感谢电子发烧友和爱芯元智公司提供的测试机会。
自从开箱爱芯派 Pro (AXera-Pi Pro)开发板之后一直没有更新,电子发烧友的小姐姐已经来催更了。一个是年底的事情确实多,单位的各部门都在冲刺,所以派下来活根本就做不完,另一个是在配置爱芯派 Pro上也遇到了一些小麻烦。在2023年的最后一周争取多更新一些。
网络配置
开发板上自带的应用很有限,所以第一件事就是上网更新应用程序。虽然板子上带有网口,但是单位的网络环境是必须先用浏览器登录进行身份确认才能访问外网。可是板子上的浏览器不能工作,总是提示:“Failed to execute default web browser”。把板子拿回家测试,又发现家里老旧的显示器无法视频板子的显示分辨率。虽然可以通过SSH登录并更新软件,不过我们要使用的功能都是关于视觉的,没有显示还是很麻烦的。爱芯派Pro采用的是AARCH64架构,没有现成的VNC服务器可以用(后面如果有时间可以测试移植VNC服务器),最后只好买了个显示器来完成任务。
联网成功之后,先使用apt更新一下所有软件。
apt-get update -y
AARCH64架构可用的浏览器也比x64少,可以考虑安装Chrome的开源版本chromium。
apt install chromium
不过因为时间的问题,还没有测试浏览器是否可以工作。
示例程序的运行
我们今天要测试的程序是官方提供的交互式图像分割和修复(Segment and Inpaint Anything)。所谓交互式图像分割和修复,就是软件提供了一个基于QT6的GUI交互界面,实现了交互式点选、框选的实时分割和进一步可选修复。原始代码由爱芯官方开源于 GITHUB:https://github.com/AXERA-TECH/SAM-ONNX-AX650-CPP。仓库内的文本介绍了如何在AX650N上自行编译,这个部分的内容我们后续再说。官方提供了一个现成的预编译版本,可以直接下载samqt_ax650.zip文件,将其解压于开发板中。
要运行这个例子,需要先安装QT6的环境,使用如下命令:
apt install qt6-base-dev
在终端中进入SAM目录,首先修改run.sh和SAMQT_NEW的权限为可执行:
chmod 777 run.sh
chmod 777 SAMQT_NEW
打开run.sh文件,可以看到如下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PWD
./SAMQT_NEW --encoder ax_models/sam-encoder.axmodel --decoder ax_models/sam_vit_b_01ec64_decoder.onnx --inpaint ax_models/big-lama-regular.axmodel
从中可以看到,这个程序加载了encoder、decoder和inpaint三个模型,其中的.axmodel是官方为我们转化好的运行在AX650板子上的专有模型。
然后执行run.sh就可以运行程序了。
除了使用官方的测试图片,我们还使用了一张北京理工大学良乡校区校门的照片做测试。

我们可以用以下4张图片来展示选取对象进行分割并删除对象,然后进行填充的效果。我们可以框选图片中一辆车,然后删除它,然后用背景进行填充。
![SAM示例00-03-16[20231226-100941805].jpg](//file1.elecfans.com/web2/M00/B9/00/wKgZomWKRe6AKRPuAAaOARDY8dQ044.jpg)
![SAM示例00-03-30[20231226-100817527].jpg](//file1.elecfans.com/web2/M00/B9/00/wKgZomWKRg2AUhJ7AAah9_RhOtU062.jpg)
![SAM示例00-03-32[20231226-101006328].jpg](//file1.elecfans.com/web2/M00/B9/00/wKgZomWKRiSAJP9VAAaULFd6zwg594.jpg)
![SAM示例00-03-37[20231226-100841504].jpg](//file1.elecfans.com/web2/M00/B9/00/wKgZomWKRiyATQ4tAAY4vyS4Ms4367.jpg)
完整的测试视频发到B站上了,可以访问https://www.bilibili.com/video/BV1kN4y1z7vL/观看。
图像分割框架SAM
这个例子使用了Meta AI发布的图像识别和分割框架SAM(Segment Anything,分割一切对象模型)。自SA项目自2023年发布以来,因其令人印象深刻的零样本传输性能和与其他模型兼容的高度通用性而备受关注,用于高级视觉应用。SAM框架的原始论文参见:https://arxiv.org/abs/2304.02643。SAM有一个专门的网站:https://segment-anything.com/,从中可以看到各种资料,以及数据集相关的信息。
SAM框架一经发布,便引起大家的极大兴趣,有许多关于它的改进方案。其中MobileSAM(https://github.com/ChaoningZhang/MobileSAM)是一个轻量化的框架,它的目标是通过用轻量化图像编码器取代复杂的图像编码器,使SAM对移动端友好。MobileSAM的推理速度特别快,所以我们才能在前面的Demo中看到实时操作的效果。
爱芯派的例子还参考了https://github.com/OroChippw/SegmentAnything-OnnxRunner,这是一个用C++实现SAM的例子,这个例子的可读性非常不错。
下面简单介绍一下SAM的工作原理,帮助大家理解这个程序并进行后续的改进。
SAM 是一种深度学习模型(基于 transformer)。与任何深度学习一样,它已经在大量图像和掩码上进行了训练——准确地说,在1100万张图像中,有超过10亿个掩码。这是一个相当大的数字。即便如此,SAM 如何知道要在图像中分割出哪些对象?我们需要提示SAM精确细分哪个区域。目前版本的SAM 支持三种不同的提示:通过单击一个点、通过绘制边界框、通过在对象上绘制粗略的蒙版。Meta在开发一个版本,将文本输入作为提示,类似ChatGPT那样。
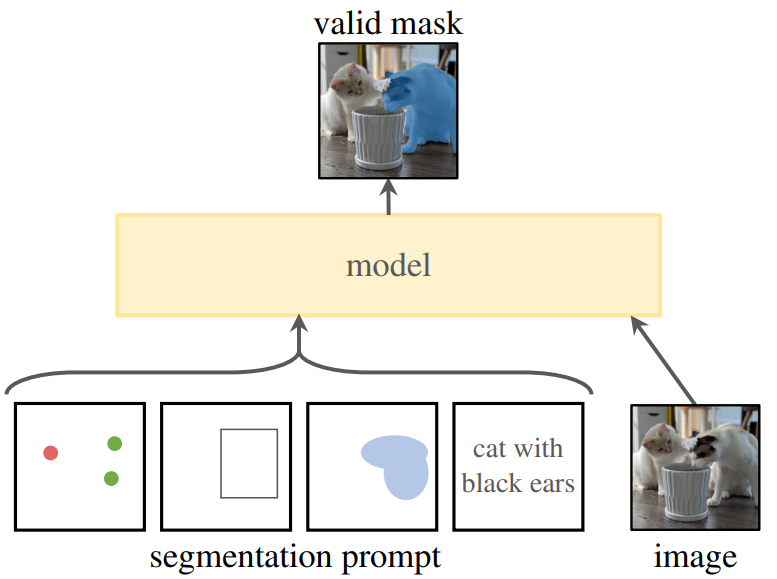
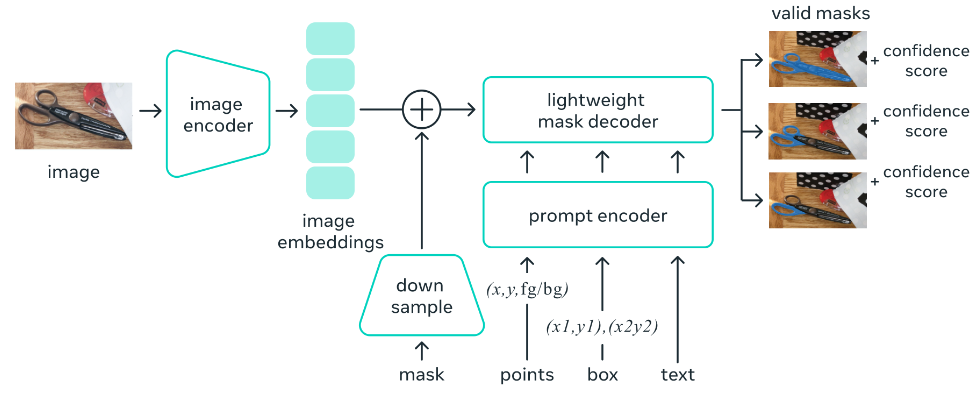
在 SAM 中,有三个重要组件:图像编码器(encoder)、提示编码器、掩码解码器(decoder)。当我们将图像作为SAM的输入时,它首先通过图像编码器并为整个图像生成一次性嵌入(embedding)。还有一个提示编码器,用于点、框或文本作为提示。如果我们提供掩码作为输入,它将直接经历下采样阶段。下采样使用 2D 卷积层进行。然后,模型将其与图像嵌入连接起来,以获得最终的向量。模型从提示向量
- 图像嵌入中获取的任何向量都会通过轻量级解码器,该解码器会创建最终的分割掩码。我们得到可能的有效掩码以及置信度分数作为输出。整个处理过程如下图所示。
图像填充框架
图像填充部分,这个例子使用了LaMa框架(https://advimman.github.io/lama-project/)。LaMa(Resolution-Robust Large Mask Inpainting with Fourier Convolutions)是一种用于图像修复的深度学习模型。它专门设计用于处理大尺寸遮挡区域的图像修复任务。LaMa模型提供了一个解决这类问题的方法。它基于傅里叶卷积(Fourier
Convolutions)的思想,通过频域的变换和操作来处理大尺寸的遮挡区域。传统的卷积操作在处理大遮挡时往往会产生较大的估计误差,而LaMa模型通过将输入图像转换到频域空间,利用傅里叶系数提取和处理图像的高频信息,可以更好地恢复图像细节。
从其设计目标可以看出,它主要是针对大尺寸遮挡区域,从前面的测试看出,汽车后面的填充效果比较好,而行人由于面积太小,填充的细节肯定是不太好的。
今天先介绍到这里,后面将针对程序进行些修改。
 电子发烧友论坛
电子发烧友论坛 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 1945
1945
![SAM示例00-03-16[20231226-100941805].jpg](http://file1.elecfans.com/web2/M00/B9/00/wKgZomWKRe6AKRPuAAaOARDY8dQ044.jpg)
![SAM示例00-03-30[20231226-100817527].jpg](http://file1.elecfans.com/web2/M00/B9/00/wKgZomWKRg2AUhJ7AAah9_RhOtU062.jpg)
![SAM示例00-03-32[20231226-101006328].jpg](http://file1.elecfans.com/web2/M00/B9/00/wKgZomWKRiSAJP9VAAaULFd6zwg594.jpg)
![SAM示例00-03-37[20231226-100841504].jpg](http://file1.elecfans.com/web2/M00/B9/00/wKgZomWKRiyATQ4tAAY4vyS4Ms4367.jpg)


 淘帖
淘帖




