比较 32 位和 64 位 NEON
前几代 Arm 指令集(例如较旧的Armv7-A)包括 32 位 Neon 指令。但是,64 位变体包括 32 位和 64 位执行状态,这意味着上一代和较新的 Neon 指令都可用,具体取决于进程正在执行的模式。
请注意,Neon 单元实际上在 128 位寄存器上运行,允许处理比处理器的其余部分更多的数据。
为什么选择 libTIFF?
我们选择优化libTIFF 4.4.0 版本,因为它是开源的,这意味着我们可以访问源代码。它是一个用于许多大型软件项目的库,包括 Android 操作系统以及 Chrome 网络浏览器。作为一个较旧的库意味着有许多领域可以针对新一代硬件进行优化。
我们使用了哪些测试平台?
值得注意的是,Neon 性能改进可能因 CPU 内核类型和所使用的操作系统和配置而异。为了测试本指南中介绍的优化,我们使用以下智能手机作为目标平台:
- Galaxy S7,型号 SM-G930F于 2016 年发布,搭载 Android 7。这款手机运行[Exynos 8890 八核]芯片组,其中包括运行频率高达 2.3 GHz 的[Cortex-A53内核。]
- Pixel 4 XL于 2019 年发布,搭载 Android 10。这款手机运行[Snapdragon 855 八核]芯片组,其中包括运行频率高达 2.8 GHz 的Qualcomm® Kryo 485内核。
为了确保我们的测量不受内核调度程序的影响,内核调度程序透明地在较慢或较快的内核之间移动应用程序,我们只启用了一个较快的内核并将“[内核扩展调节]器”设置为“性能”模式。这迫使频率达到可能的最大量。我们在 Galaxy S7 设备上执行了此操作,但在 Pixel 4 XL 上执行了测试,没有进行此更改。执行此操作的过程可能涉及从源代码构建 Android 操作系统本身,这超出了本文的范围。
我们如何衡量性能以及使用哪些图像进行测试?
我们使用了一个带有两个单独图像的自定义 Android 应用程序。每个图像都会导致 libtiff 中不同区域的代码运行。我们使用原始代码和我们的 Neon 优化版本处理图像。图像和代码的处理完成后,应用程序会显示性能统计信息和比较。
图像 1 是带有黑白文本的“翻转”灰度图像。它存储为每像素 8 位。它的方向是“右上角”,所以第一个像素实际上是图像的右上角。此图像使用了两种 Neon 优化:一种用于将 8BPP 转换为 32BPP,另一种用于水平翻转。

图 2 是类似的图像,但文本后面的背景颜色不同。它以 CMYK 格式存储,并利用 Neon 优化将 CMYK 转换为 RGBA。

当然,从源代码构建软件库时,编译器选项也很重要。在我们的例子中,我们使用了 libTIFF 的默认构建选项,该选项使用 -O2 优化标志。构建命令行太复杂而无法完整包含;但是,我们在这里有一个源文件的简化版本:
全屏1
$ aarch64-linux-android24-clang -O2 -c SOURCE_FILE.c -fPIC -o SOURCE_FILE.o
我们优化了哪些代码区域?
首先,我们选择了以下代码区域进行优化:
- 优化1:将单通道颜色格式转换为RGBA颜色格式。
- 优化2:翻转整个图像。
- 优化3:将CMYK颜色格式转换为RGBA颜色格式。
优化1:将Single Channel颜色格式转换为RGBA颜色格式
用于此优化的 Neon 内在函数:[vld1q_lane_u32],[vst1q_u32]
图 1是黑白的。在这种情况下,数据以 8BPP(灰度)存储。当 TIFFImageRGBARead 提取图像时,像素被转换为 RGBA。在这种情况下,我们只是加载每像素 8 位的图像,扩展为每像素 32 位(每通道 8 位)并在 UI 中显示图像。
值得注意的是,变量“BWmap”是一个将 8 位灰度值转换为 32 位值的查找表。
libTiff 也使用这个查找表作为一个机会来轻松地提供灰度图像的反转。对于我们的示例图像,它采用 8 位值 B 并返回一个 32 位值,其中 B 复制到每个 8 位通道 - 255 插入到 alpha 通道中。
这是原始代码。
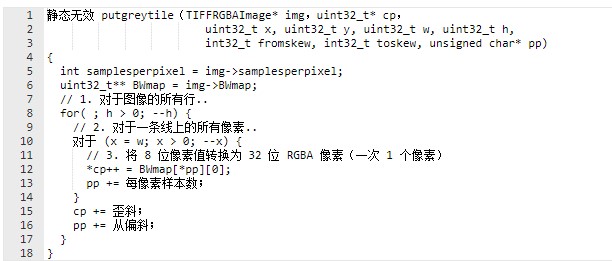
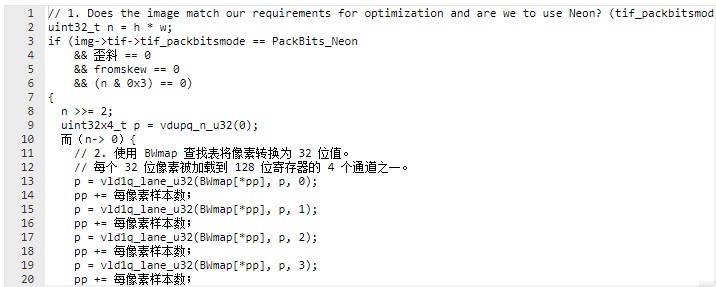
这是 64 位 Neon 优化版本。请注意,为简单起见,我们将优化“toskew”和“fromskew”值为零的最常见用例。

优化 1 的结果(将灰度转换为 RGBA):

优化2:翻转整个图像
此优化中使用的 Neon 指令:[vcreate_u8]、[vcombine_u8]、** [vqtbl1q_u8]、[vld1q_u8]、** [vst1q_u8]
TIFF 允许以任何正交布局存储图像。本质上,内存中的第一个像素可能是图像的左上角、右上角、左下角或右下角。如果 TIFF 中的图像是从右到左存储的,并且我们希望像素采用从左到右的布局(正如我们在 Android 图像视图中所希望的那样),那么我们需要执行水平翻转。这与您可能对移动设备上的图像或照片执行的翻转操作非常相似。
这是原始代码。它由两个小循环组成,它们逐行颠倒像素的顺序。需要注意的是,每个像素都是 32 位(RGBA 颜色格式),因此像素行一次反转 32 位(而不是逐字节)。这确保了颜色通道的顺序不受干扰。

这是 64 位 Neon 优化版本。为简单起见,我们仅在图像宽度为 8 像素的倍数时应用 Neon 优化。
uint8x8_t reverse2 = vcreate_u8(0x0302010007060504ull);
uint8x16_t reverseIndices = vcombine_u8(reverse1, reverse2);
而(左<右){
uint8x16_t leftPixels = vld1q_u8((uint8_t*)left);
uint8x16_t reversedLeftPixels = vqtbl1q_u8(leftPixels, reverseIndices);
uint8x16_t rightPixels = vld1q_u8((uint8_t*)right);
uint8x16_t reversedRightPixels = vqtbl1q_u8(rightPixels, reverseIndices);
vst1q_u8((uint8_t*)left, reversedRightPixels);
vst1q_u8((uint8_t*)right, reversedLeftPixels);
left += 4;
right -= 4;
}
}
优化 2 的结果(图像翻转操作):

优化3:将CMYK颜色格式转换为RGBA颜色格式
用于此优化的 Neon 内在函数:[vdupq_n_u16]、[vld1_u8]、[vmovl_u8]、[vsubq_u16]、[vget_low_u16]、 [vget_high_u16]、[vmul_lane_u16]、[vget_lane_u16]。
图像 2以 CMYK(青色、品红色、黄色和黑色)格式存储像素。CMYK 用于打印,流行的图像编辑程序通常支持将文件加载和保存为 CMYK。TIFF 支持使用 TIFFReadRGBA 接口将 CMYK 自动转换为 RGBA(尽管 alpha 通道 A 始终输出为 255)。
要将 CMYK 转换为 RGB,libtiff 使用以下计算:
R = 255 x (1 - C) x (1 - K)
G = 255 x (1 - M) x (1 - K)
B = 255 x (1 - Y) x (1 - K)
与其他优化一样,我们插入了一个 if 语句来检查是使用原始代码还是使用 Neon 代码。为清楚起见,我们不在这里显示 if 语句。
// 原代码使用宏 UNROLL8 展开代码和
// 每次迭代处理 8 个像素。
// 这个宏实际上包含了一个遍历单行的 for 循环
//(“w”参数是图像的宽度)。
#define UNROLL8(w, op1, op2) { \
uint32_t _x; \
// M1。对于图像的整个宽度..
对于 (_x = w; _x >= 8; _x -= 8) { \
操作1;\
// M2。重复 8 个像素。
重复8(op2);\
} \
// M3。对于任何剩余的像素..
如果 (_x > 0) { \
操作1;\
案例8(_x,op2);\
} \
} // 宏 UNROLL8() 结束
// 1.对于图像的每一行(“h”是图像高度)
for( ; h > 0; --h) {
这是 64 位 Neon 优化版本。同样,为简单起见,我们只优化了不需要倾斜的情况。换句话说,“toskew”和“fromskew”的值为零。
// VTBL 的索引,将复制每个像素的 K 值
uint8x8_t dupK1 = vcreate_u8(0xff06ff06ff06ff06ull);
uint8x8_t dupK2 = vcreate_u8(0xff0eff0eff0eff0eull);
uint8x16_t kindices = vcombine_u8(dupK1, dupK2);
// 将获取最终结果的索引
uint8_t 结果索引[16] = {0,1,2,-1,4,5,6,-1,8,9,10,-1,12,13,14,-1};
而(cp < endp){
uint8x16_t v255 = vdupq_n_u8 (255);
uint8x16_t src_u8 = vld1q_u8(pp);
uint16x8_t subl = vsubl_u8(vget_low_u8(v255), vget_low_u8(src_u8));
uint16x8_t subh = vsubl_high_u8(v255, src_u8);
uint8x16_t kl = vqtbl1q_u8(subl, kindices);
uint8x16_t kh = vqtbl1q_u8(subh, kindices);
优化 3 的结果(将 CMYK 转换为 RGBA):

自动编译器优化
值得注意的是,用于构建库的编译器选项会对程序的性能产生很大影响。这包括一些自动生成霓虹灯。为了证明这一点,我们尝试使用优化选项 -O0(根本没有优化)构建和测试 libTIFF 的原始非 Neon 版本,并将此构建与默认的 -O2(应用最合适的优化)进行比较。
以下是 Galaxy S7 上的结果:

除了上述改进之外,我们还尝试优化了一些 TIFF 图像中使用的 PackBits 压缩公式。在这种情况下,我们的优化只显示了最小的改进,其中图像数据不能很好地一次处理多个字节。这可能是由于主要案例的自动霓虹灯生成已经是最佳的。
最后的评论
如您所见,不同类型的 CPU 的结果各不相同。但是,使用 Neon 可以获得很大的收益。 值得指出的是,以这种方式手动优化代码可能并不总是一个好主意,您必须注意正在处理的数据或图像以及编译器内置的优化功能。
原作者:拉明·扎吉
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2620
2620









 淘帖
淘帖




