前面给大家普及了大模型的基础,但是缺乏应用的大模型是没有价值的。当然你可能使用过Kimi Chat、豆包这样的大模型工具,它们可能已经在生活中充当了我们的创作助手、咨询专家、甚至情感陪护等,但这样的应用还远远不能发挥出大模型的真正价值,我们期望大模型在更专业的生产领域发挥作用,提升生产力,引领真正的科技变革。
当前大模型被普遍看好的两个专业应用方向是RAG(Retrieval-Augmented Agenerated,检索增强生成)与Agent(AI智能体)。本篇小枣君首先尝试用通俗易懂的语言帮助大家认识RAG这一重要应用形式。

01 了解大模型的“幻觉”
在了解为什么出现RAG之前,我们首先需要了解大模型著名的“幻觉”问题。
“幻觉”指的是大模型在试图生成内容或回答问题时,输出的结果不完全正确甚至错误,即通常所说的“一本正经地胡说八道”。 这种“幻觉”可以体现为对事实的错误陈述与编造、错误的复杂推理或者在复杂语境下处理能力不足等。其主要原因来自于:
(1)训练知识存在偏差:老师教错了,学生自然对不了。
在训练大模型时输入的海量知识可能包含错误、过时,甚至带有偏见的信息。这些信息在被大模型学习后,就可能在未来的输出中被重现。
(2)过度泛化地推理:自作聪明,以偏概全了。
大模型尝试通过大量的语料来学习人类语言的普遍规律与模式,这可能导致“过度泛化”的现象,即把普通的模式推理用到某些特定场景,就会产生不准确的输出。
(3)理解存在局限性:死记硬背,加上问题太难了。
大模型并没有真正“理解”训练知识的深层含义,也不具备人类普遍的常识与经验,因此可能会在一些需要深入理解与复杂推理的任务中出错。
(4)缺乏特定领域的知识:没学过,瞎编个答案蒙一下。
通用大模型就像一个掌握了大量人类通用知识且具备超强记忆与推理能力的优秀学生,但可能不是某个垂直领域的专家(比如医学或者法律专家)。当面临一些复杂度较高的领域性问题或私有知识相关的问题时(比如介绍企业的某个新产品),它就可能会编造信息并将其输出。
当然,除了“幻觉”问题,大模型还存在知识落后、输出难以解释、输出不确定等一些问题。这也决定了大模型在大规模商业生产应用中会面临着挑战:很多时候我们不仅需要理解力和创造力,还需要极高的准确性(不仅要会写作文,还要会准确解答数学题)。
02 RAG如何优化“幻觉”问题
RAG,正是为了尽可能地解决大模型在实际应用中面临的一些问题,特别是“幻觉”问题而诞生的,也是最重要的一种优化方案。其基本思想可以简单表述如下:
将传统的生成式大模型与实时信息检索技术相结合,为大模型补充来自外部的相关数据与上下文,以帮助大模型生成更丰富、更准确、更可靠的内容。这允许大模型在生成内容时可以依赖实时与个性化的数据和知识,而不只是依赖训练知识。简单的说:RAG给大模型增加了一个可以快速查找的知识外挂。
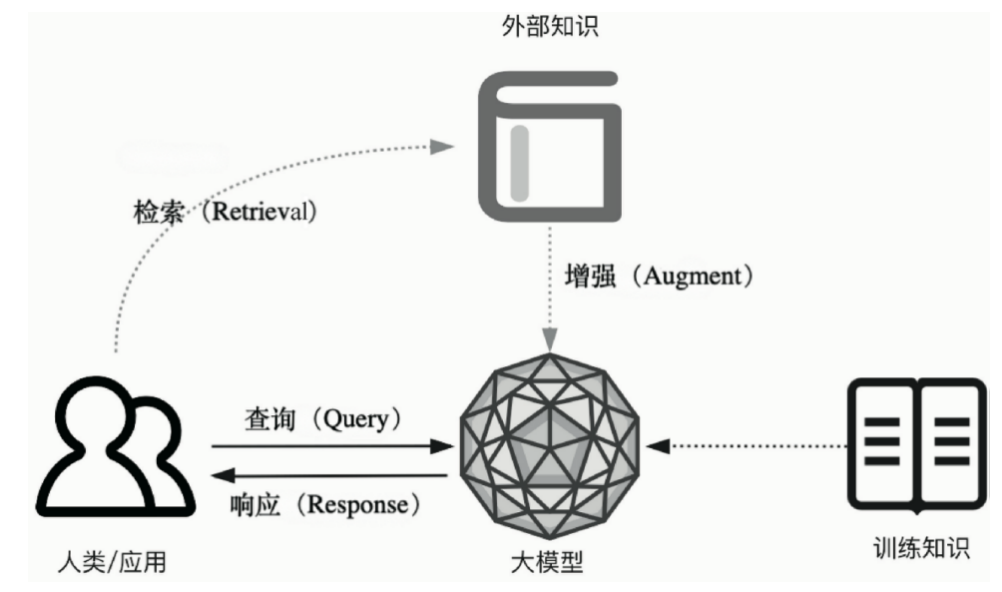
用一个例子帮助理解RAG的概念:
如果把大模型比喻成一个经过大量知识与技能训练的优秀学生,把大模型响应的过程比喻成考试,那么这个优秀学生在考试时仍然可能会遇到没有掌握的知识,从而编造答案(幻觉)。
RAG就是在这个学生考试时临时给他的一本参考书。我们可以要求他在考试时尽量参考这本书作答,那么在遇到与这本书中的知识相关的问题时,他的得分是不是就高多了呢?
03 模拟简单的RAG场景
假如你需要开发一个在线的自助产品咨询工具,允许客户使用自然语言进行交互式的产品问答,比如“请介绍一下您公司这款产品与××产品的不同之处”。为了让客户有更好的体验,你决定使用大模型来构造这样的咨询功能并将其嵌入公司的官方网站。如果你直接使用通用大模型,那么结果很可能如图1-10所示。
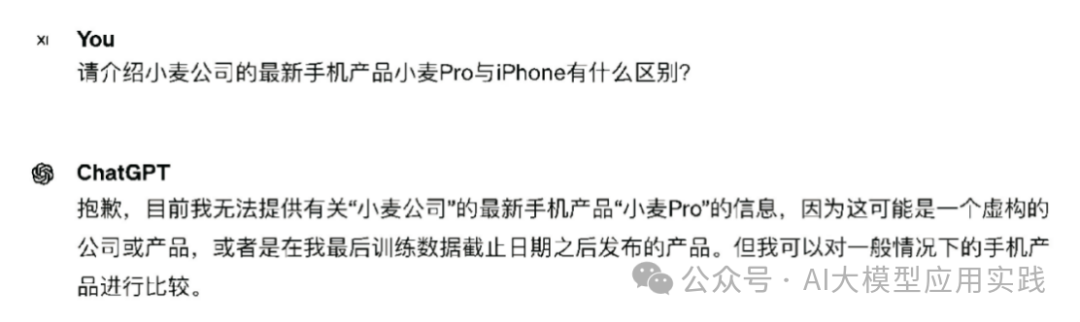
不出意外,大模型显然不具备贵公司的最新手机产品知识,因此无法回答客户的问题(有时候可能会尝试编造答案)。现在,如果你使用RAG的思想,那么可以先从企业私有的知识库中检索出下面一段相关的补充知识。

你把检索出的补充知识组装到提示词中,将其输入大模型,并要求大模型基于提供的知识来回答你的问题。大模型很聪明地“吸收”了补充的外部知识,并结合自己已经掌握的知识,成功推理并给出了答案:

是的,RAG本质上就是一种借助“外挂”的提示工程,但绝不仅限于此。因为在这里简化了很多细节,只是为了展示RAG最核心的思想:给大模型补充外部知识以提高输出答案的质量。
04 RAG与模型微调
要想提高大模型在特定行业与场景中输出的适应性与准确性,除了使用RAG,还可以使用自己的数据对大模型进行微调。简单地说,微调就是对基础模型在少量(相对于预训练的数据量来说)的、已标注的数据上进行再次训练与强化学习,以使得模型更好地适应特定的场景与下游任务。 显然,微调是另外一种给大模型“灌输”新知识的方法。两者的主要差异在于:
以前面的例子来说明微调和RAG的区别:
如果大模型是一个优秀学生,正在参加一门考试,但是这门考试中有很多知识是这位学生没有学习过的,现在使用RAG和微调两种方法对这位学生提供帮助。
- RAG:在考试时给他提供某个领域的参考书,要求他现学现用,自己翻书理解后给出答案。
- 模型微调:在考试前一天对他进行突击辅导,使他掌握了新的领域知识,然后让他参加考试。
无法确切地说在什么场景中必须使用RAG、在什么场景中必须使用微调。结合当前的一些研究及普遍的测试结果,可以认为在以下场景中更适合考虑微调的方案(在不考虑成本的前提下):
(1)需要注入较大数据量且相对稳定、迭代周期较长的领域知识;需要形成一个相对通用的领域大模型用于对外服务或者运营。
(2)执行需要极高准确率的部分关键任务,且其他手段无法满足要求,此时需要通过高效微调甚至全量微调来提高对这些任务的输出精度,比如医疗诊断。
(3)在采用提示工程、RAG等技术后,无法达到需要的指令理解准确、输出稳定或其他业务目标。
在除此之外的很多场景中,可以优先考虑使用RAG来增强大模型生成。当然,在实际条件允许的前提下,两者的融合应用或许是未来更佳的选择。
05 初步认识RAG架构
最后,我们从技术层来看一个最基础、最常见的RAG应用的逻辑架构与流程。
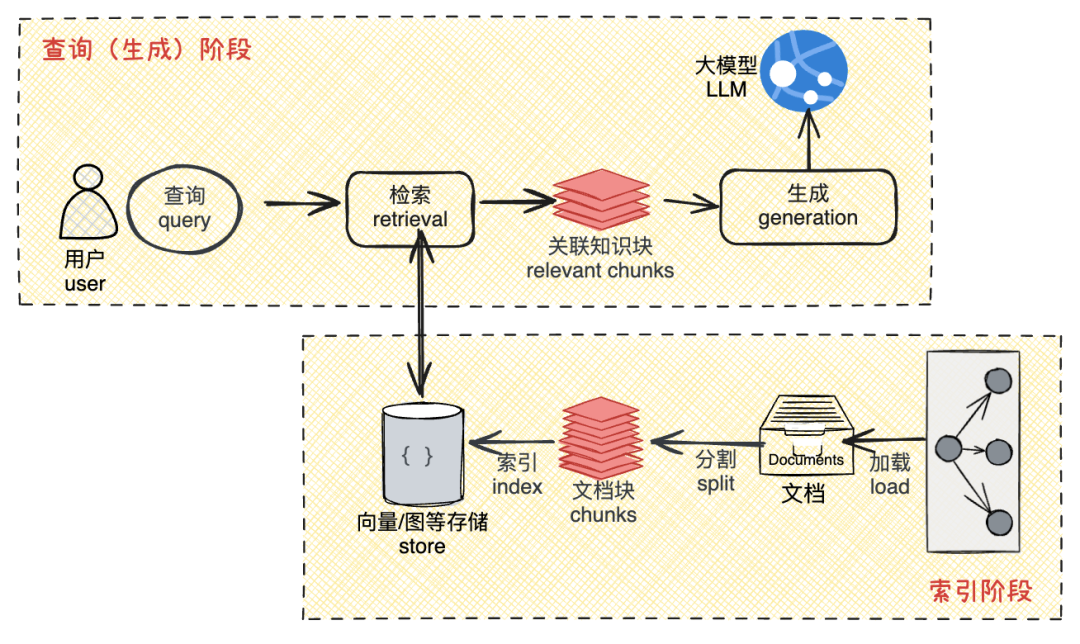
注意:在这张图中仅展示了一个最小粒度的RAG应用的基础原理。通常情况下,可以把一个简单的RAG应用从整体上分为数据索引(Indexing)与数据查询(Query)两个大的阶段,而在每个阶段都包含不同的处理环节。以上面的举例来解释:
- 索引阶段就是编写考试时需要的参考书,这本书要容易快速查找特定知识。
- 查询阶段就是考试时使用这本书的过程,先查找参考资料,然后解答问题。
在实际RAG应用中,对于不同的应用场景、客观条件、工程要求,会有更多的模块、架构与流程的优化设计,以应对众多的技术细节与挑战。比如,自然语言表达的输入问题可能千变万化,你从哪里检索对应的外部知识?你需要用怎样的索引来查询外部知识?你怎样确保补充的外部知识是回答这个问题最需要的呢?就像上面例子中的学生,如果考试的知识点是英语语法,你却给他一本《微积分》,那显然是于事无补的。
诸如这一类的问题都属于更深入的高级RAG模块与优化的范畴,感兴趣的同学可以自行学习,这里我们推荐一本非常全面的RAG应用的学习书籍:

申请时间
2024年12月4日——2024年1月4日
活动参与方式
1、在本帖下方留言回帖说说你想要这本书的理由15字以上。
2、我们将从本帖留言中挑选4位幸运者赠送此书籍,共赠送4本。
3、请在收到书籍后2个星期内提交不少于2篇试读报告要求300字以上图文并茂。
4、试读报告发表在电子发烧友论坛>>社区活动专版标题名称必须包含 【「基于大模型的RAG应用开发与优化」阅读体验】+自拟标题
注意事项
1、活动期间如有作弊、灌水等违反电子发烧友论坛规则的行为一经发现将立即取消获奖资格
2、活动结束后获奖名单将在论坛公示请活动参与者尽量完善个人信息如管理员无法联系到选中的评测者则视为自动放弃。
3、申请人收货后14天内未完成书评无权将书籍出售或转赠给他人。如无法在收货后14天内提交书评请将书籍退回电子发烧友论坛运费自理。
4、如有问题请咨询工作人员(微信:elecfans123)。
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 淘帖
淘帖 2683
2683






