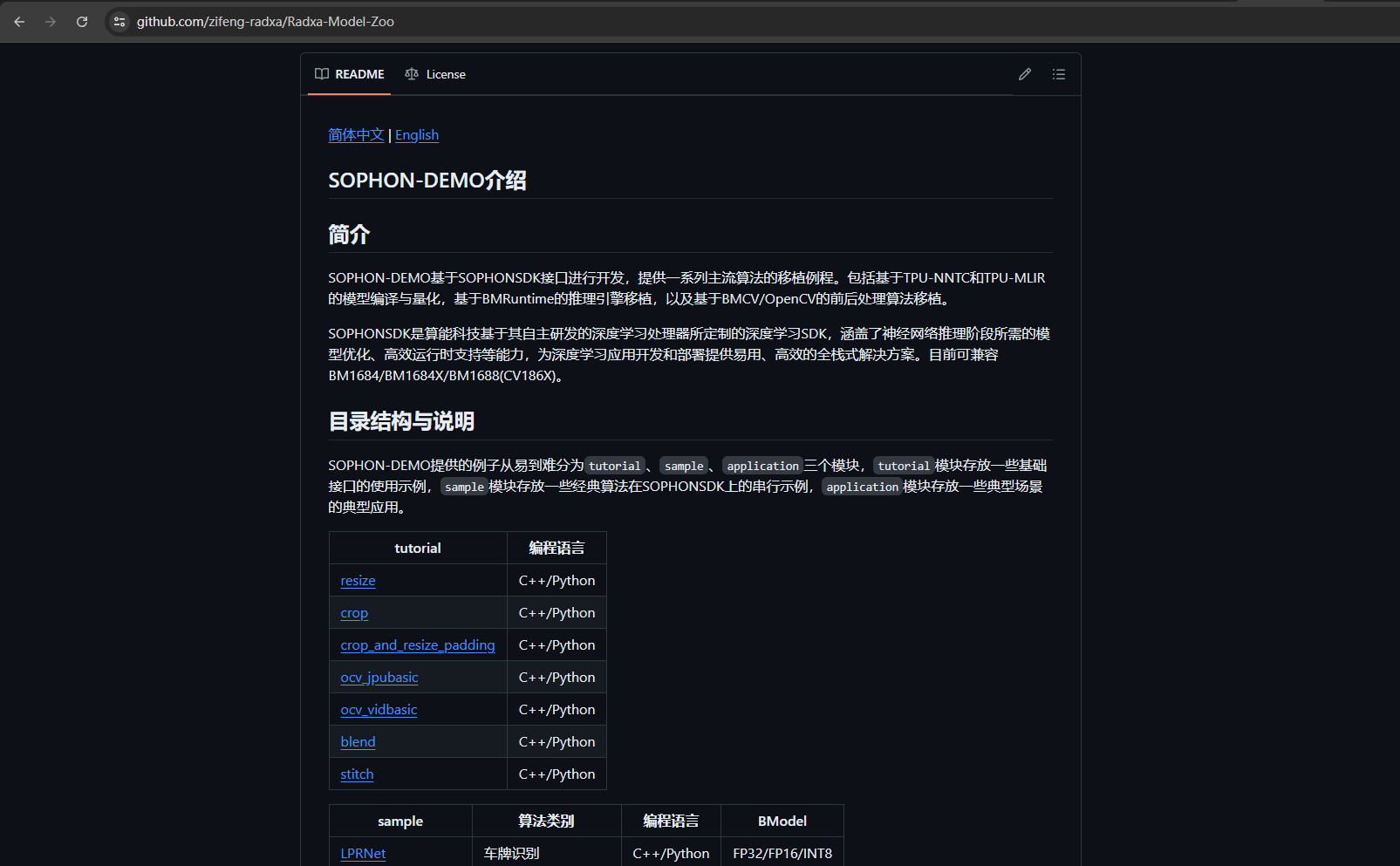
这个项目中,我会使用YOLOv8来完成图像识别。
先转到project文件夹下,克隆下整个仓库:
cd /data/project
git clone https:
接下来,进入到项目文件夹中。由于我使用的是预加载模型,因此在配置环境前我们需要先把模型和对应的测试文件下载下来。
cd ./Radxa-Model-Zoo/sample/YOLOv8_det
sudo apt install unzip
chmod -R +x scripts/
./scripts/download.sh
下载完成后,应该可以看到文件夹中出现以下模型:
./models
├── BM1684
│ ├── yolov8s_fp32_1b.bmodel
│ ├── yolov8s_int8_1b.bmodel
│ ├── yolov8s_int8_4b.bmodel
│ ├── yolov8s_opt_fp32_1b.bmodel
│ ├── yolov8s_opt_int8_1b.bmodel
│ └── yolov8s_opt_int8_4b.bmodel
├── BM1684X
│ ├── yolov8s_fp32_1b.bmodel
│ ├── yolov8s_fp16_1b.bmodel
│ ├── yolov8s_int8_1b.bmodel
│ ├── yolov8s_int8_4b.bmodel
│ ├── yolov8s_opt_fp32_1b.bmodel
│ ├── yolov8s_opt_fp16_1b.bmodel
│ ├── yolov8s_opt_int8_1b.bmodel
│ └── yolov8s_opt_int8_4b.bmodel
├── BM1688
│ ├── yolov8s_fp32_1b.bmodel
│ ├── yolov8s_fp16_1b.bmodel
│ ├── yolov8s_int8_1b.bmodel
│ ├── yolov8s_int8_4b.bmodel
│ ├── yolov8s_fp32_1b_2core.bmodel
│ ├── yolov8s_fp16_1b_2core.bmodel
│ ├── yolov8s_int8_1b_2core.bmodel
│ ├── yolov8s_int8_4b_2core.bmodel
│ ├── yolov8s_opt_fp32_1b.bmodel
│ ├── yolov8s_opt_fp16_1b.bmodel
│ ├── yolov8s_opt_int8_1b.bmodel
│ ├── yolov8s_opt_int8_4b.bmodel
│ ├── yolov8s_opt_fp32_1b_2core.bmodel
│ ├── yolov8s_opt_fp16_1b_2core.bmodel
│ ├── yolov8s_opt_int8_1b_2core.bmodel
│ └── yolov8s_opt_int8_4b_2core.bmodel
├── CV186X
│ ├── yolov8s_fp32_1b.bmodel
│ ├── yolov8s_fp16_1b.bmodel
│ ├── yolov8s_int8_1b.bmodel
│ ├── yolov8s_int8_4b.bmodel
│ ├── yolov8s_opt_fp32_1b.bmodel
│ ├── yolov8s_opt_fp16_1b.bmodel
│ ├── yolov8s_opt_int8_1b.bmodel
│ └── yolov8s_opt_int8_4b.bmodel
│── torch
│ └── yolov8s.torchscript.pt
└── onnx
├── yolov8s.onnx
├── yolov8s_opt.onnx
├── yolov8s_qtable_fp16
├── yolov8s_qtable_fp32
├── yolov8s_opt_qtable_fp16
└── yolov8s_opt_qtable_fp32
以及训练和测试数据:
./datasets
├── test
├── test_car_person_1080P.mp4
├── coco.names
├── coco128
└── coco
├── val2017_1000
└── instances_val2017_1000.json
接下来,我们开始配置python环境。创建虚拟环境时,不要忘记链接系统包,这样才可以支持sophon相关的包。
python3 -m venv yolo_venv --system-site-packages
source yolo_venv/bin/activate
pip3 install opencv-python-headless
接着我们可以开始测试一下模型。运行下面测试命令:
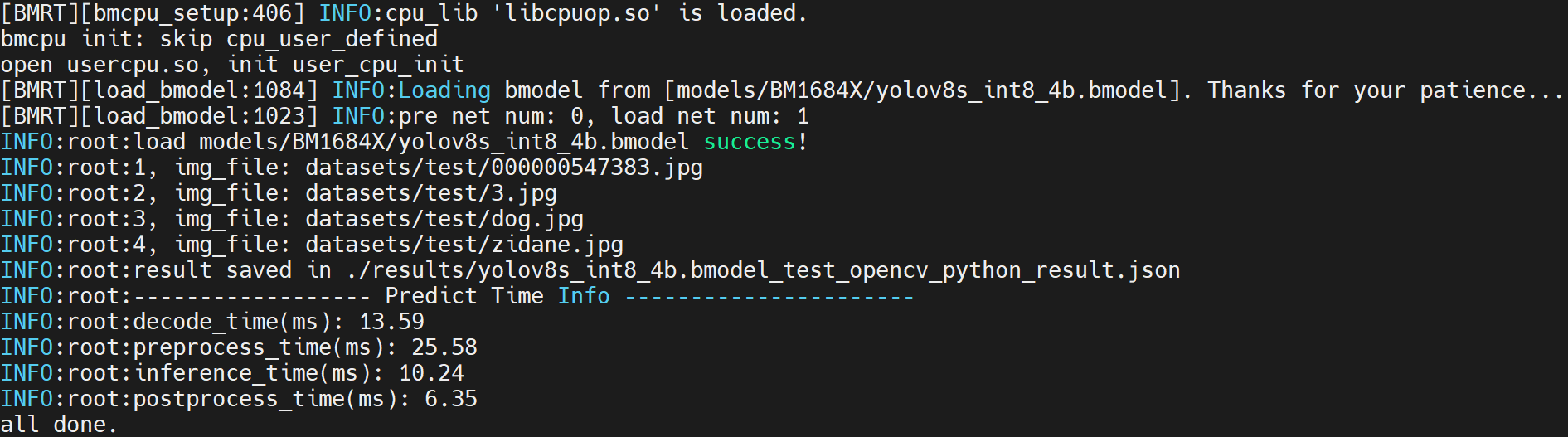
python3 python/yolov8_opencv.py --input datasets/test --bmodel models/BM1684X/yolov8s_int8_4b.bmodel --dev_id 0 --conf_thresh 0.25 --nms_thresh 0.7
如果看到下面命令返回,则说明运行成功:
如果看到下面这条报错,则说明没有在当前运行环境中配置库路径。
ImportError: libbmrt.so.1.0: cannot open shared object file: No such file or directory
修复方法也很简单,运行以下命令即可:
export LD_LIBRARY_PATH=/opt/sophon/libsophon-0.5.0/lib:/opt/sophon/sophon-sail/lib/:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/OpenBLAS/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/sophon/sophon-sail/lib/:$LD_LIBRARY_PATH
检测完成后,可以在./results文件夹下看到结果,其中json文件记录了检测到的所有物体;而images文件夹下则是融合了结果框的图片,如下:




同样的,运行成功后,我们来分析一下示例代码,看看在接下来的项目中如何使用。
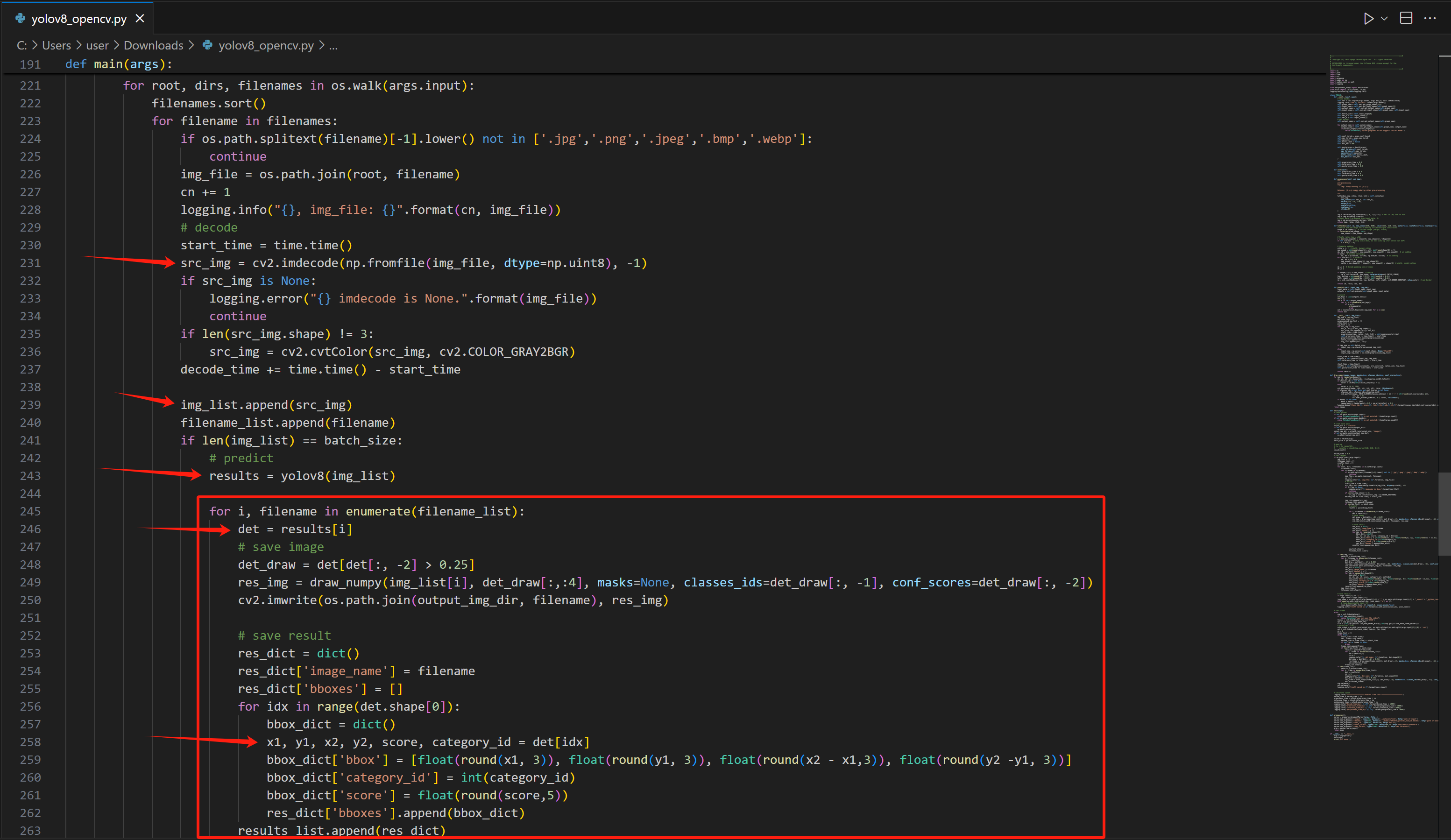
可以看到,在yolov8_opencv.py中,主要应用的代码写在了main函数中。其中先使用CV2将图片文件解码,然后装入一个列表,再将这个列表作为参数放入yolov8模型中。识别完成的结果放在results中,这是一个列表,每一个元素代表一个识别到的物体,因此使用循环读出。每一个物体对应的属性都可以从det这个列表中读出。因此我们在后续项目使用时,只要用此方法就可以得到所有识别到的结果。
 电子发烧友论坛
电子发烧友论坛 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 1328
1328






 淘帖
淘帖





