本期评测名单如下
谢先生、黄一帅哥、ele2022、jf_34040148
请以上几位大佬联系工作人员(微信:elecfans123)领取书籍进行评测,如在5个工作日内未联系,视为放弃本次试用评测资格!
2022年11月,ChatGPT的问世展示了大模型的强大潜能,对人工智能领域有重大意义,并对自然语言处理研究产生了深远影响,引发了大模型研究的热潮。
距ChatGPT问世不到一年,截至2023年10月,国产大模型玩家就有近200家,国内AI大模型如雨后春笋般涌现,一时间形成了百家争鸣、百花齐放的发展态势。
“大模型”当之无愧地承包了2023年科技圈全年的亮点!
那么,对IT圈的科技从业者来说,应该做什么?
拥抱技术变革,理解产业市场,找到适合自己的位置。
大模型市场可以分为通用大模型和垂直大模型两大类。
大模型的代表ChatGPT是通用大模型,也是许多国内厂家对标的大模型,以技术攻克为目的。国内的文心一言就属于这一类。
垂直大模型,聚焦解决垂直领域问题,是在通用大模型的基础上训练行业专用模型,应用到金融、医疗、教育、养老、交通等垂直行业,使大模型领域化、商业化,做到实际应用落地。
为了使更多的自然语言处理研究人员和对大语言模型感兴趣的读者能够快速了解大模型的理论基础,并开展大模型实践,复旦大学张奇教授团队结合他们在自然语言处理领域的研究经验,以及分布式系统和并行计算的教学经验,在大模型实践和理论研究的过程中,历时8个月完成 《大规模语言模型:从理论到实践》 一书的撰写。希望这本书能够帮助读者快速入门大模型的研究和应用,并解决相关技术问题。

本书一经上市,便摘得京东新书日榜销售TOP1的桂冠,可想大家对本书的认可和支持!
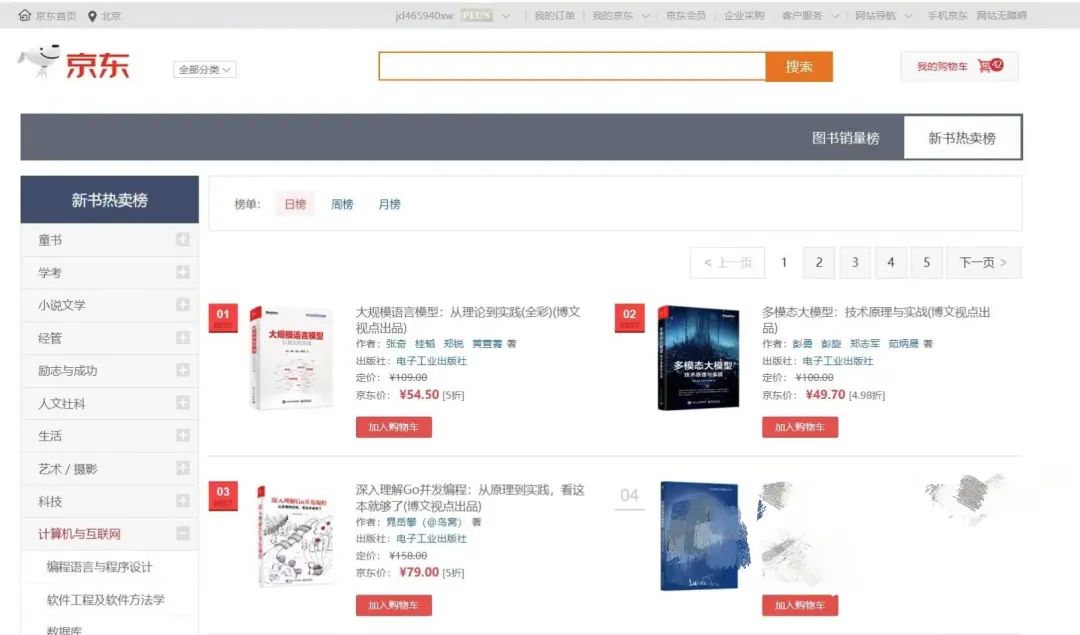
这本书为什么如此受欢迎?它究竟讲了什么?下面就给大家详细~~
本书主要内容
本书围绕大语言模型构建的四个主要阶段——预训练、有监督微调、奖励建模和强化学习展开,详细介绍各阶段使用的算法、数据、难点及实践经验。
预训练阶段需要利用包含数千亿甚至数万亿单词的训练数据,并借助由数千块高性能GPU 和高速网络组成的超级计算机,花费数十天完成深度神经网络参数的训练。这一阶段的难点在于如何构建训练数据,以及如何高效地进行分布式训练。
有监督微调阶段利用少量高质量的数据集,其中包含用户输入的提示词和对应的理想输出结果。提示词可以是问题、闲聊对话、任务指令等多种形式和任务。这个阶段是从语言模型向对话模型转变的关键,其核心难点在于如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系及训练数据的规模。
奖励建模阶段的目标是构建一个文本质量对比模型,用于对有监督微调模型对于同一个提示词给出的多个不同输出结果进行质量排序。这一阶段的难点在于如何限定奖励模型的应用范围及如何构建训练数据。
强化学习阶段 ,根据数十万提示词,利用前一阶段训练的奖励模型,对有监督微调模型对用户提示词补全结果的质量进行评估,与语言模型建模目标综合得到更好的效果。这一阶段的难点在于解决强化学习方法稳定性不高、超参数众多及模型收敛困难等问题。
除了大语言模型的构建,本书还介绍了大语言模型的应用和评估方法,主要内容包括如何将大语言模型与外部工具和知识源进行连接、如何利用大语言模型进行自动规划,完成复杂任务,以及针对大语言模型的各类评估方法。

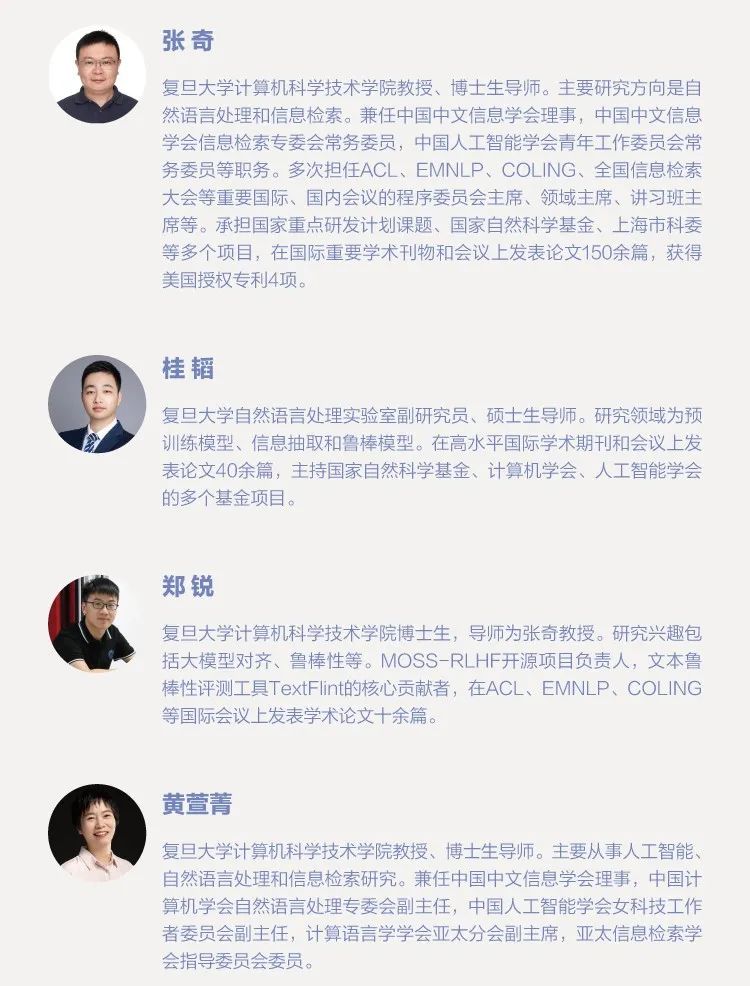
作者介绍:
申请时间
2024年3月11日——2024年4月11日
活动参与方式
1、在本帖下方留言回帖说说你想要这本书的理由15字以上。
2、我们将从本帖留言中每5层楼挑选1位幸运者赠送书籍,共赠送4本。若有效回帖楼层数超过25则按照每5层抽选1位获奖者以此类推。
3、请在收到书籍后2个星期内提交不少于2篇试读报告要求300字以上图文并茂。
4、试读报告发表在电子发烧友论坛>>社区活动专版标题名称必须包含 【大规模语言模型:从理论到实践】+自拟标题
注意事项
1、活动期间如有作弊、灌水等违反电子发烧友论坛规则的行为一经发现将立即取消获奖资格
2、活动结束后获奖名单将在论坛公示请活动参与者尽量完善个人信息如管理员无法联系到选中的评测者则视为自动放弃。
3、申请人收货后14天内未完成书评无权将书籍出售或转赠给他人。如无法在收货后14天内提交书评请将书籍退回电子发烧友论坛运费自理。
4、如有问题请咨询工作人员(微信:elecfans123)。
5、电子发烧友对本活动具有最终解释权。
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号










 淘帖
淘帖 1474
1474






