引 言
根升余弦成形滤波器是数字信号处理中的重要部件,它能对数字信号进行成形滤波,压缩旁瓣,减少干扰的影响,从而降低误码率。根据文献[1],它的传统FP-GA实现方式基于乘累加器(Multiplier Add Cell,MAC)结构,设计方便,只需要乘法器、加法器和移位寄存器即可实现,但是在FPGA中实现硬件乘法器十分耗费资源。特别是当滤波器阶数很高时,资源耗费不可忽视。若采用乘法器复用的结构,运算速度较慢。分布式算法(Distribute Arithmetic,DA)是另一种应用在FPGA中计算乘积和的算法。根据文献[2],分布式算法结构的FIR滤波器利用FPGA中的查找表(LUT)来替代乘法器,这种方法可以极大地减少硬件电路规模,有效提高逻辑资源的利用率,而且有较高的处理速度,满足实时处理的要求。分布式算法的处理速度仅与输入的位宽有关,对于大规模乘积和的运算,其计算速度有着明显的优势。当输入位宽过大时,可以通过将DA算法改进成并行结构而获得更快的处理速度。根据文献[3],对多速率系统来说,还可以引入多相结构来减少计算量,提高处理速度。本文针对根升余弦成形滤波器提出一种基于多速率信号处理技术和分布式算法的FPGA实现技术,使得计算量大幅减少,处理速度得到较大提高,而且使得FPGA资源利用更合理。
1、根升余弦滤波器原理与结构
奈奎斯特第一准则提出消除码间干扰,系统从发送滤波器经信道到接收滤波器总的传输特性所应满足的条件,据此可以求出满足奈奎斯特准则的成形滤波器。根据文献[4],在实际中得到广泛应用的是幅频响应,它是具有奇对称升余弦形状过渡带的一类滤波器,即升余弦滤波器,它的冲激响应为:
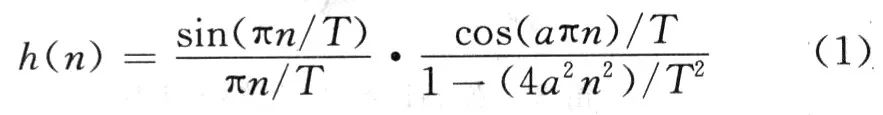
式中:丁为输入码元速率;a为滚降系数,实际应用在0~0.4之间。除了抽样点n=0之外,它在其余所有抽样点上均为0,而且它的衰减很快,随着n的增大,呈平方衰减。这样,对于减小码间干扰及对定时误差的影响非常有利。
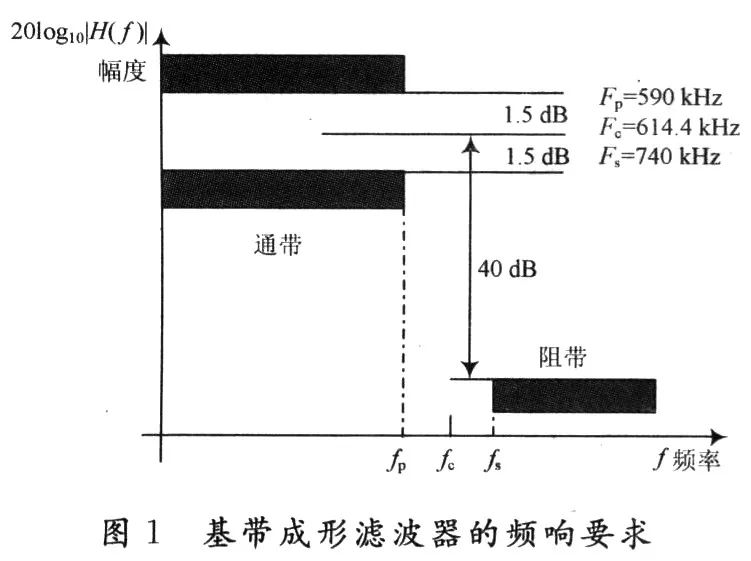
本文要求实现的基带成形滤波器滚降系数为0.35。它的频率响应要求如图1所示。
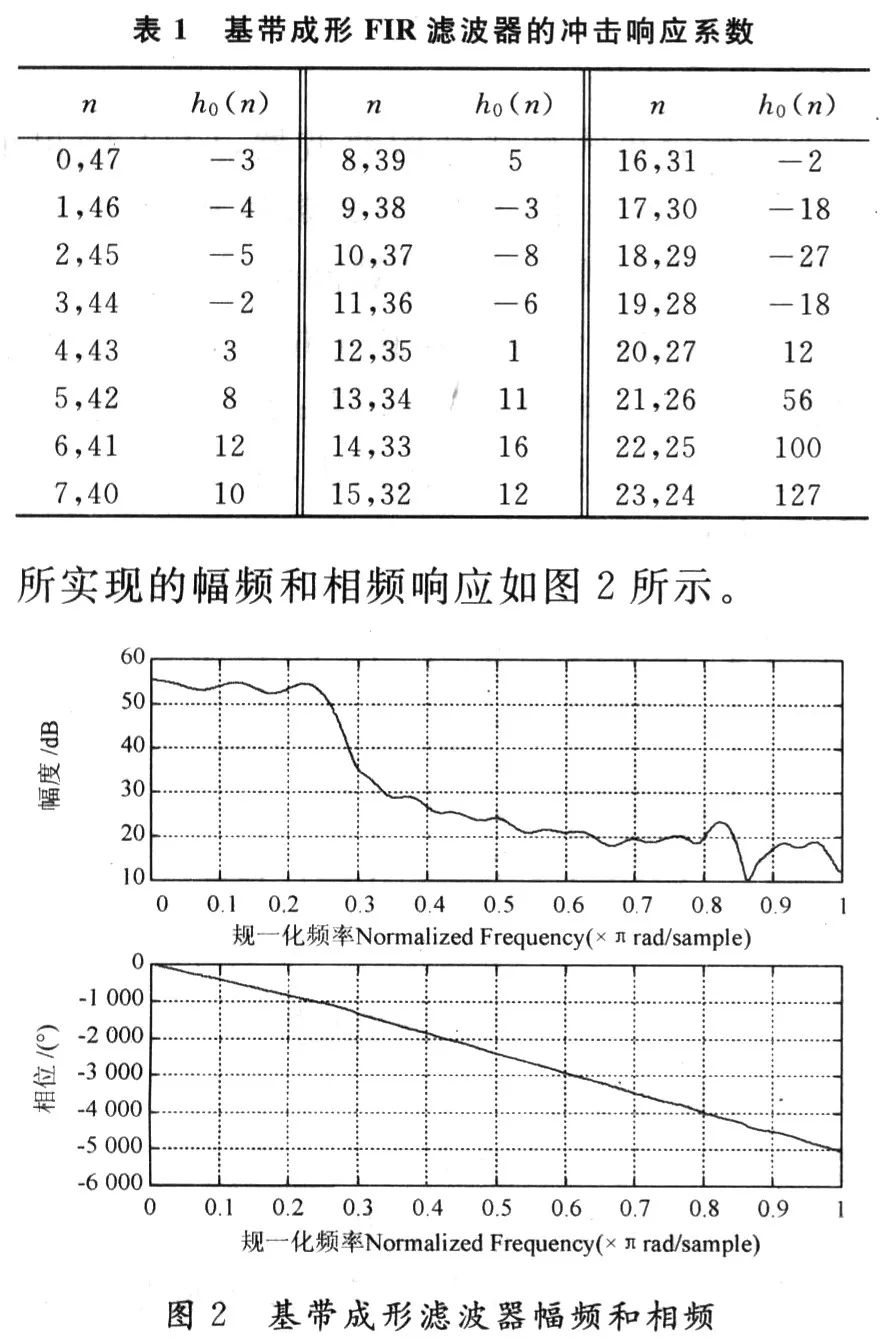
由于在FPGA中数据由定点数表示,所以需要对系数进行量化。本设计中,采用整系数表示方法,对滤波器系数先放大127倍,然后取整量化为8位整数,量化后它的冲激响应系数如表1所示。
2、分布式算法与多相原理
2.1 分布式算法原理
分布式最初由Croisier于1973年提出,但直到出现查找表结构的FPGA之后,分布式算法才被广泛应用于乘积计算中。FIR滤波器采用分布式算法可以极大地减少硬件电路的规模,很容易实现流水线技术,提高电路的执行速度。
根据文献[5],长度为N的因果有限冲激响应滤波器(FIR)可以用下列传输函数H(z)来描述。
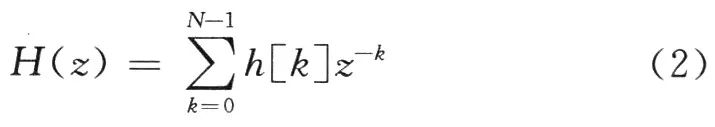
在时域中,上述FIR滤波器的输入输出关系为:
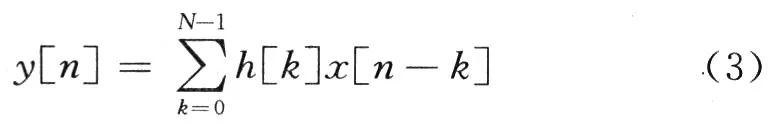
式中:y[n]和x[n]分别是输出和输入的序列;h[k]为冲激响应在时间序号k时的系数。若y(n)表示滤波器的输出,Ak表示滤波器的系数,xk(n)表示第忌个输入变量,则N阶线性、时不变FIR滤波器的输出为:

在FPGA的实现中,根据文献[6]数据采用二进制补码表示,所以变量xk可以表示为:
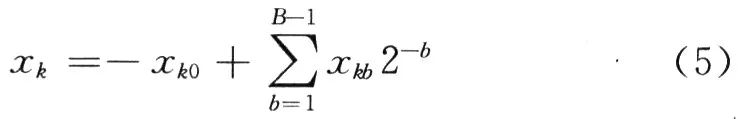
式中:xkb为xk的第b比特位;B为输入变量xk的数据位数。将式(5)代入式(4)可得:
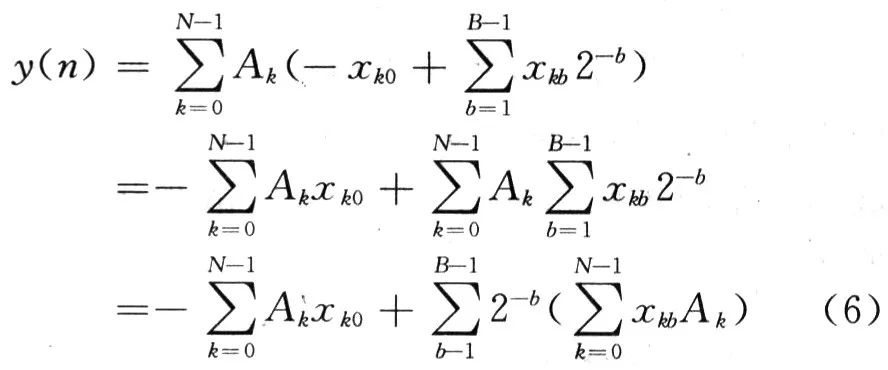
这里,利用一个查找表来实现,即把所有可能的2N个中间数据存储在一个查找表中,以一个N位输入向量xb作为地址,输出为对应该向量的一个特定值。对于并行分布式算法结构滤波器,从低位到高位,依次乘以2N,N=0,1,2,…,然后相加得到输出值。
2.2 多速率FIR的多相表示
设FIR滤波器转移函数为:
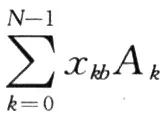
式中:N为滤波器长度。假设满足条件N=DQ(其中D,Q为整数),则H(z1)可以写成:
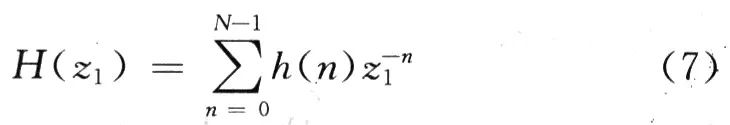
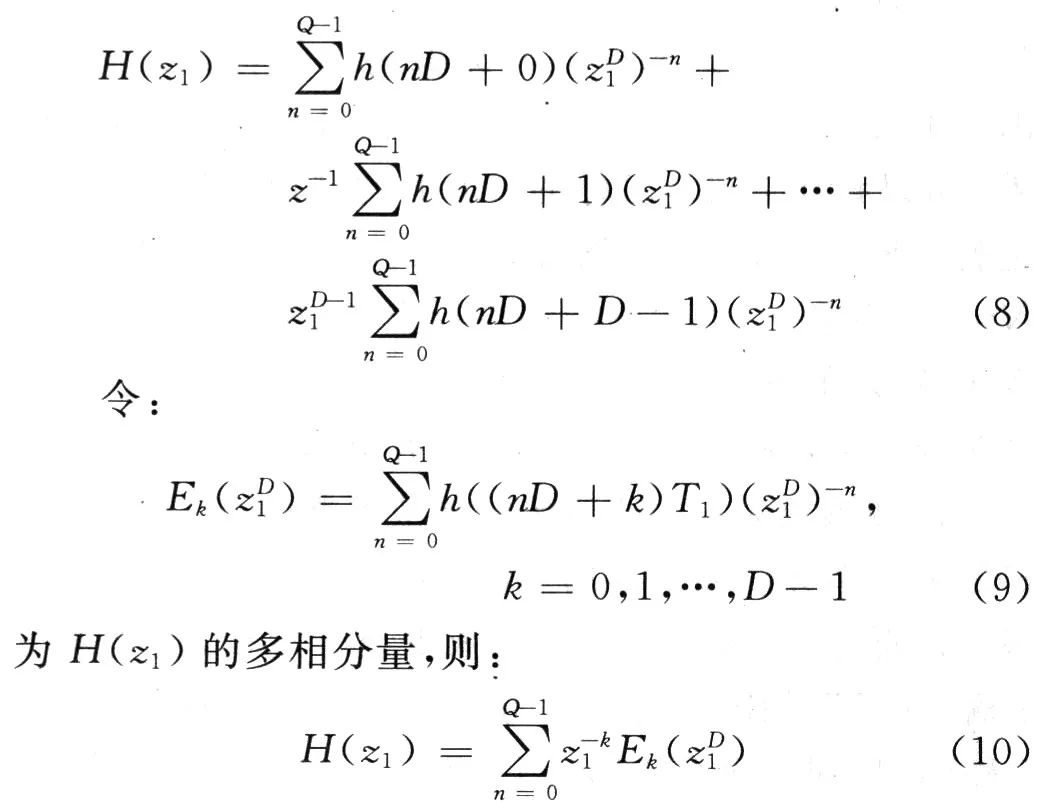
根据文献[7],传统的滤波后再抽取的多速率系统如图3所示。
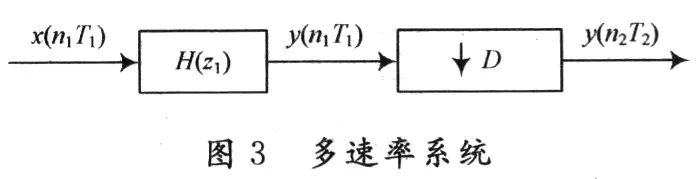
图3中,T2=DT1。可以看出,卷积运算在下采样之前进行。通过对滤波器进行多相分解,得到多相分解表示如图4所示。
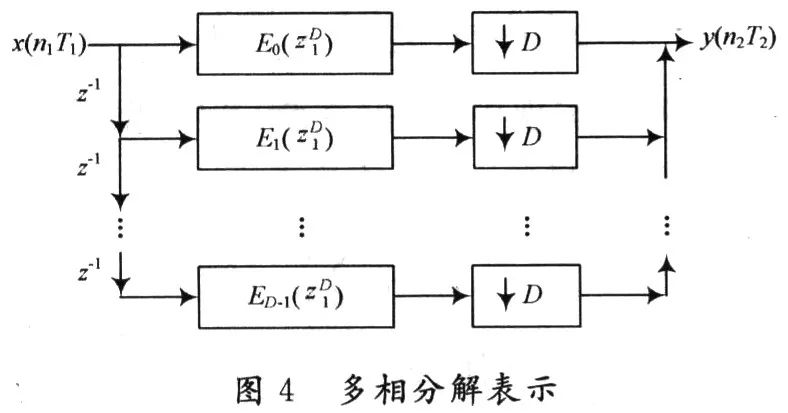
Ek(z1D)相当于一组滤波器,利用多采样率系统中结构的互易性对滤波器位置进行等效变换,将抽取操作前置,这样卷积运算已经变换到在低抽样率下进行,滤波运算量减少到原来的1/D,大大减少运算量,如图5所示。
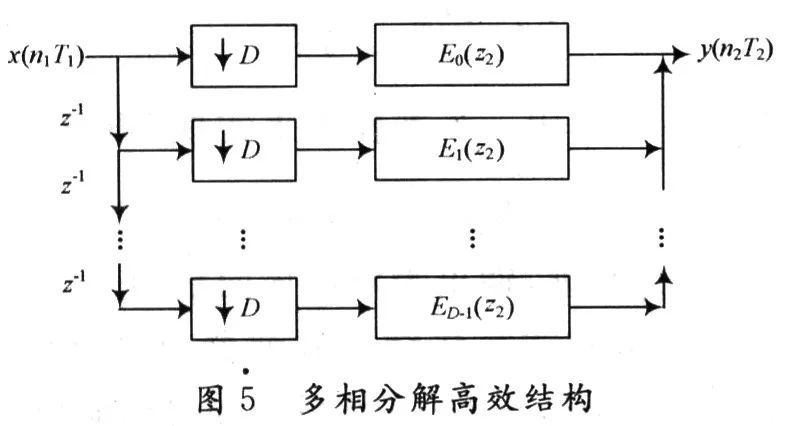
由图5可知,每相仍然相当于低阶的FIR滤波器,下节对其采用DA算法,可以看到运算速度将进一步提高,运算量也将大幅减少。
3、多速率DA根升余弦滤波器的结构及其FPGA实现
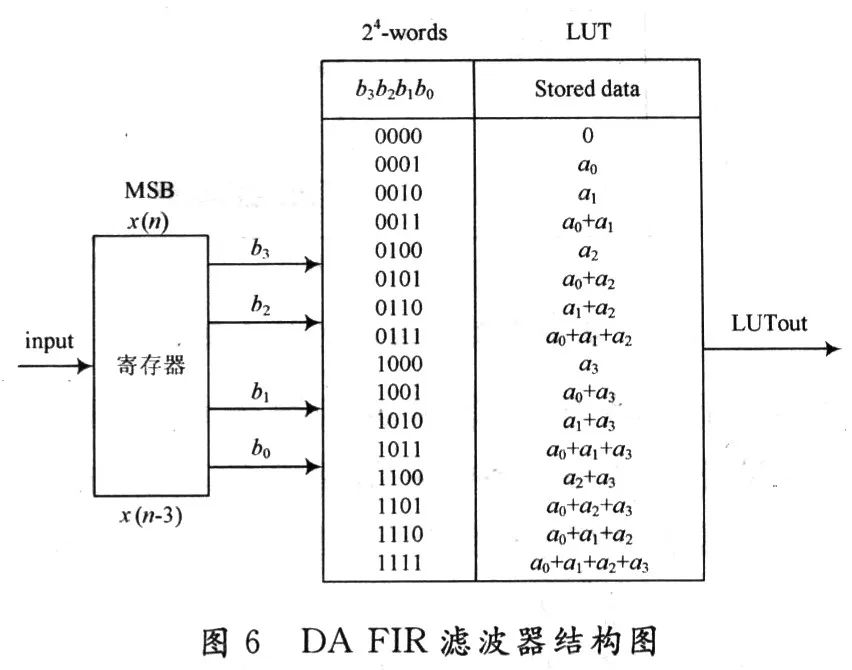
按查找表的方式,DA算法可以分为串行实现方式和位并行实现方式两种。本文采用位并行方式实现。因为本文针对的是一个48阶平方根升余弦滤波器,从表1可以看到结构是对称的,LUT的规模随地址空间,也就是输入系数N的增加而呈指数增加。这里系数N=48,用单个LUT不能够执行全字(输入LUT位宽等于系数的数量)。为了减小LUT的规模,根据文献[8]可以利用部分表计算,并将结果相加,即用m个滤波系数为k的滤波单元构成系数为N(N=m×k)的滤波单元。如果再加上流水线寄存器,这一改进并没有降低速度,却可以极大地减少设计规模,这里采用4输入LUT,如图6所示。考虑滤波器的对称性,需要6种LUT,对于每个4输入LUT:
b0~b3为x[n]~x[n-3]的第0位,构成了一组查找表的查找地址。
LUT表中存储的是所有可能使用到的数值,是滤波器系数的16种组合形式。
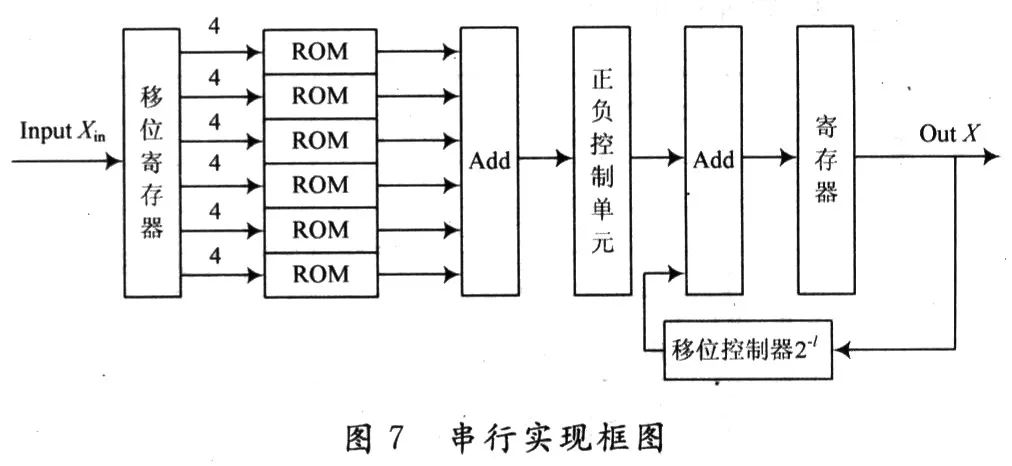
3.1 串行实现结构
对于串行分布式算法结构滤波器,LUT输出值与寄存器值左移1位(乘以21)后的数值相加,并将相加后的结果存入寄存器。首先计算高位(b=0),再计算低位,所以寄存器的值要先左移1位再相加,从而减少资源消耗。当b=0时,做减法运算;当b>0时,做加法运算。经过1次减法和B-1次加法,在B次查询循环后完成计算,实现框图如图7所示。
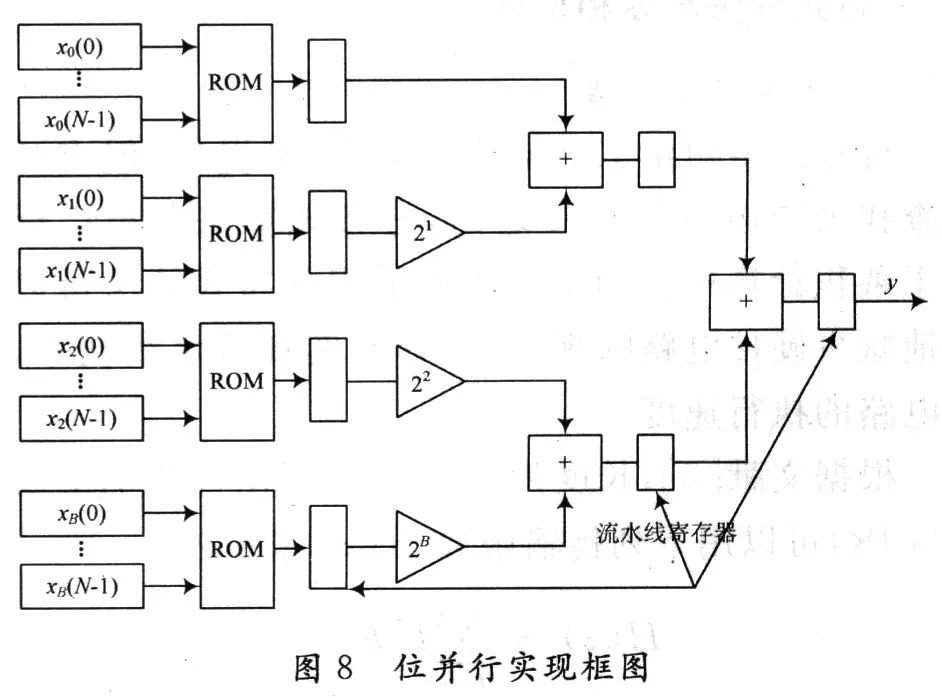
3.2 位并行实现结构
另一个DA结构的改进即并行算法是以增加额外的LUT、寄存器和加法器为代价提高速度的。并行算法是速度最优的高阶分布式算法,实现框图如图8所示。
3.3 滤波器实现框图
本设计的48阶根升余弦滤波器的设计框图如图9所示。
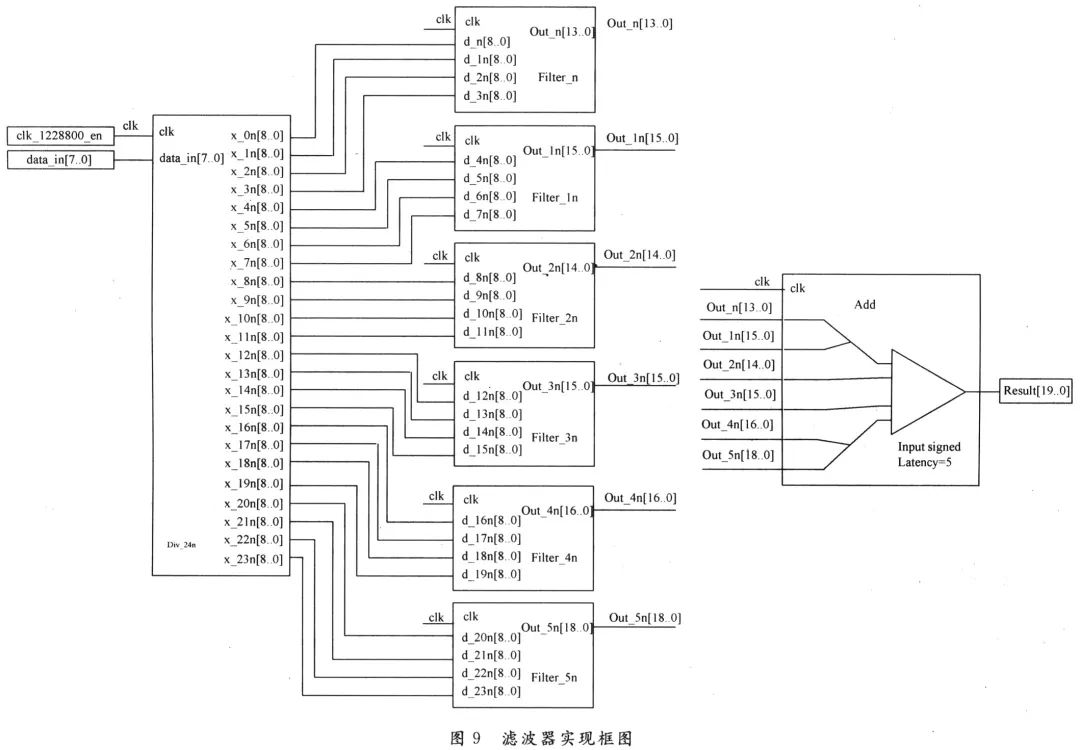
根据文献[10],利用VHDL语言,输入数据位宽限定为8 b,FIR滤波器的系数是常数,存在ROM中,工作频率为78.643 2 MHz。
4、结果分析
本文实现选用的FPGA是Altera的StratixⅡEP2S60F1040C4,在QuartusⅡ7.2平台上进行仿真。输入数据位宽限定为8 b,整个处理过程没有截位,因此该滤波器的频率响应与其他形式实现的滤波器频率响应是一样的。区别集中在以下三点:
(1)节省资源开销
通过仿真综合后,得到根升余弦滤波器的三种实现方式的资源消耗情况。根据文献[9],把1个DSPblock 9 b折合成82个ALUTs和82个寄存器计算,得到表2。
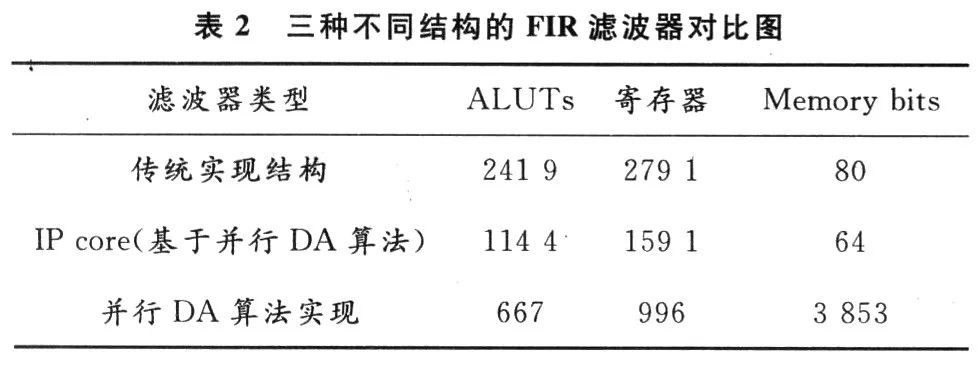
可见,传统的实现结构占用资源量大,而基于并行DA算法的实现结构所占用的ALUTs只是前者的27.6%,寄存器只是它的35.7%,只是Memory bits大幅增加,不过相对来说,FPGA中Memory资源很丰富,可以不考虑。
本文所采用的并行DA算法实现结构与QuartusⅡ自带的基于DA算法的FIR滤波器IP core相比各有优势,虽然Memory bits比较多,但是关键性指标ALUTs和寄存器有大幅减少,约为IP core实现的60%左右。可见,本文设计实现的滤波器在资源开销方面有较明显的优势。
(2)提高计算速度
DA算法的计算速度与系统阶数无关,只与输入位宽有关,处理时钟/输入位宽即是系统的工作速度,这种工作速度与阶数无关的性质非常适合大规模乘积和的计算,在阶数很高的滤波器中运算优势明显。对于位宽较大的输入,可以将其拆分,让电路并行工作成倍地提高处理速度,但速度的提高是以电路规模的同倍数扩大为代价的,在实际工作中需要仔细斟酌,寻找一个速度与资源的平衡点。
(3)提高系统工作频率
对本设计而言,系统对速度的要求比较高,该FIR滤波器的工作频率为64×1.228 8 MHz。对该传统结构的滤波器设计进行时序分析显示,clock时钟的时序逻辑所需的最小时钟周期为5.902 ns,信号的最大时钟频率为169.4 MHz。对基于并行DA算法的根升余弦成形滤波器设计进行时序分析显示,clock时钟的时序逻辑所需的最小时钟周期为3.823 ns,信号的最大时钟频率为261.57 MHz。同样基于并行DA算法的IPcore FIR滤波器相应的指标为292.74 MHz,3.416 ns。可以看出,相比IP core还有差距,但与传统结构相比,有很大提高。
5 、结 语
从结果分析中的几点可以看出,一方面并行DA算法性价比高于传统算法;另一方面由于对滤波器引入多相结构,使得大部分电路工作在较低频率下,减少了计算量,而且还降低了系统功耗,因此基于多速率处理技术和并行DA算法实现的根升余弦滤波器比以往的设计具有明显优势,尤其是在减少逻辑资源开销方面,非常适合逻辑资源受限的应用设计中。





 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号
 866
866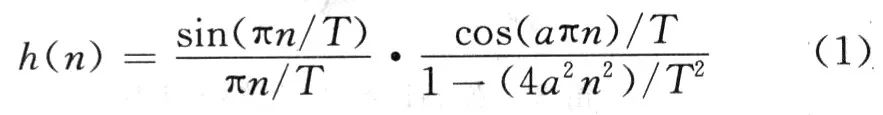


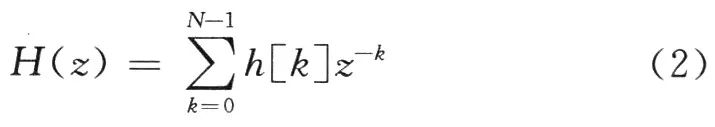
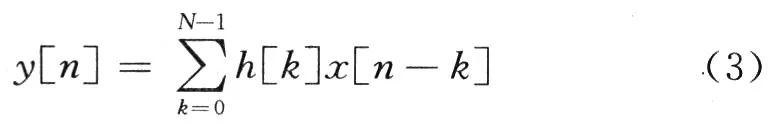

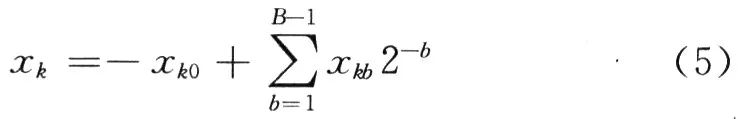
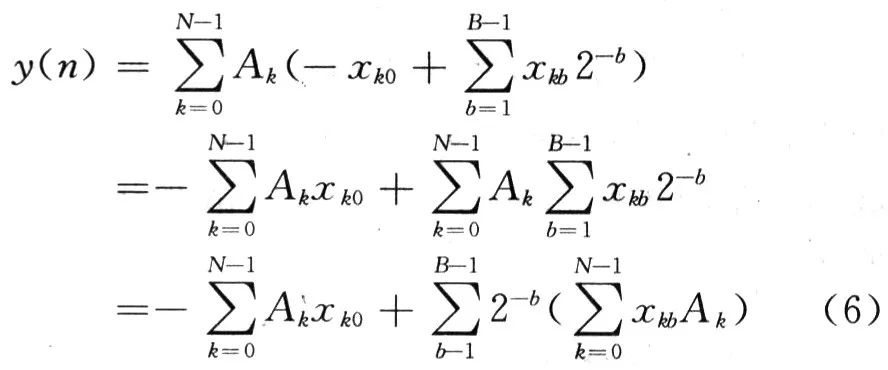
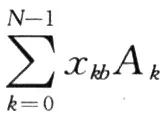
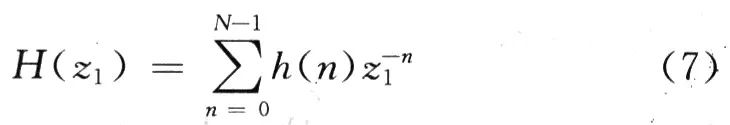
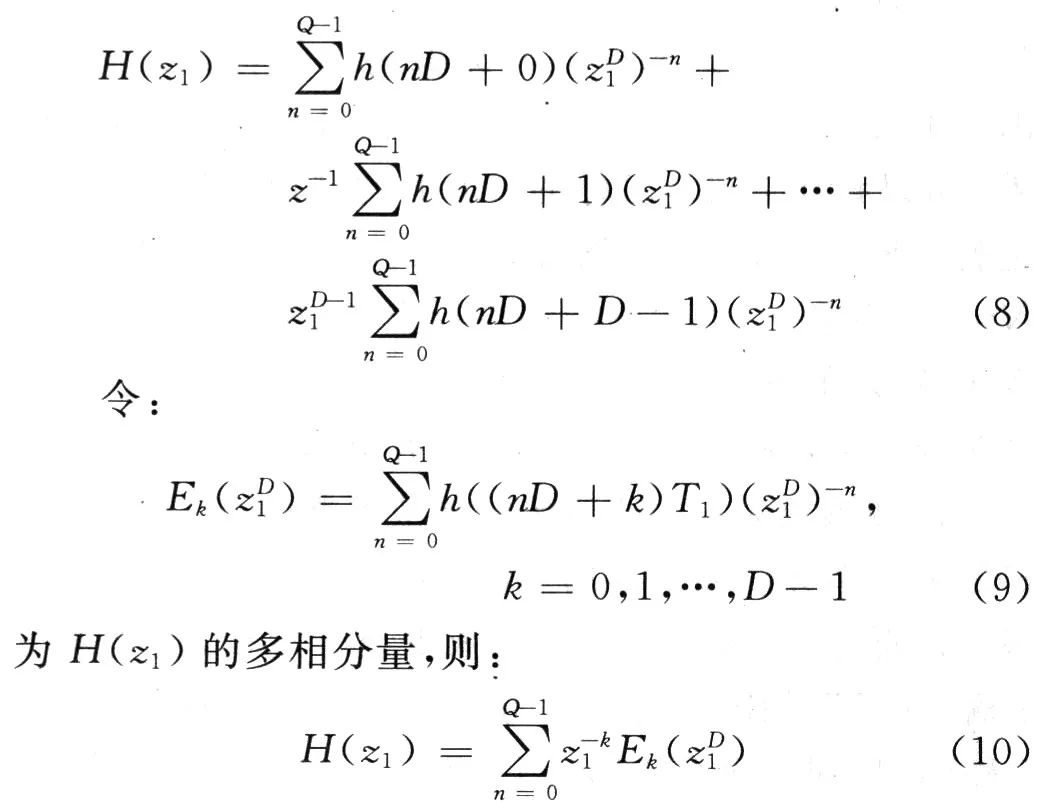








 淘帖
淘帖
