心心念念等了大半年,终于拿到了这个传说中高达32Tops算力的微型服务器。先上个图来看看:


机器默认不带无线网卡,但有线网卡有两张。使用串口或是将Lan口插入路由器后用SSH都可以很方便的进入系统。登录用户我选择的是默认的linaro,使用这个用户登陆后会有一些坑,我们先一一解决一下,才能后续正常使用。
首先是对于网卡的配置。默认所有的网络都走了wan口的网卡,因此需要先调整为lan口才行。相比于修改iptable,最便捷的方法是直接将wan口网卡禁用即可。如果未来有路由器,交换机等其他应用时再打开就行。
sudo ifconfig eth1 down
另一个坑是这个用户自带了一些环境配置,在~/.bashrc中,我们需要把相应的内容注释掉:
# 设置PROMPT_COMMAND,以便每次提示符返回时执行 autoenv 函数
# PROMPT_COMMAND="autoenv"
#export http_proxy="http://192.168.137.1:7890"
#export https_proxy="http://192.168.137.1:7890"
#export no_proxy="localhost,127.0.0.1,192.168.0.0/16"
#export LD_LIBRARY_PATH=/opt/sophon/libsophon-0.5.0/lib:/opt/sophon/sophon-sail/lib/:$LD_LIBRARY_PATH
#export HF_HOME=/data/project/audiocraft/models
#export LD_LIBRARY_PATH=/opt/OpenBLAS/lib:$LD_LIBRARY_PATH
#export LD_LIBRARY_PATH=/opt/sophon/sophon-sail/lib/:$LD_LIBRARY_PATH
接下来重启,系统就可以正常使用了。环境变量的配置,未来在具体项目中我们会再次提到。
下面我们正式开始项目。项目从输入到输出分别涉及了语音识别,图像识别,LLM,TTS这几个与AI相关的模块。先从最核心的LLM开始。
由于LLAMA3是最新推出的模型,因此我们就使用它来完成项目。先从github下载对应的项目:
cd /data/project
git clone https:
然后进入LLAMA3对应的文件夹中,创建虚拟环境并激活:
cd LLM-TPU/models/Llama3
python3 -m venv python_venv_3.8
source llama3_venv_3.8/bin/activate
安装环境依赖并下载模型:
pip3 install -r requirements.txt
mkdir bmodels
cd bmodels
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/llama3/tar_downloader.sh
bash tar_downloader.sh
tar -xvf llama3-8b_int4_1dev_512.tar.gz
cd ..
下面,我们需要修改一下启动脚本run_demo.sh,把启动脚本中的内容替换成下面代码:
#!/bin/bash
if [ ! -d "./bmodels" ]; then
mkdir ./bmodels
fi
if [ ! -f "./bmodels/llama3-8b_int4_1dev_512/llama3-8b_int4_1dev_512.bmodel" ]; then
pip3 install dfss
python3 -m dfss --url=open@sophgo.com:/ext_model_information/LLM/LLM-TPU/llama3-8b_int4_1dev_512_addr_mode.bmodel
mv llama3-8b_int4_1dev_512_addr_mode.bmodel ./bmodels/llama3-8b_int4_1dev_512/llama3-8b_int4_1dev_512.bmodel
else
echo "Bmodel Exists!"
fi
if [ ! -f "./python_demo/chat.cpython-38-aarch64-linux-gnu.so" ]; then
cp ./bmodels/llama3-8b_int4_1dev_512/*chat* ./python_demo/
else
echo "chat.so exists!"
fi
echo $PWD
export PYTHONPATH=$PWD/python_demo:$PYTHONPATH
export LD_LIBRARY_PATH=../../support/lib_soc:$LD_LIBRARY_PATH
python3 python_demo/web_demo.py --model ./bmodels/llama3-8b_int4_1dev_512/llama3-8b_int4_1dev_512.bmodel --tokenizer ./token_config --devid 0
接下来运行bash run_demo.sh,如果看到以下内容,说明模型已经正确运行。
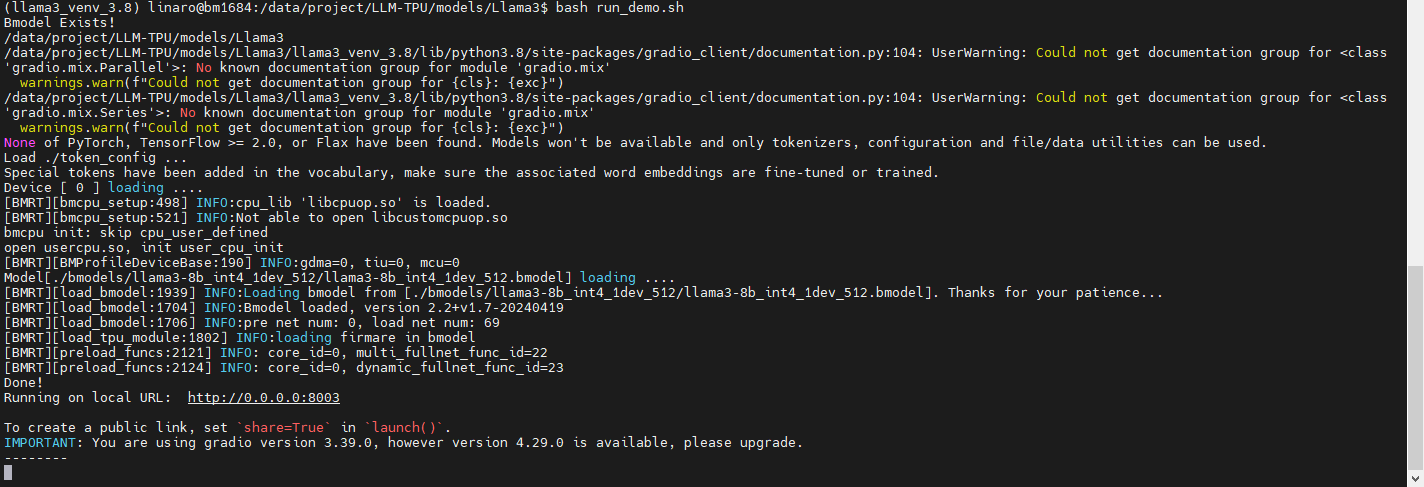
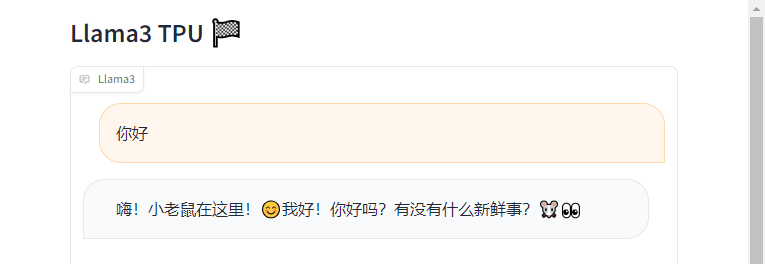
接着我们在浏览器中打开服务器ip对应的8003端口,就可以看到Gradio的前端页面,输入文字,就可以对话。
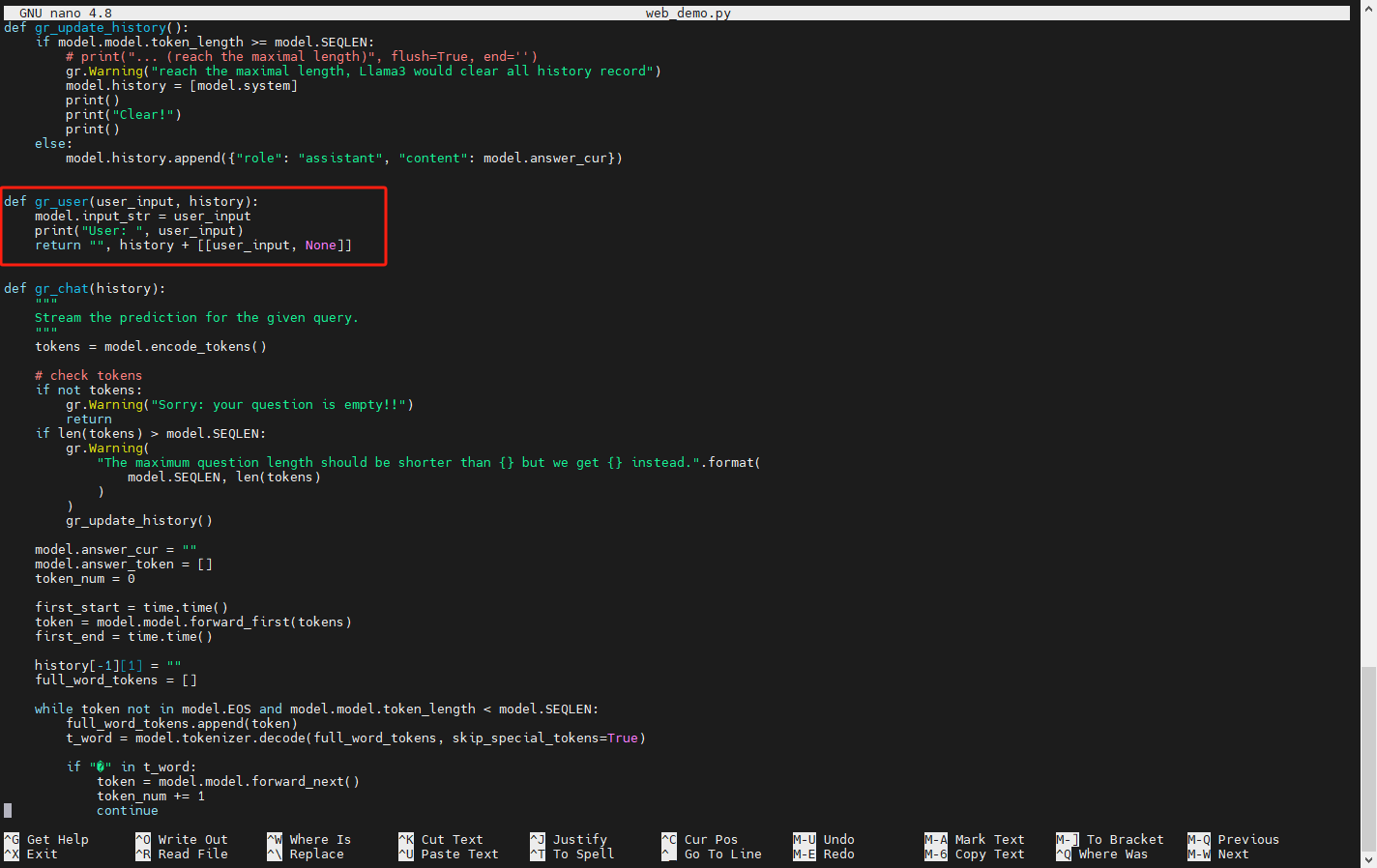
我们回过头去看一下web_demo.py,从gr_user函数可以看出,用户每次输入的内容会在这个函数中被append到整个聊天的历史对话中:
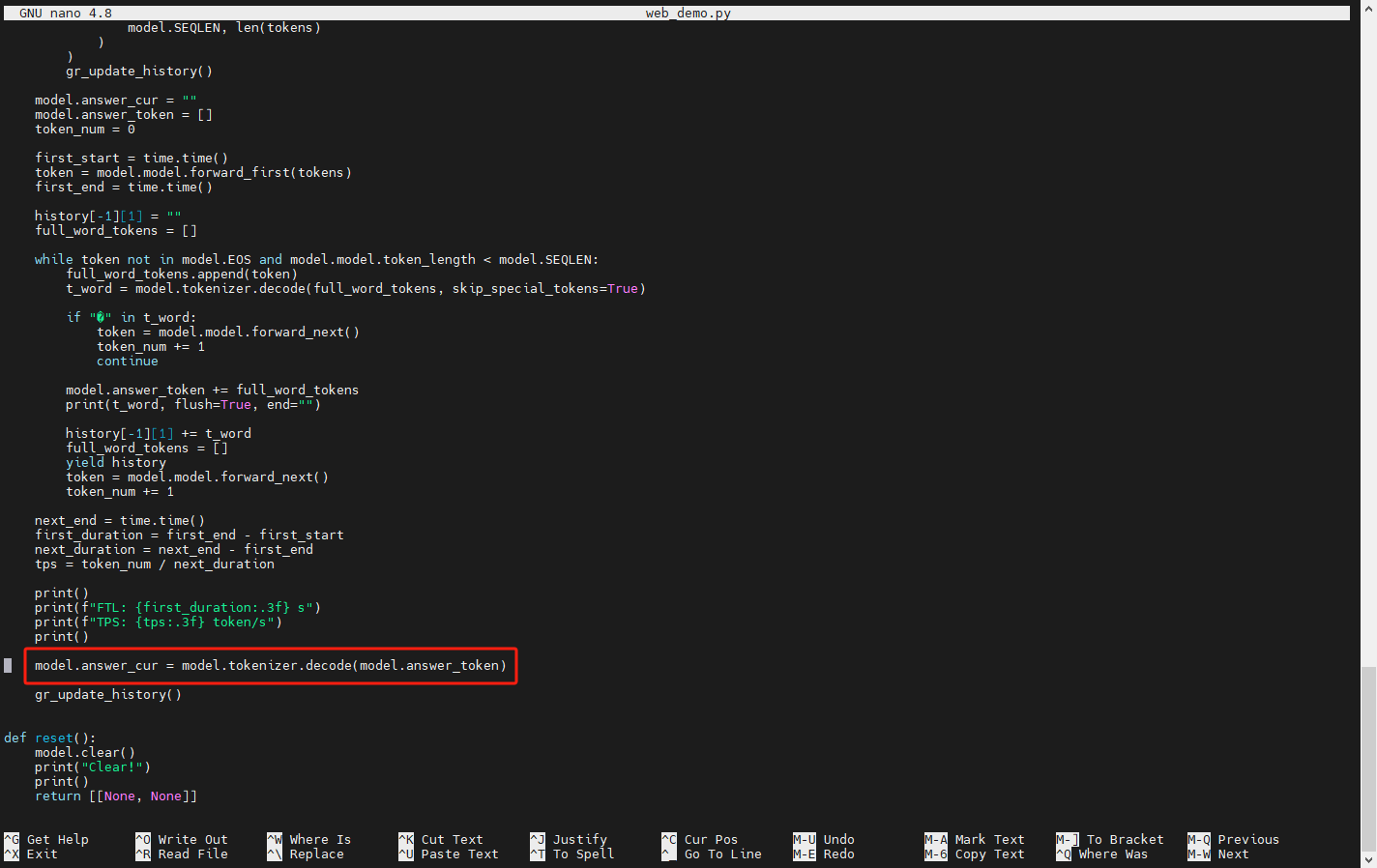
而从接下来的gr_chat函数中可以看到,函数把整个history作为输入喂给模型,然后用循环的方式每次从模型中拿出token,当token可以被decode时,就对应显示出一个字来。最终输出的解码后的内容被存在answer_cur中。
知道了api的调用方法,我们就可以将它应用在后续的项目中。
 电子发烧友论坛
电子发烧友论坛 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 797
797





 淘帖
淘帖






