介绍
随着 Arm 引入 Scalable Vector Extensions (SVE) 作为 ARMv8-2 中的可选扩展,编译器自动矢量化器可以在优化 SVE 或 Neon 之间进行选择。程序员可以通过 gcc -march编译器标志影响该选择。例如*-march=armv8.2-a+sve在 Armv8.2-A 上启用 SVE,-march=armv9-a+nosve*在 Armv9-A 上禁用 SVE。
将 SVE 与 Neon 区分开来的一个重要特征是应用于向量的每个元素(通道)的预测。通过使用向量预测,SVE 通常可以向量化 Neon 不能的循环。有时可以使用 SVE 或 Neon 对循环进行矢量化,SVE 实现更有效。例如,SVE 预测可以消除 Neon 向量化所需的一些向量比较和选择的需要。
IEEE Micro 论文“The Arm Scalable Vector Extension”(Stephens 等人,2017 年)中对 SVE 和这两个关键属性进行了很好的描述。有关 SVE 与 Neon 的示例和比较的更多详细信息,请参见白皮书“Svep into SVE and VLA programming”(F. Petrogalli,2020)。最后,在“Arm Scalable Vector Extensions and application to Machine Learning: (DA Iliescu and F. Petrogalli, 2018) 中找到了 SVE 在机器学习中的应用。
本博客描述了一个矢量化 HACCmk 基准测试中出现的热循环的案例研究。
SVE 预测提供了更多的向量化机会
考虑 HACCmk 的代码,它是美国政府 ASC CORAL RFP 中的基准之一。它是一个 n 体代码,用于计算一组 n 个物体中的一个物体由于其他物体而受到的重力。
在 HACCmk 中重要的计算内核出现在函数GravityForceKernel(…) 中,如下所示。

**加粗 **的if语句跳过相距很远的成对物体(假定力可以忽略不计)或物体本身之间的力计算。此操作是一种以牺牲一些精度为代价来减少加速执行时间所需的计算次数的方法。
就循环向量化而言,循环内的条件语句通常会阻止向量化的发生。在某些简单的情况下,编译器可以执行if 转换以允许生成的循环向量化。If-conversion通常计算采用和未采用路径的结果,并使用条件选择指令而不是分支,但是这种结果并不总是可能的。其他时候,与生成非向量代码相比,它是可能的,但被认为是次优的。
在这个 HACCmk 内核中,编译器认为if 转换没有好处。可能是因为计算成本很高并且有多个变量,每个变量都需要条件选择。在不需要时围绕力计算进行分支被认为具有更高的性能。因此,循环不能使用 Neon 进行矢量化。我们可以使用 gcc 的*-fopt-vec-info-missed*标志来确认这种情况,该标志会打印有关失败的矢量化尝试的信息。在这种情况下,它给出了以下原因,

<源>:21:23:错过:未矢量化:循环中的控制流。
这段代码是一个很好的例子,SVE 中的预测可以增加向量化的机会。谓词允许在向量中按元素处理条件语句。换句话说,使用 SVE 可以计算一个谓词向量,它指定哪些向量元素用新的力计算更新,哪些保持不变。
以下代码由 gcc 12.1 在为 SVE 和 Neon 编译时生成。Neon 编译无法对其进行矢量化并生成标量代码)。


汇编清单中的粗体文本表示与条件语句关联的代码。
在标量代码中,与 0.0 的比较 (fcmp) 和后面的条件比较 (fccmpe) 测试执行continue语句的两个条件,如果其中一个为真,则跳过循环体的其余部分 (bge .L3)。
对于 SVE 情况,谓词寄存器 p2 和 p3 处理跳过力计算的两个条件,每个条件一个。然后将这些结果合并到 p2 中,该 p2 控制哪些向量元素对其进行了力计算,哪些向量元素保持不变。
让霓虹灯矢量化
虽然 Neon 编译由于其中的控制流而未能对该循环进行矢量化,但情况并非总是如此。在此代码中,continue语句用作返回循环顶部的 goto 。 有时编译器可以使用if-conversion将控制依赖项更改为数据依赖项,然后将循环向量化。
有时,如果转换将比较和分支序列更改为基于原始条件的两个值的条件选择。在其他情况下,比较和分支序列由修改变量或保持不变的屏蔽操作替换。
对于此代码,if 转换需要在每次循环迭代中进行力计算。然后,它使用掩码将计算值或零添加到循环底部的 lax、lay 和 laz。
这样的重写导致执行一些在原始代码中不会完成的浮点计算。编译器无法知道这些额外的浮点运算是否会导致原始代码中不会发生的异常。在 gcc 中,只有在使用-fno-trapping-math时才会进行此类优化,它包含在gcc 的*-Ofast中。所以在-Ofast 下,* gcc 被允许进行这样的重写但没有这样做,要么是因为它认为它无利可图,要么是没有看到机会。
但是,重写循环以在源代码中手动显式执行if 转换可以诱使编译器使用高级 SIMD 对其进行矢量化。

这里if和continue语句消失了,值被添加到 lax 中。lay 和 laz 将是 0 或计算的力值,基于之前用于continue的相同条件。添加的值由掩码变量确定。
这将导致生成以下 Neon 矢量代码。


总是进行力计算(即使对于远处的物体和自身的物体)。换句话说,计算不再被修剪以近似和加速解决方案。但是,当满足剪枝条件时,计算值被有效地丢弃(替换为零)。这是通过两个比较(fcmgt和 fcmeq )后跟 orr 、两个和指令以及两个浮点和整数之间的转换来完成的。这些指令一起将满足修剪条件的任何向量元素归零。然后最后三个fmla指令更新 laz、lay 和 laz。
这三个可执行文件的性能比较
这三个版本的性能是使用内部循环精确模拟器评估的。建模的 CPU 内核是 Neoverse V1,所有运行都使用相同的输入数据集。Neoverse V1内核具有两个 256 位宽的 SVE 执行单元 (2x256) 和四个 128 位宽的高级 SIMD 执行单元 (4x128)。
对于 Neoverse V1,执行固定数量的矢量化工作需要两倍于 SVE 指令的 Neon 指令。在 Neoverse V1 中,SVE 和 Neon 的总矢量带宽(512 个矢量位/周期)相同。
下表显示了每个 HACCmk 二进制文件的循环执行时间和其他统计信息:
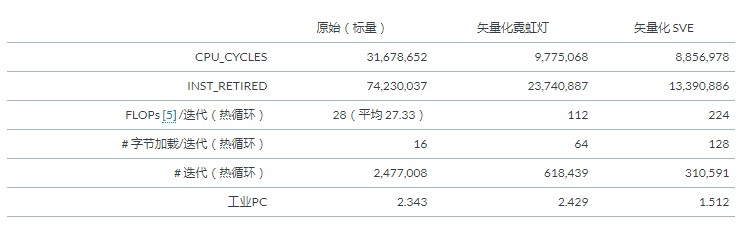
Neoverse V1 可以使用每个周期两个 256 位 SVE 指令或每个周期四个 128 位 Neon 指令来完成相同数量的浮点工作。在这种情况下,IPC 比较可能会产生误导,因为每个 SVE 指令执行两个 Neon 指令的工作。
使用的模拟器还可以提供每个指令地址的执行计数。这提供了执行每个二进制文件中的热循环的迭代次数。每次迭代的浮点运算 (FLOP) 是通过检查反汇编来计算的。如果进行静态分析,原始标量代码在热循环中有 28 个 FLOP。但由于部分循环有时会被修剪(此输入数据集的迭代次数为 4.5%),因此每次迭代的动态 FLOP 为 27.33。将每次迭代的 FLOPs 乘以迭代次数表明每个二进制文件都在执行相同的 FP 工作总量。
将原始标量代码向量化以使用 Neon 将所需的指令数量减少了 65% 。尽管由于矢量 Neon 版本而执行了任何额外的指令,但它不再修剪非常远的对象或对象本身的计算。做一些浪费的工作并丢弃结果仍然是有益的,因为 Neon 向量代码将执行周期比原始标量代码减少了 63%。
SVE 版本保留了算法的计算修剪(使用预测),并且比矢量化 Neon 版本快 26%。虽然通过预测修剪计算可能对执行的指令数量影响最小,但使用 SVE 提供的指令组合略有不同,并导致更少和更短的数据依赖链和改进的指令流。
具有详细的逐周期模拟输出允许比较每个可执行文件在热循环中花费的执行周期的分数。模拟器提供每条指令执行的次数,以及它在成为机器中最旧的指令(程序顺序)后等待退出的周期数。以下统计数据基于这些计数。
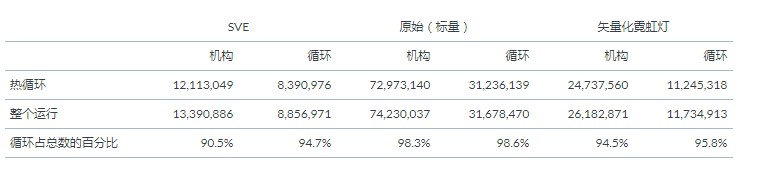
这表明在所有情况下,大约 95% 或更多的执行循环都处于热循环中。
在这种情况下或原始标量代码中,当物体相距很远时,力计算会被修剪。详细的模拟器输出显示 4.5% 的循环迭代被修剪(即 95.5% 的迭代进行了力计算)。用于力计算的周期占所有循环周期的 93%。对于使用的输入数据,尽管有一些计算浪费,但原始代码中没有足够的修剪来超过使用 Neon 代码进行矢量化的收益。
比较两个矢量化版本(Neon 和 SVE)揭示了 SVE 优于 Neon 的可能原因。对两个热循环中的指令进行分类显示:
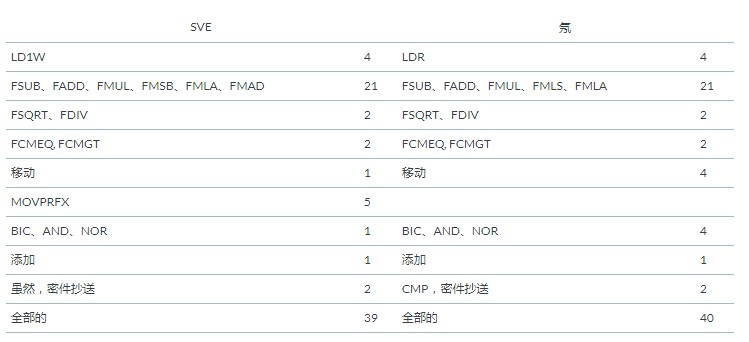
除了 MOV、MOVPRFX 和逻辑指令 BIC、AND、NOR 的不同之外,指令组合几乎相同。SVE 代码使用 NOR 设置某些谓词寄存器位,而 Neon 代码使用 BIC 和三个 AND 来屏蔽不应修改的向量元素。
在 Neon 版本中,MOV 用于制作必须在迭代中保留的寄存器副本。对于 SVE,MOVPRFX 通过告诉硬件可以将紧随其后的指令从破坏性操作(如 FMLA)转换为构造性操作(如 FMADD)来提供此功能。这只是一个提示,硬件可以选择是否将其视为 MOV 或将其转换并发出微操作以进行建设性操作。这样做可以保留 MOV 的来源,而无需显式 MOV。这种转换通常会在微操作生成期间在机器前端完成。
与此 SVE 实现相比,Neon 的额外逻辑指令(BIC 和 AND)给机器增加了更多指令和压力,MOV 也是如此。对于 SVE,使用 MOVPRFX 提示和每元素预测允许更少的指令。结合起来,这些功能可以从每个循环迭代中消除一个或两个循环,这些循环在这样一个热循环中加起来。
概括
HACCmk 说明了 SVE 如何对通常不矢量化或在没有每通道预测的情况下很难矢量化的循环进行矢量化。在此处显示的示例中,HACCmk 的热循环仅在重写后使用 Neon 进行了矢量化,知道矢量化失败的原因以及如何哄骗编译器进行矢量化。不熟悉编译器内部结构的程序员在更多情况下通过 SVE 获得向量化的好处,而无需编译器专家重写。
原作者:布赖恩·沃尔德克
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 3633
3633









 淘帖
淘帖




