昨天提到要使模型运行的NPU上,必须先将其量化。如果对没有量化的模型使用vela工具进行转换,工具会给出警告,所生成的模型仍然是只能运行在CPU上,而无法运行在NPU上的。
下面就是用vela工具对simple_audio_model_numpy.tflite文件进行转换的结果。
root@atk-imx93:~/shell/simple# vela simple_audio_model_numpy.tflite
Warning: Unsupported TensorFlow Lite semantics for RESIZE_BILINEAR 'sequential_2/resizing_2/resize/ResizeBilinear;StatefulPartitionedCall/sequential_2/resizing_2/resize/ResizeBilinear'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: input_3, sequential_2/resizing_2/resize/ResizeBilinear;StatefulPartitionedCall/sequential_2/resizing_2/resize/ResizeBilinear
Warning: Unsupported TensorFlow Lite semantics for CONV_2D 'sequential_2/conv2d_4/Relu;StatefulPartitionedCall/sequential_2/conv2d_4/Relu;sequential_2/conv2d_4/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd;sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd/ReadVariableOp2'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: sequential_2/resizing_2/resize/ResizeBilinear;StatefulPartitionedCall/sequential_2/resizing_2/resize/ResizeBilinear, sequential_2/conv2d_4/Relu;StatefulPartitionedCall/sequential_2/conv2d_4/Relu;sequential_2/conv2d_4/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd;sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd/ReadVariableOp1_reshape, sequential_2/conv2d_4/Relu;StatefulPartitionedCall/sequential_2/conv2d_4/Relu;sequential_2/conv2d_4/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd;sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd/ReadVariableOp2
Warning: Unsupported TensorFlow Lite semantics for CONV_2D 'sequential_2/conv2d_5/Relu;StatefulPartitionedCall/sequential_2/conv2d_5/Relu;sequential_2/conv2d_5/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_5/BiasAdd;sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/BiasAdd/ReadVariableOp'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: sequential_2/conv2d_4/Relu;StatefulPartitionedCall/sequential_2/conv2d_4/Relu;sequential_2/conv2d_4/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd;sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_4/BiasAdd/ReadVariableOp2, sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/Conv2D_reshape, sequential_2/conv2d_5/Relu;StatefulPartitionedCall/sequential_2/conv2d_5/Relu;sequential_2/conv2d_5/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_5/BiasAdd;sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/BiasAdd/ReadVariableOp
Warning: Unsupported TensorFlow Lite semantics for MAX_POOL_2D 'sequential_2/max_pooling2d_2/MaxPool;StatefulPartitionedCall/sequential_2/max_pooling2d_2/MaxPool'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: sequential_2/conv2d_5/Relu;StatefulPartitionedCall/sequential_2/conv2d_5/Relu;sequential_2/conv2d_5/BiasAdd;StatefulPartitionedCall/sequential_2/conv2d_5/BiasAdd;sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/Conv2D;StatefulPartitionedCall/sequential_2/conv2d_5/BiasAdd/ReadVariableOp, sequential_2/max_pooling2d_2/MaxPool;StatefulPartitionedCall/sequential_2/max_pooling2d_2/MaxPool
Warning: Unsupported TensorFlow Lite semantics for RESHAPE 'sequential_2/flatten_2/Reshape;StatefulPartitionedCall/sequential_2/flatten_2/Reshape'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: sequential_2/max_pooling2d_2/MaxPool;StatefulPartitionedCall/sequential_2/max_pooling2d_2/MaxPool, sequential_2/flatten_2/Reshape;StatefulPartitionedCall/sequential_2/flatten_2/Reshape
Warning: Unsupported TensorFlow Lite semantics for FULLY_CONNECTED 'sequential_2/dense_4/Relu;StatefulPartitionedCall/sequential_2/dense_4/Relu;sequential_2/dense_4/BiasAdd;StatefulPartitionedCall/sequential_2/dense_4/BiasAdd'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: sequential_2/flatten_2/Reshape;StatefulPartitionedCall/sequential_2/flatten_2/Reshape, sequential_2/dense_4/MatMul;StatefulPartitionedCall/sequential_2/dense_4/MatMul_reshape, sequential_2/dense_4/Relu;StatefulPartitionedCall/sequential_2/dense_4/Relu;sequential_2/dense_4/BiasAdd;StatefulPartitionedCall/sequential_2/dense_4/BiasAdd
Warning: Unsupported TensorFlow Lite semantics for FULLY_CONNECTED 'Identity'. Placing on CPU instead
- Input(s), Output and Weight tensors must have quantization parameters
Op has tensors with missing quantization parameters: sequential_2/dense_4/Relu;StatefulPartitionedCall/sequential_2/dense_4/Relu;sequential_2/dense_4/BiasAdd;StatefulPartitionedCall/sequential_2/dense_4/BiasAdd, sequential_2/dense_5/MatMul;StatefulPartitionedCall/sequential_2/dense_5/MatMul_reshape, Identity
Network summary for simple_audio_model_numpy
Accelerator configuration Ethos_U65_256
System configuration internal-default
Memory mode internal-default
Accelerator clock 1000 MHz
CPU operators = 7 (100.0%)
NPU operators = 0 (0.0%)
Neural network macs 0 MACs/batch
Network Tops/s nan Tops/s
NPU cycles 0 cycles/batch
SRAM Access cycles 0 cycles/batch
DRAM Access cycles 0 cycles/batch
On-chip Flash Access cycles 0 cycles/batch
Off-chip Flash Access cycles 0 cycles/batch
Total cycles 0 cycles/batch
Batch Inference time 0.00 ms, nan inferences/s (batch size 1)
Warning: Could not write the following attributes to RESHAPE 'sequential_2/flatten_2/Reshape;StatefulPartitionedCall/sequential_2/flatten_2/Reshape' ReshapeOptions field: new_shape
这个错误信息明确指出Vela不支持 TensorFlow Lite 对特定操作的支持问题。具体来说,这个警告说明了:量化参数缺失 ,错误信息指出,涉及的输入、输出和权重张量必须具有量化参数,但在这个操作中,某些张量(如 input_3 和 sequential_2/resizing_2/resize/ResizeBilinear)缺失了这些量化参数。由于不支持,相关的操作将被放置在 CPU 上执行,而不是利用可能存在的更高效的硬件加速(NPU)。
我们使用netron.app可以查看一下模型文件。
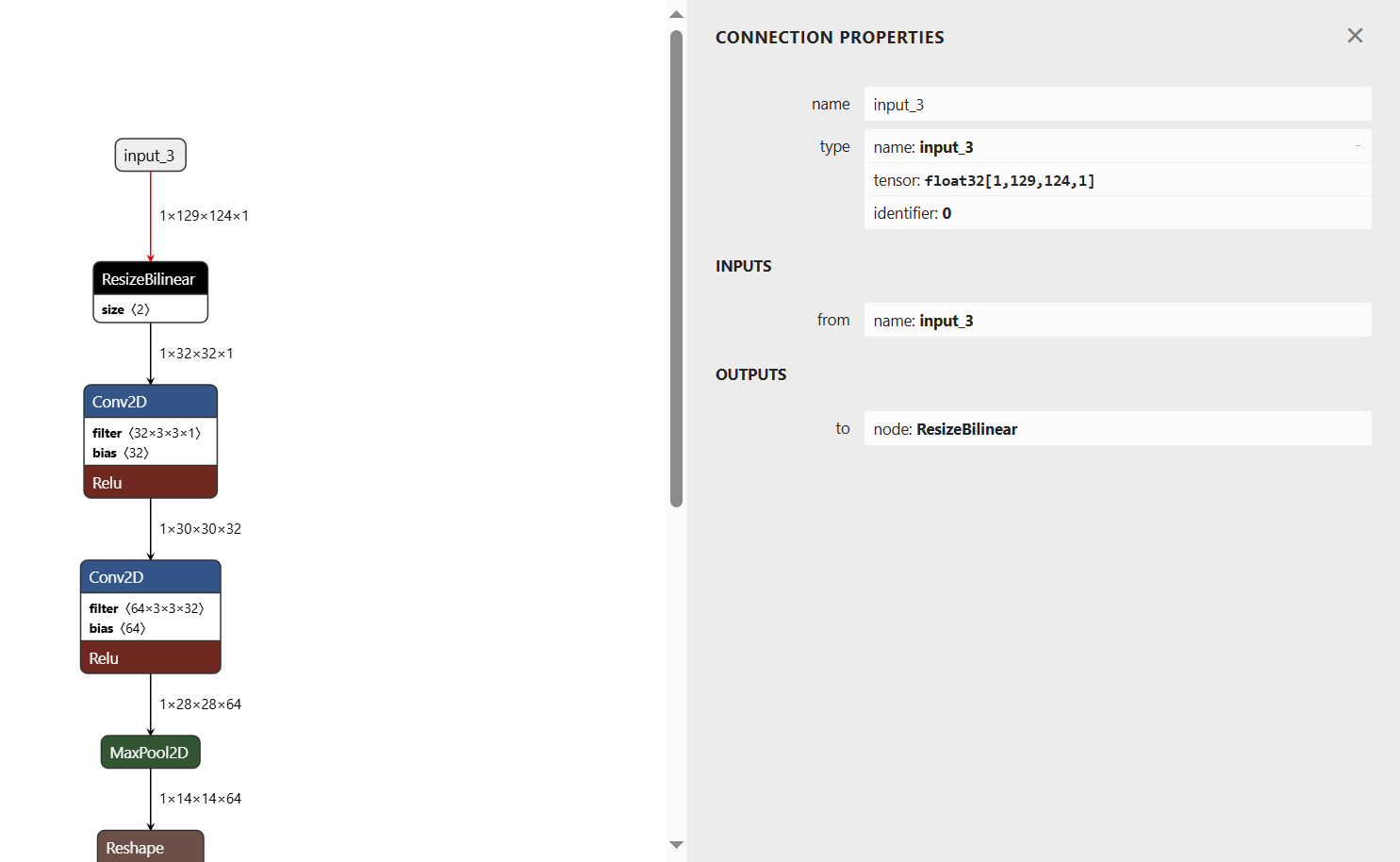
从中可以看到input_3是float32类型的。
而查看被vela支持的模型,可以看到其输入参数已经被量化,是int8类型的。
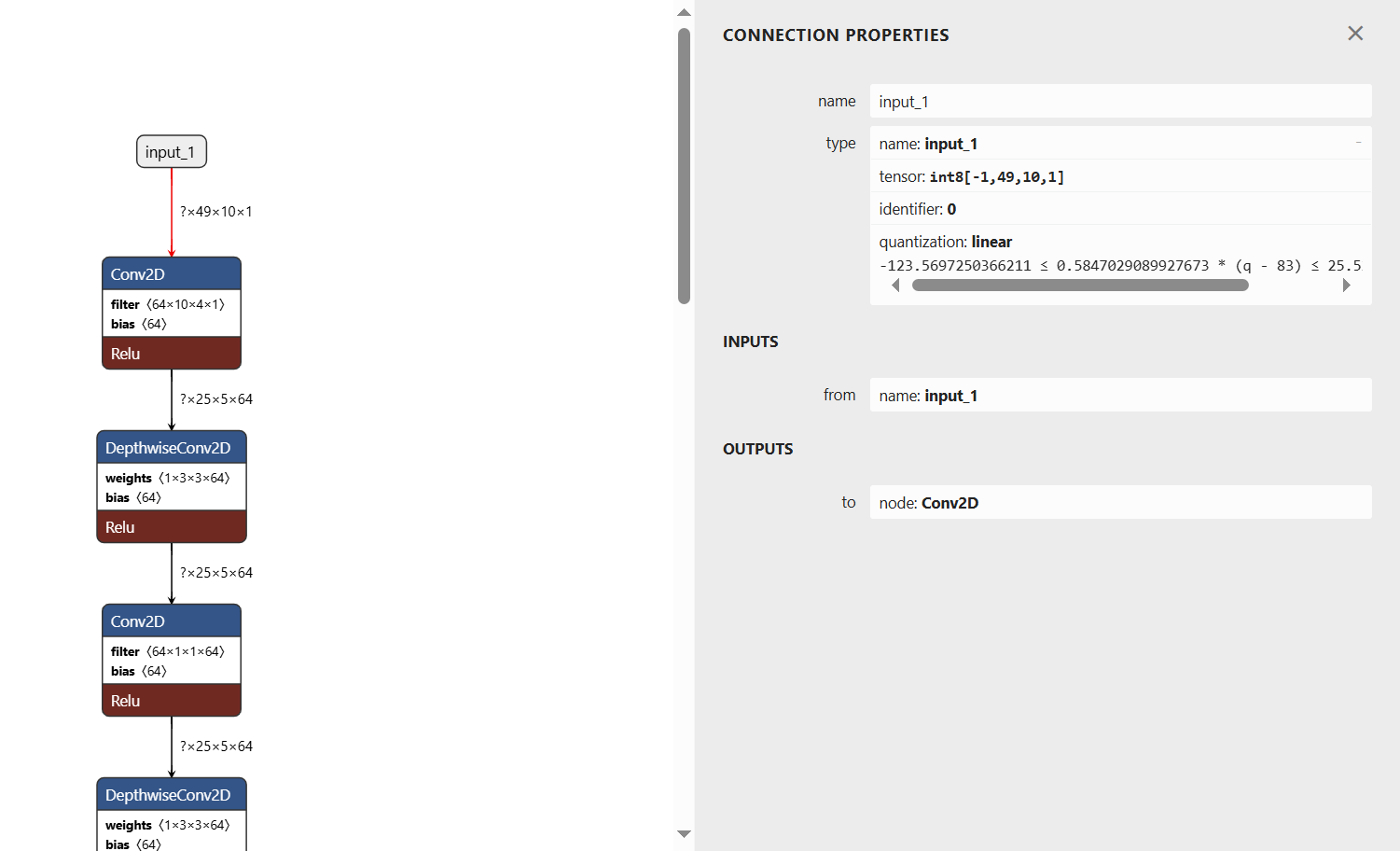
如果我们想利用i.MX 93的NPU能力就需要先对模型文件进行量化。当然如果觉得i.MX 93的CPU推理能力已经够用了,此步骤也可以省略。
|  电子发烧友论坛
电子发烧友论坛
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 28234
28234


 淘帖
淘帖 显身卡
显身卡











