在经过之前对于开发板的使用,以及通过几个爱芯派官方给出的示例demo(mobilenet/yolov5)在开发板上的部署之后,笔者也逐渐了解了爱芯派这块开发板利用其官方的推理引擎和pipeline部署模型的整体架构。接下来就回到最开始定的主线上了——人体姿态估计。这篇文章就是记录对一些轻量化人体姿态估计模型的调研,和前期准备。
1、人体姿态估计任务介绍
下面对人体姿态估计任务做一个简单的介绍。人体姿态估计任务主要通过一张图片或者一段视频,估计图像中人物的身体的关键点,再把人体的关键点相互连接,组成类似一个“火柴人”的形象,从而把一个人当前的姿态展示出来。如下图所示,人体身体的关键点大多是一些骨骼关键点,如肘关节、肩关节、手踝关节、膝关节、脚踝关节。任务会先把这些关键点标出来,再按一定的顺序连接起来,这样邓肯就会被“剥”成最右边的那样的火柴人的形象。
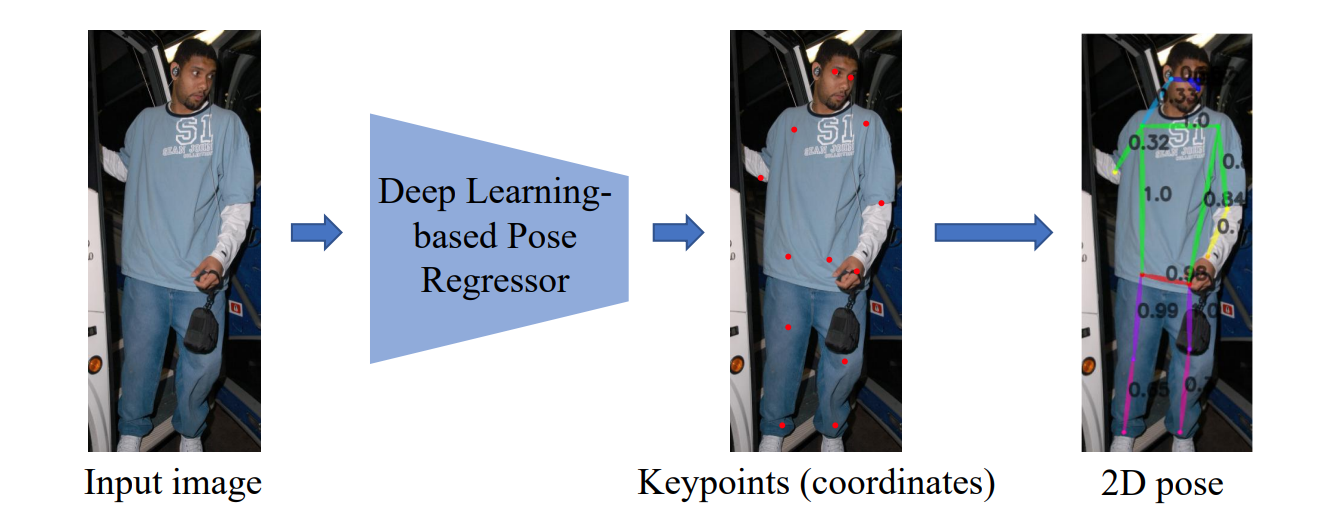
其实姿态任务识别在很多生活场景都被使用到,这里给大家举几个例子:
1、虚拟主播:大家看到B站直播时的“皮套人”,通常通过一个2D live的形象展示一个动漫形象,然后和主播同步动作。这就是通过摄像头识别当前主播姿态,再同步到虚拟形象上实现的。
2、VR游戏:大家可能用过像kinect这样的设备,用于VR体感游戏。kinect同样会识别当前用户的姿态,然后用于VR交互中。
3、活动识别。通过得到人体姿态后,再通过一个简单的分类器,可以得到当前的运动状态,如用户是否跌倒(可以帮助监控老年人),以及用户当前身体状态等。
2、人体姿态估计任务技术路线
其实人体姿态估计任务已经有很久的年头了,在当前也算是很成熟的任务了。有兴趣的朋友可以阅读下这篇综述:Deep Learning-Based Human Pose Estimation: A Survey (arxiv.org)。下面简单的对单人、多人人体姿态估计的技术路线做个小介绍:
首先是单人的,也就是照片里面只有一个人。如下图所示,现有的技术路线主要分成两派:1)是通过regression,也就是回归,直接回归出骨骼关键点的位置。2)是通过heatmap,也就是热力图,简单理解就是骨骼关键点出现的概率,“热度”越高,关键点概率越高。现在大部分模型都使用的heatmap的形式,因为有更高的准确度。
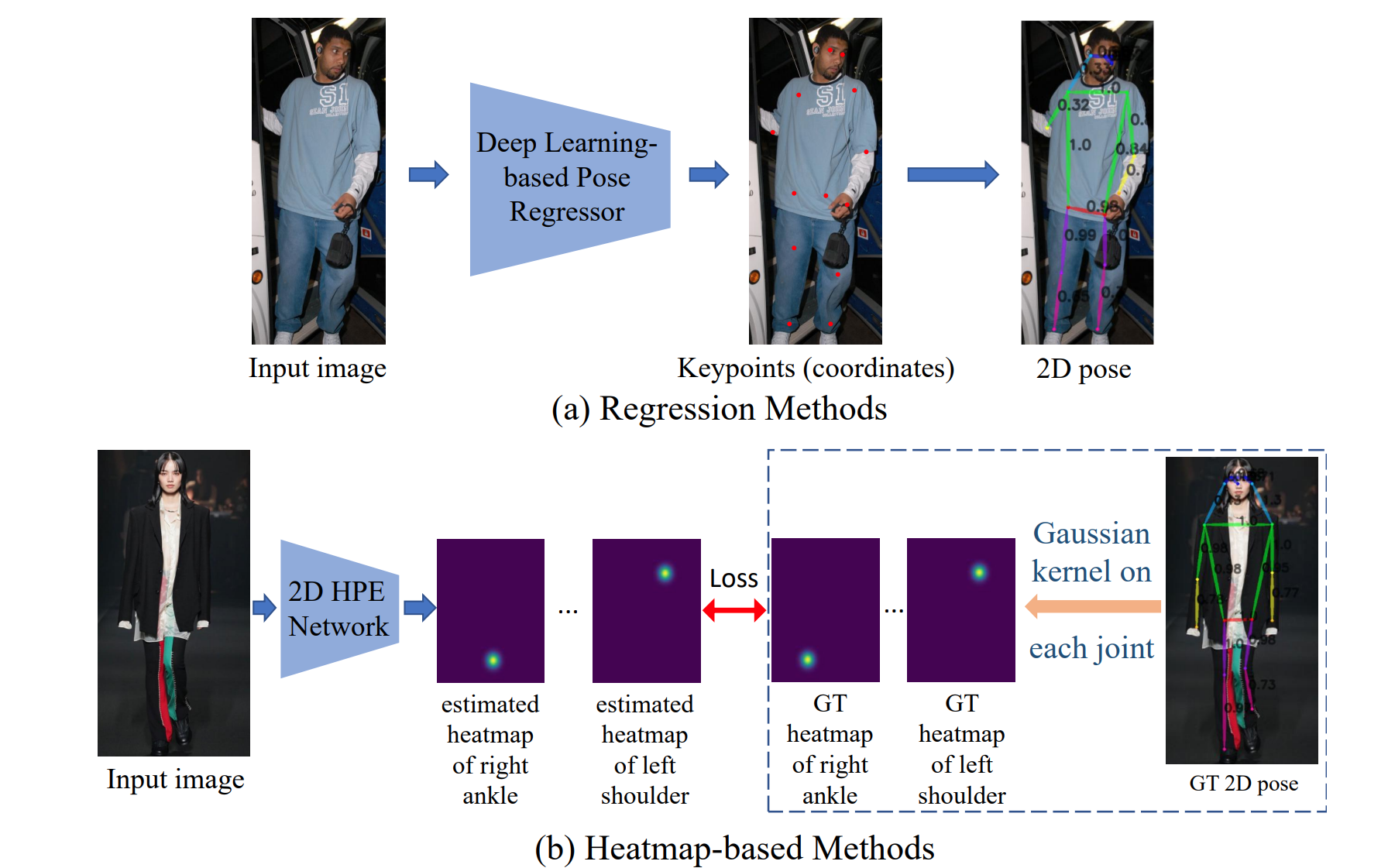
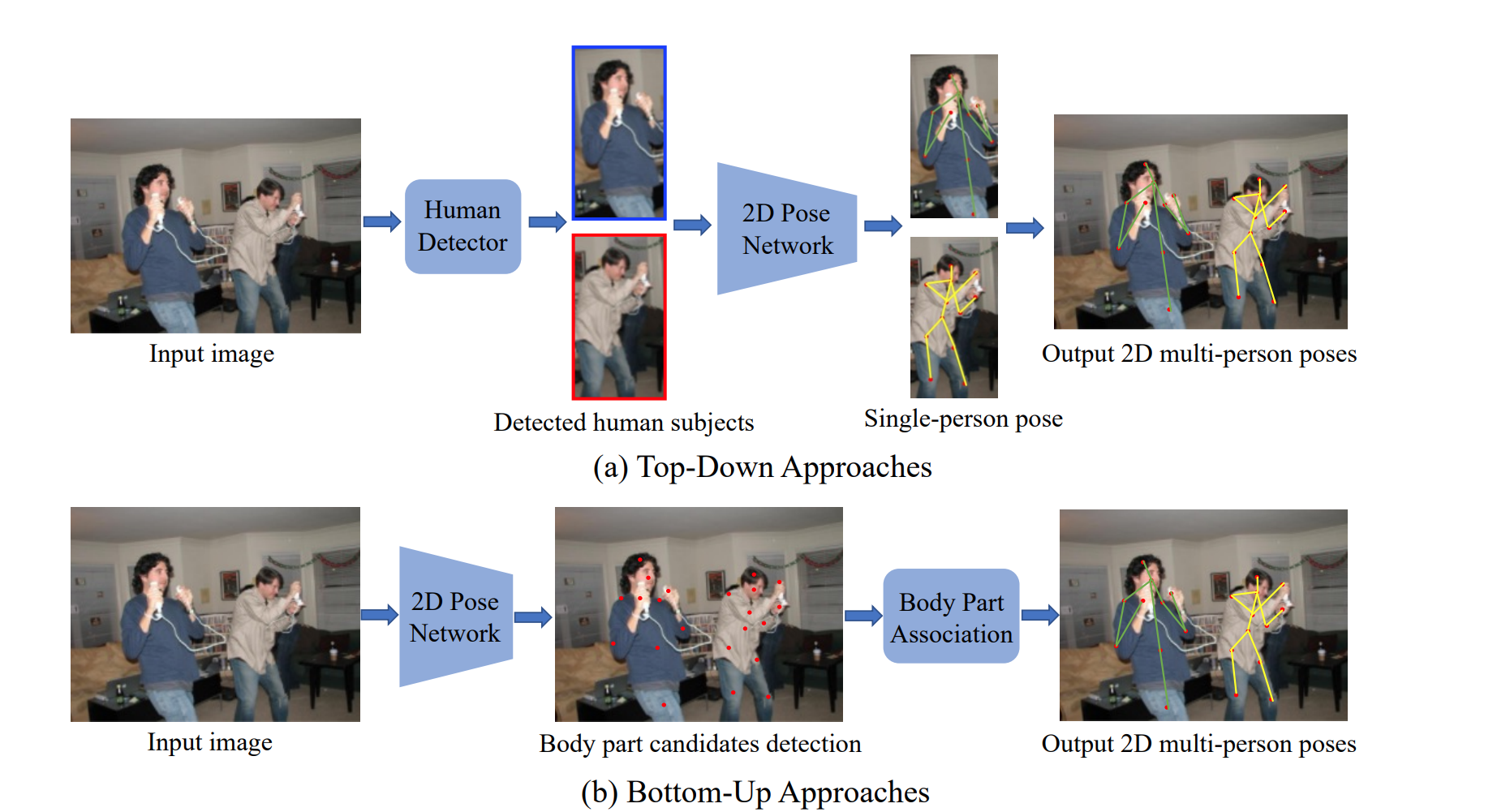
其次是多人的,多人的任务要复杂的多,因为一旦人物密集,会出现遮挡的情况。目前的模型也分为两个路径,一个是Top-down,一个是bottom-up。Top-down指的是很直接的思路,就是先找出多少个人,类似于目标检测,划出一个框,再直接使用单人的模型。Bottom-up指的是先一股脑找出所有人所有的关键点,再找出哪些关键点属于同一个人的,再进行配对。
虽然Top-down的方法比较直接,但是具有一些缺点:因为人一多,就会出现遮掩,因为需要先划分人物,因此漏检的概率高或多,而且inference时间会与人的多少成正比,当人一多,inference的时间会大大增加,不符合real time的需求。因此后面使用到的openpose模型、movenent模型都是Bottom-up类型的。
3、Openpose/lightweight openpose模型
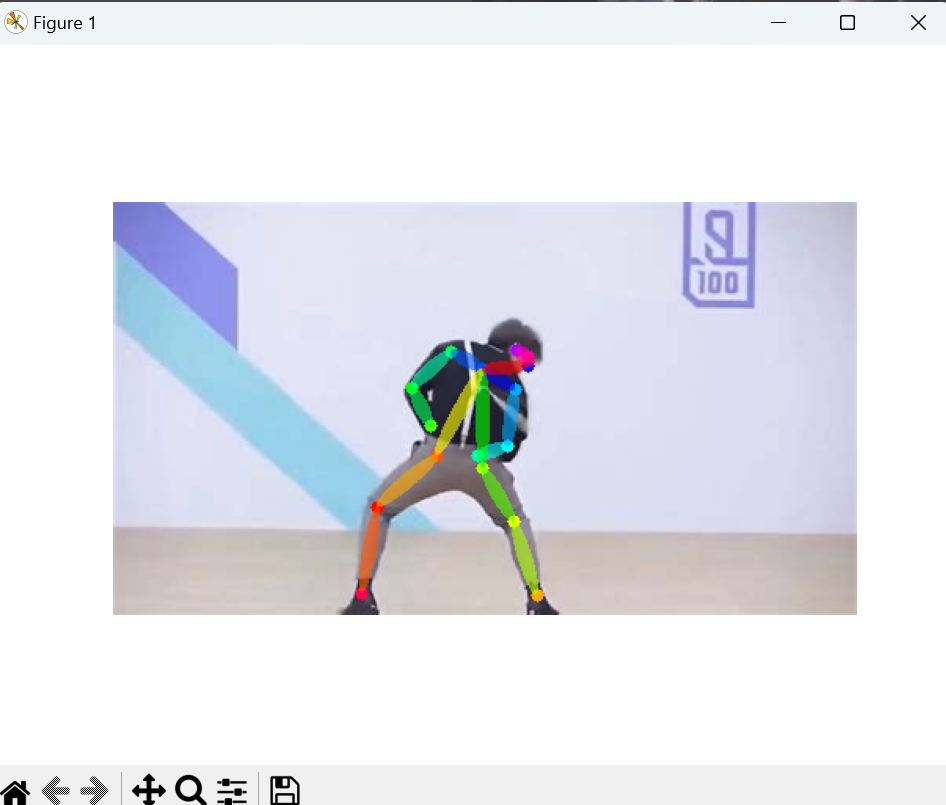
首先要用到的是Openpose模型,这应该是最有名的人体姿态估计的模型了,因为是首个开源的人体姿态估计框架。论文如下:1812.08008.pdf (arxiv.org)。如下图所示,openpose能在多人情况下达到理想的识别效果。这里简单说明一下openpose的原理:openpose就是原来的Bottom-up模型,会先生成针对关键点的heatmap图像,来预测关键点的位置;同时也会PAF图像,也叫做关节的亲和力场,哪些关节的亲和力大,那么把它们划分为同一个人。比如一个胳膊对应两个关节点。
Openpose模型最终会输出两个特征图heat_map和paf_map,对应热力图和PAF图,用于得到最终的关节点,以及连接成像下图的图样。

Openpose存在的一个问题便它其实是于比较大的模型,在GPU上运行速度也只是勉强实时。为了部署在端侧,使用较低算力的设备,我们需要进一步将其轻量化,也就是lightweight openpose项目。这个主要针对Openpose模型做一些改进,参数量下降为15% ,但是性能缺相差无几(精度降低1%)。这里不细讲了,有兴趣的朋友可以看这篇文章:
轻量级OpenPose, Lightweight OpenPose - 知乎 (zhihu.com)
针对其部署,笔者使用了一些开源的项目后,发现如下的项目比较好用,就先用其观察模型的效果:
git clone https://github.com/Hzzone/pytorch-openpose.git
在其body.py里面可以简单的写一段代码输出onnx文件观察网络结构:
class Body(object):
def __init__(self, model_path):
self.model = bodypose_model()
if torch.cuda.is_available():
self.model = self.model.cuda()
model_dict = util.transfer(self.model, torch.load(model_path))
self.model.load_state_dict(model_dict)
self.model.eval()
dummy_input = torch.randn(1, 3, 368, 368).cuda()
torch.onnx.export(self.model, dummy_input, "model/openpose_lightweight_body.onnx")
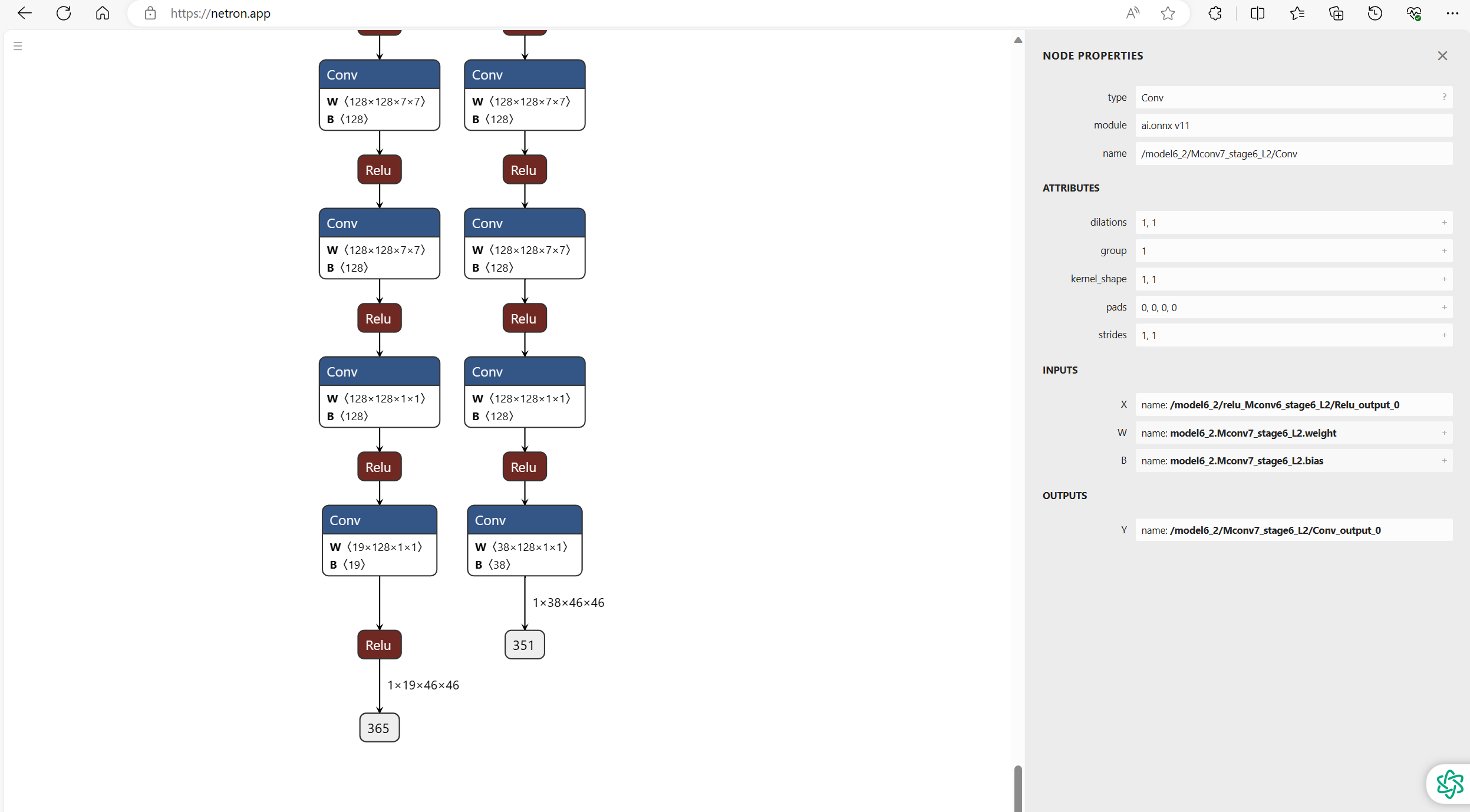
Openpose模型最终会输出了两个特征图heat_map和paf_map,shape分别为(height,width,19)和(height,width,38),其中width、height分别为输入图片的宽高/8,其实是由于最开始会通过一个VGG网络提取特征,得到输入图片的宽高/8的特征图。19表示coco数据集的关节种类个数18(即一个人体的所有关节点)+1个背景类别,38表示由这18个关节点构成的肢体的部分亲和力场(每个肢体由两个关节连接组成)。如下图所示,把导出来的onnx文件放到netron网站可以看到其具体结构。这里可以看到输出的shape,也方便我们部署的要求。
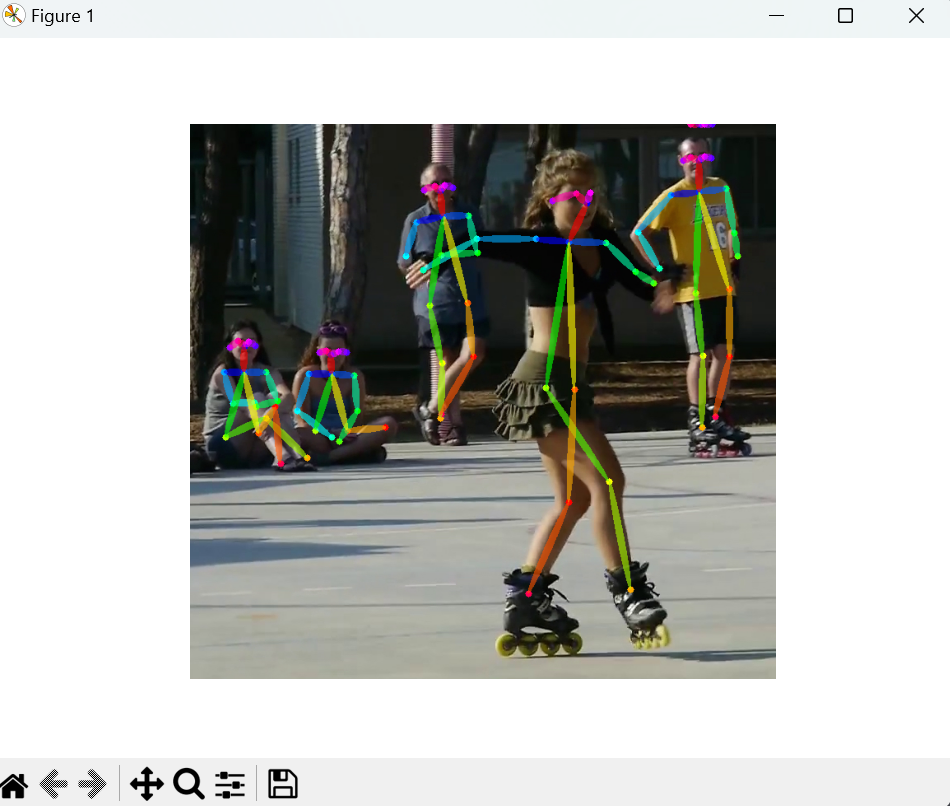
笔者这里简单的使用了几张图片作为验证,可以看到效果还算不错的,但是处理时间仍然较长,需要进一步简化模型、权重。
4、Movenet
除了Openpose外,笔者还有一个选型,就是谷歌的轻量级人体姿态估计模型MoveNet。它是更近的一个轻量级人体姿态估计模型,但是一个缺点是它没有论文,也没有官方代码,虽然有开源的tfjs模型还有tflite模型,但是也只能通过观察模型结构去反推。
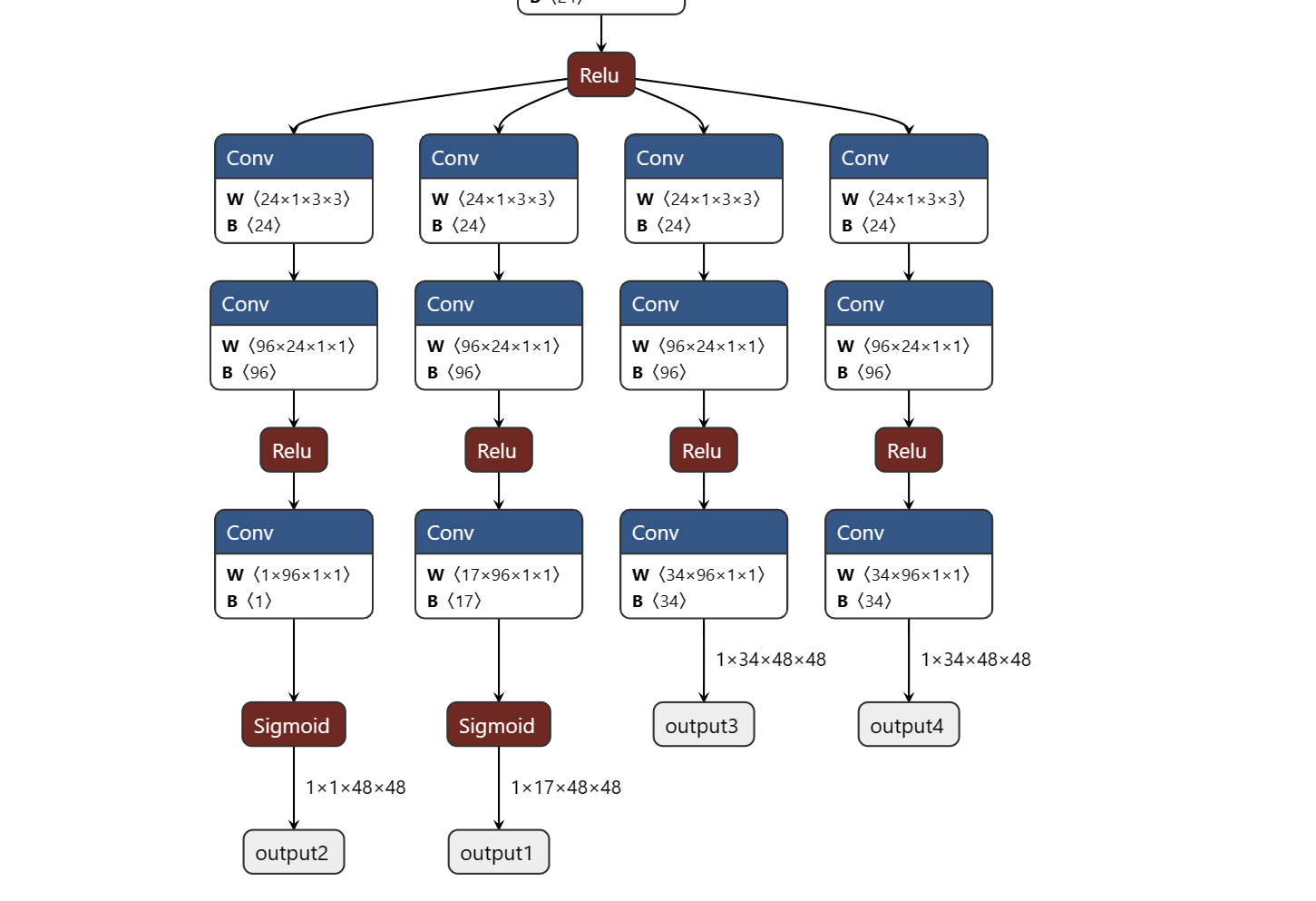
movenent的介绍在这个网站:Next-Generation Pose Detection with MoveNet and TensorFlow.js — The TensorFlow Blog通过对其学习,以及利用官方模型转换到onnx模型,打开到netron网站观察其结构,可以发现其有四个输出,分别对应预测人体实例的几何中、预测人体的全部关键点集、 预测所有关键点的位置的热力场、以及预测关键点2D偏移场,也就是每个关键点精确子像素位置的局部偏移。这与Openpose不同,但是有了更精细话的结果。
同样为了复刻movenet网络结构,笔者选择参照如下的项目进行实现。
git clone https://github.com/fire717/movenet.pytorch.git
可以按照项目readme中的步骤训练一个movenet网络模型,但是笔者训练的模型出现了一点问题,感觉输出总是差距较大,准确度不太高,也正在排查原因:


后续笔者先尝试将openpose/lightweight openpose部署在板子上,再尝试对movenent进行进一步的优化。
 电子发烧友论坛
电子发烧友论坛 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 1640
1640









 淘帖
淘帖




