鉴于KAIST的HPC根源,将DirectCXL原型放在一起的研究人员专注于使用远程直接内存访问(RDMA)协议将CXL内存池与跨系统直接内存访问进行比较。
他们使用了一个非常老式的Mellanox SwitchX FDR InfiniBand和ConnectX-3互连,以56 Gb / sec的速度运行,作为CXL努力的基准,InfiniBand的延迟确实降低了。但在过去的几代人中,它们肯定已经停止了降低,并且期望PCI-Express延迟有可能降低,我们认为,从长远来看,甚至超过InfiniBand或以太网的RDMA。可以消除的协议越多越好。
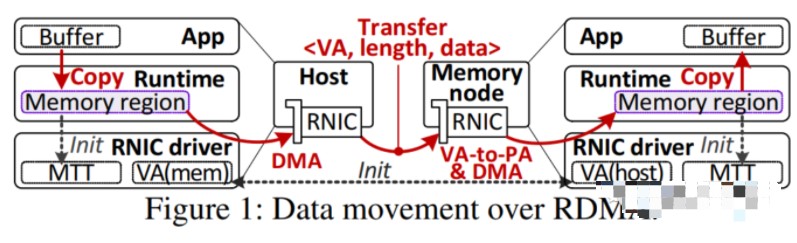
当然,RDMA最广为人知的是InfiniBand网络最初获得其传奇般的低延迟的手段,允许机器通过网络直接将数据放入彼此的主内存中,而无需通过操作系统内核和驱动程序。RDMA长期以来一直是InfiniBand协议的一部分,以至于它实际上是InfiniBand的同义词,直到该协议通过RDMA通过融合以太网(RoCE)协议移植到以太网。
有趣的事实:RDMA实际上是基于康奈尔大学研究人员(包括亚马逊网络服务的长期首席技术官Verner Vogels)和Thorsten von Eicken(我们的读者最熟悉的是RightScale的创始人和首席技术官)在1995年所做的工作,比InfiniBand的创建早了大约四年。
以下是 DirectCXL 内存集群的外观:

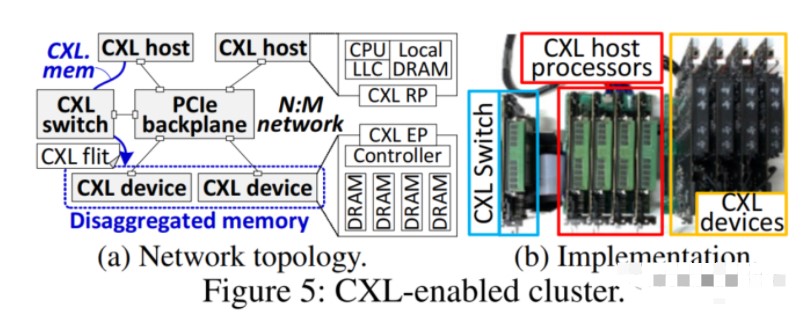
在上图右侧(在本文文末的功能图像中更详细地显示了四个内存板),它们具有FPGA创建PCI-Express链接并运行CXL.memory协议,用于在内存服务器和通过PCI-Express链接连接到它的主机之间加载/存储内存寻址。
系统中间是四台服务器主机,最右侧是一台 PCI-Express 交换机,用于将四台 CXL 内存服务器连接到这些主机。
为了测试DirectCXL内存,KAIST采用了Facebook的深度学习推荐模型(DLRM),仅使用InfiniBand上的RDMA在服务器节点上进行个性化设置,然后使用DirectCXL内存作为额外的容量来存储内存并通过PCI-Express总线共享它。在此测试中,CXL 内存方法比 RDMA 快得多,如下图所示:
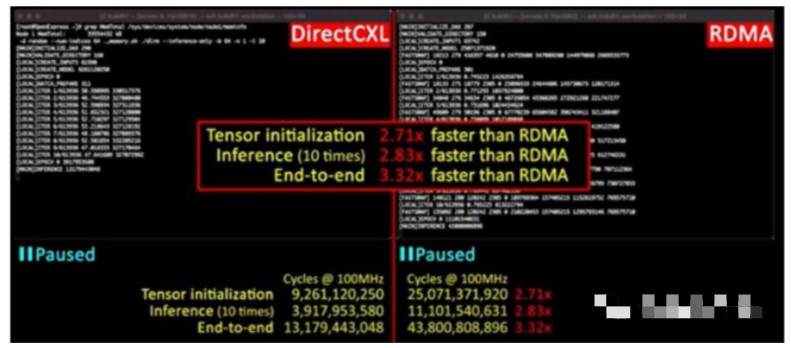
在这个子集群上,DirectCXL内存上DLRM应用程序的张量初始化阶段比在FDR InfiniBand互连上使用RDMA快2.71倍,在推理阶段,推荐者实际上根据用户配置文件提出建议的速度提高了2.83倍,推荐者从头到尾的整体性能提高了3.32倍。
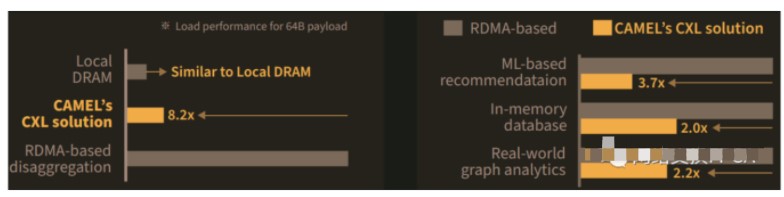
下图显示了 InfiniBand 上的本地 DRAM、DirectCXL 和 RDMA 如何堆叠,以及 CXL 与 RDMA 在各种工作负载上的性能:
以下是关于KAIST在CAMELab工作的总结部分。目前没有操作系统支持CXL内存寻址 - 没有操作系统,我们的意思是商业级Linux或Windows Server都没有,因此KAIST创建了DirectCXL软件协议栈,以允许主机使用加载/存储操作直接访问远程CXL内存。
无需将数据移动到主机进行处理 - 数据是从该远程位置处理的,就像在具有 NUMA 协议的多插槽系统中发生的情况一样。而且,与英特尔使用其 Optane 持久内存创建的相比,此 DirectCXL 驱动程序的复杂性要小得多。
“直接访问CXL设备,这与持久内存开发工具包(PMDK)的内存映射文件管理的概念类似,”KAIST研究人员在论文中写道。“但是,它比PMDK更简单,更灵活地进行命名空间管理。
例如,PMDK 的命名空间与 NVMe 命名空间非常相似,由文件系统或具有固定大小的 DAX 管理。相比之下,我们的 cxl 命名空间更类似于传统的内存段,后者直接向应用程序公开,而无需使用文件系统。
论文中有很多的实验结果,对于普通读者大都晦涩难懂。但是,我们放大的下图中显示了 DirectCXL 和 RDMA 方法之间的一些显著差异:
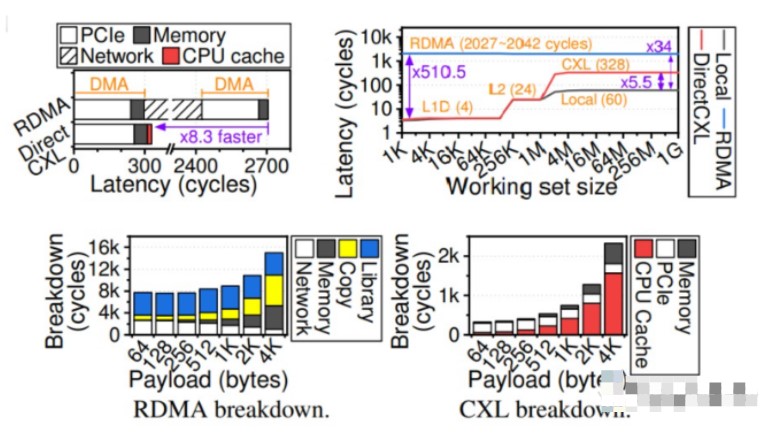
就我们而言,左上角的图表是有趣的图表。要读取64字节的数据,RDMA需要执行两次直接内存操作,这意味着它具有两倍的PCI-Express传输和内存延迟,然后InfiniBand协议在RDMA期间占用2129个周期,总共2705个处理器周期。
DirectCXL 读取 64 字节的数据只需要 328 个周期,它能够做到这一点的一个原因是 DirectCXL 协议将加载/存储请求从处理器中的最后一级缓存转换为 CXL flits,而 RDMA 必须使用 DMA 协议来读取和写入内存中的数据。
附小册子部分内容翻译:
随着大数据时代的到来,资源分解因其出色的扩展能力,成本效率和透明弹性而备受关注。将处理器和存储设备分解确实打破了数据中心和高性能计算的物理边界,成为单独的物理实体。与其他资源相比,实现以低成本支持高性能和可伸缩性的内存分解技术并非易事。
许多行业原型和基于学术模拟/仿真的研究探索了实现这种存储分解技术的广泛方法,并为使内存分解实用做出了重大努力。然而,由于几个基本挑战(高成本,有限的扩展,重数据副本和主机依赖性),内存分解的概念到目前为止还没有成功实现。
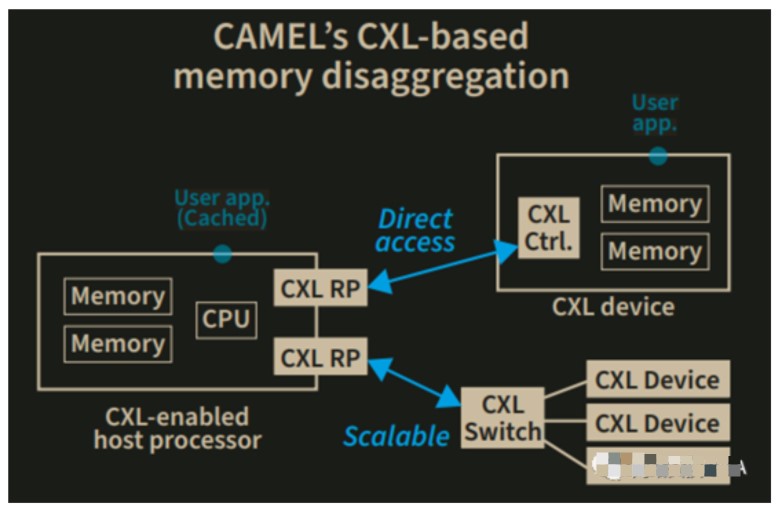
CAMEL为大型存储系统提供世界上第一个CXL解决方案框架,可以在大数据应用程序(如机器学习,内存数据库和现实图形分析)中实现出色的性能。CAMEL的CXL解决方案为内存分解开辟了新的方向,并确保了直接访问和高性能的功能。
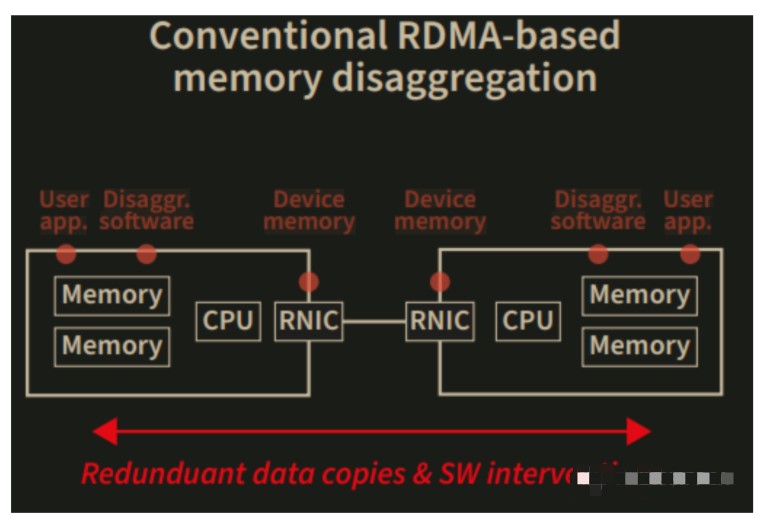
内存分解的基本思想是将主机与一个或内存节点连接,这样由于本地内存(DRAM)空间有限,它不会限制给定的任务执行。大多数现有的内存分解技术都采用远程直接内存访问(RDMA)将数据从远程内存移动到主机的本地内存。
但是,所有技术仅限于扩展并显著增加系统构建和维护成本。有两个根本原因。首先,DRAM及其存储器接口(例如DDR)被设计成完全无源的设备模块,其在没有主机侧CPU和其中的存储器控制器的帮助下不能操作。
随着更多内存节点添加到系统中,用于保存远程内存的计算过程等其他资源的数量增加,成本呈指数增长。其次,RDMA引入了冗余内存副本和软件结构干预,这反过来使得分解内存的延迟比本地DRAM访问的延迟长多个数量级。
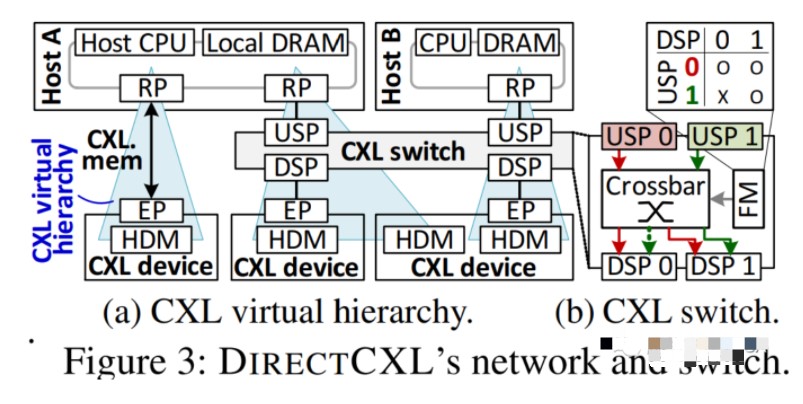
CAMEL已经推出了世界上第一个CXL解决方案(POC),该解决方案通过CXL协议直接连接主机处理器复合体和远程内存资源。CAMEL的CXL解决方案框架包括一组computing express link(CXL)硬件和软件IP,包括CXL交换机,处理器复杂IP和CXL内存控制器。解决方案框架可以完全从计算资源中分离内存资源,并实现高性能,完全扩展内存分解架构。CAMEL CXL解决方案的当前原型包括:
1.CXL器件,这是一个纯无源模块,可以使用自己的硬件控制器实现许多DRAM DIMMS。
2.启用CXL的主机处理器,包含一个或多个CXL根端口(RP)。
3.CXL网络交换机,它允许连接超过500个内存资源以简单地扩展(例如,放大)内存空间。
原作者:Timothy Morgan
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 1178
1178








 淘帖
淘帖




