在过去的十年中,ARM CPU厂商多次尝试打入高性能 CPU 市场,因此我们看到大量关于 ARM 努力的文章、视频和讨论也就不足为奇了,其中许多文章关注的是两种指令集架构(ISA)的差异。
在本文中,我们将汇集研究、来自非常熟悉 CPU 的人的评论以及我们的一些内部数据,以说明为什么专注于 ISA 是浪费时间,并让我们开始在我们的小冒险中,让我们参考 Anandtech 对 Jim Keller 的采访,Jim Keller 是一位工程师,他曾参与过多种成功的 CPU 设计,包括 AMD 的 Zen 和 Apple 的 A4/A5。
“关于指令集的争论是一个非常悲伤的故事。”Jim keller在接受AnandTech采访时说。完整采访请查看文章《Jim Keller:在指令集上辩论是一件悲哀的事情》
CISC vs RISC:过时的辩论
x86 历史上被归类为 CISC(复杂指令集计算)ISA,而 ARM 被归类为 RISC(精简指令集计算)。最初,CISC 机器旨在执行更少、更复杂的指令,并为每条指令做更多的工作。RISC 使用更简单的指令,执行起来更容易、更快。今天,这种区别已不复存在。用Jim keller的话来说:
“RISC 刚问世时,x86 是半微码(half microcode)。所以如果你看一下die,一半的芯片是 ROM,或者可能是三分之一。从事RISC 人可以说 RISC 芯片上没有 ROM,因此我们获得了更高的性能。但是现在ROM太小了,找不到了。其实加法器这么小,你很难找到吗?今天限制计算机性能的是可预测性,两个大的是指令/分支可预测性和数据局部性。”
简而言之,就性能而言,RISC/ARM 和 CISC/x86 之间没有有意义的区别。重要的是保持内核的供给,并提供正确的数据,这些数据专注于缓存设计、分支预测、预取以及各种很酷的技巧,比如预测加载是否可以在存储到未知地址之前执行。
在2013 年,Blem 等研究人员发现了一种方法。研究了 ISA 对各种 x86 和 ARM CPU [1]的影响,发现 RISC/ARM 和 CISC/x86 在很大程度上已经收敛。
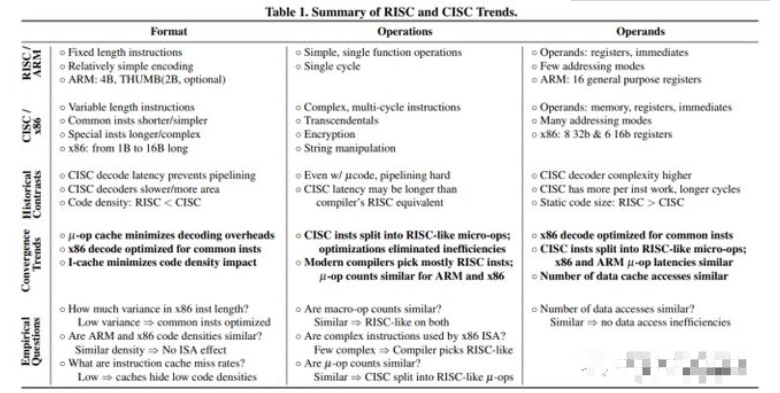
来自威斯康星大学论文的表格,显示了 RISC/ARM 和 CISC/x86 之间的收敛趋势
Blem等人得出的结论是,ARM 和 x86 CPU 在功耗和性能方面存在差异,主要是因为它们针对不同的目标进行了优化。指令集在这里并不重要,重要的是实现指令集的 CPU 的设计:
他们研究的主要发现是:
- 尽管平均周期计数差距 <= 2.5 倍,但实现之间存在很大的性能差距。
- 指令计数和混合与一阶 ISA 无关。
- 性能差异是由独立于 ISA 的微架构差异产生的。
- 能耗再次与 ISA 无关。
- ISA 差异具有实施意义,但现代微架构技术使它们没有实际意义;一个 ISA 从根本上说并不是更有效。
- ARM 和 x86 实现只是针对不同性能级别优化的设计点
以上观点来自论文《Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures》
换句话说,ARM ISA 与低功耗没有任何关系。同样,x86 ISA 与高性能无关。我们今天熟悉的基于 ARM 的 CPU 恰好是低功耗的,因为 ARM CPU 的制造商将他们的设计定位于手机和平板电脑。英特尔和 AMD 的 x86 CPU 以更高的性能为目标,具有更高的功率。
为了给 ISA 发挥重要作用的想法泼冷水,英特尔以基于 x86 的 Atom 内核为目标。Federal University of Rio Grande do Sul [6] 进行的一项研究得出结论:“对于所有测试用例,基于 Atom 的集群被证明是在低功耗处理器上使用多级并行性的最佳选择。”
正在测试的两种内核设计是 ARM 的 Cortex-A9 和英特尔的 Bonnell 内核。有趣的是,Bonnell 是一种有序设计,而 Cortex-A9 是一种无序设计,应该为 Cortex-A9 带来性能和能源效率的胜利,但在研究中使用的测试中,Bonnell 出现了在这两个类别中都领先。
解码器差异:杯水车薪
另一个经常重复的真理是 x86 有一个显著的“ecode tax”障碍。ARM 使用固定长度的指令,而 x86 的指令长度不同。因为您必须在知道下一条指令从哪里开始之前确定一条指令的长度,所以并行解码 x86 指令更加困难。这对于 x86 来说是一个缺点,但对于高性能 CPU 来说,这并不重要,用 Jim Keller 的话来说:
“有一段时间我们认为可变长度指令真的很难解码。但我们一直在想办法做到这一点。.所以当你在建造小型电脑时,固定长度的指令看起来真的很好,但如果你正在建造一台非常大的电脑,预测或找出所有指令的位置,它并没有支配die。所以没那么重要。
我们深入并亲自对此进行了检查。
通过未记录的 MSR 禁用 op 缓存后,我们发现 Zen 2 的 fetch 和 decode 路径比 op cache 路径消耗大约 4-10% 的核心功率,或 0.5-6% 的封装功率。在实践中,解码器将消耗更少的核心或封装功率。Zen 2 并非设计为在禁用微操作缓存的情况下运行,并且我们使用的基准 (CPU-Z) 适合 L1 缓存,这意味着它不会对内存层次结构的其他部分造成压力。对于其他工作负载,来自 L2 和 L3 高速缓存以及内存控制器的功耗将使解码器的功耗变得不那么重要。
事实上,在禁用 op 缓存的情况下,一些工作负载的功耗降低了。解码器的功耗被其他核心组件的功耗所淹没,特别是如果操作缓存让它们得到更好的馈送。这与Jim Keller的评论一致。
研究人员也同意这个观点。
2016 年,Helsinki Institute of Physics[2]支持的一项研究着眼于英特尔的 Haswell 微架构。在那里,Hiriki 等人估计,Haswell 的解码器消耗了 3-10% 的封装功率。该研究得出的结论是,“x86-64 指令集并不是生产节能处理器架构的主要障碍。”
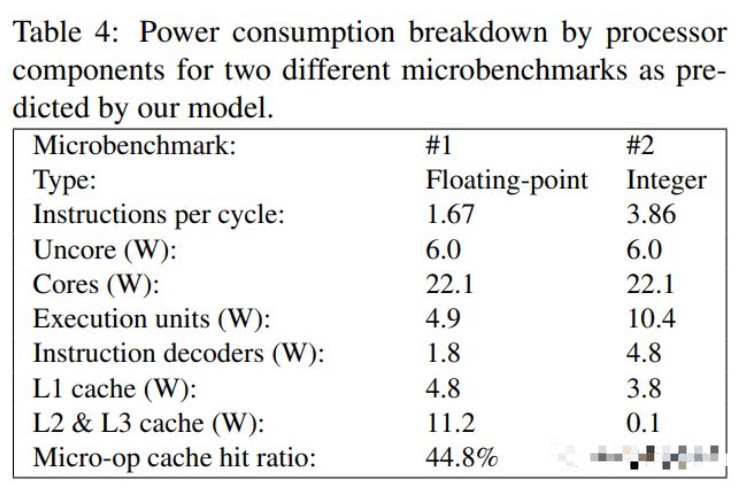
Hiriki 等人使用综合基准开发模型来估计单个 CPU 组件的功耗,并得出结论认为解码器功耗很小
在另一项研究中,Oboril 等人 [5] 在 Intel Ivy Bridge CPU 上测量获取和解码能力。虽然那篇论文专注于为核心组件开发一个准确的功率模型,并没有直接得出关于 x86 的结论,但它的数据再次表明解码器的功率是沧海一粟。
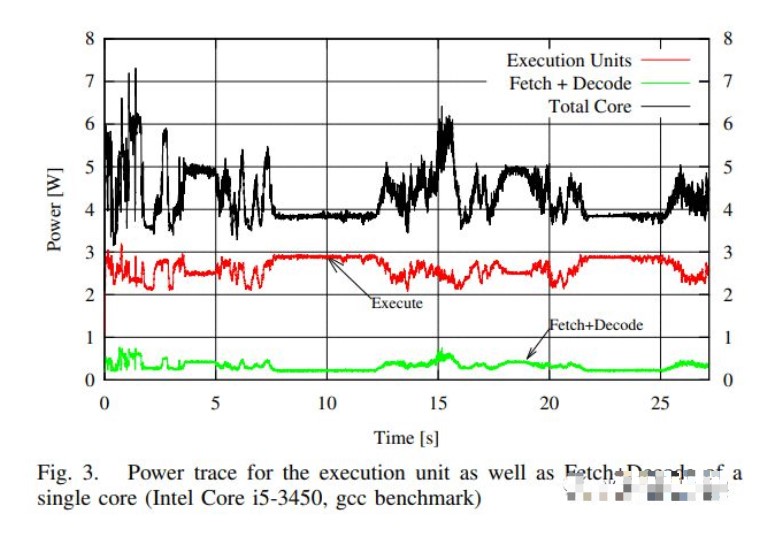
Oboril 等人对 Ivy Bridge 功耗的估计。与其他核心组件相比,Fetch+Decode 的能力微不足道
但显然解码器功率不是零,这意味着它是一个潜在改进的领域。毕竟,当您受到功率限制时,每一瓦特都很重要。即使在台式机上,多线程性能也常常受到功率的限制。我们已经看到 x86 CPU 架构师使用 op 缓存来提供每瓦性能,所以让我们从 ARM 方面看一下。
ARM 解码也很贵
Hirki 等人还得出结论:“切换到不同的指令集只会节省少量功率,因为在现代处理器中无法消除指令解码器。”
ARM Ltd 自己的设计就是证明。高性能 ARM 芯片采用微操作缓存来跳过指令解码,就像 x86 CPU 一样。2019 年,Cortex-A77 引入了 1.5k 条目操作缓存[3]。设计运算缓存并非易事——ARM 的团队在至少六个月的时间里调试了他们的运算缓存设计。显然,ARM 解码的难度足以证明花费大量工程资源尽可能跳过解码是合理的。Cortex-A78、A710、X1 和 X2 还具有运算缓存,表明该方法在蛮力解码方面取得了成功。
三星还在其 M5 上引入了运算缓存。在一篇详细介绍三星 Exynos CPU [4]的论文中,解码能力被称为实现操作缓存的动机:
“随着设计从 M1 中的每个周期提供 4 条指令/微指令变为 M3 中的每个周期 6 条(未来的目标是增长到每个周期 8 条),获取和解码能力是一个重要的问题。M5 实现添加了一个微操作缓存作为替代 uop 供应路径,主要是为了节省可重复内核的获取和解码能力。”——《Evolution of the Samsung Exynos CPU Microarchitecture》
就像 x86 CPU 一样,ARM 内核使用 op 缓存来降低解码成本。ARM 的“解码优势”并不足以让 ARM 避免操作缓存。并且***的使用,使解码功率变得更不重要。
ARM指令解码成微操作?
Gary Explains 在标题为“ RISC vs CISC– Is it Still a Thing ? “,他在随后的视频中重复了这一说法。
Gary 是不正确的,因为现代 ARM CPU 还将 ARM 指令解码为多个微操作。事实上,“减少微操作扩展”使 ThunderX3 的性能比 ThunderX2 提高了 6%(Marvell 的 ThunderX 芯片都是基于 ARM 的),这比故障中的任何其他原因都要多。

Marvell 在 Hot Chips 2020 上展示的幻灯片。重点(红色轮廓)由我们添加
我们还快速浏览了富士通 A64FX 的架构手册,这是为日本 Fugaku 超级计算机提供动力的基于 ARM 的 CPU。A64FX 还将 ARM 指令解码为多个微操作。
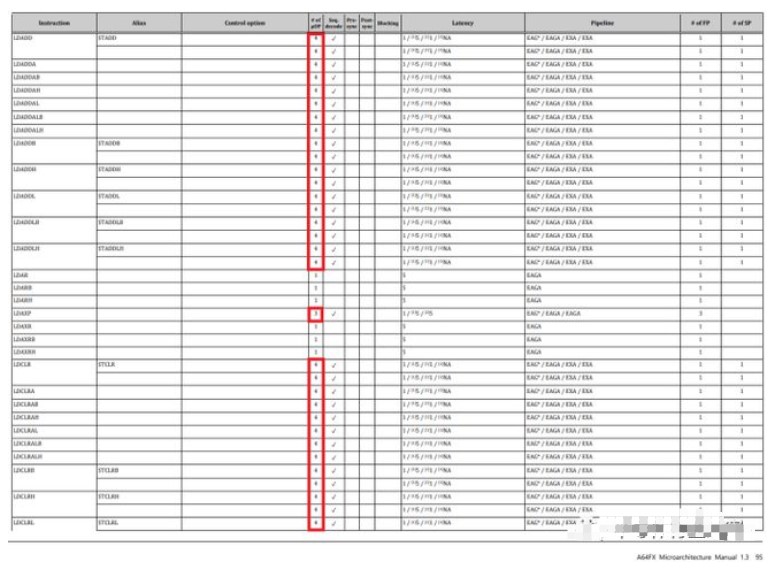
A64FX 架构手册中的部分指令表,位于 ARMv8 基本指令部分。我们在解码到多个微操作的指令上添加的重点(红色轮廓)
如果我们深入看,一些 ARM SVE 指令会解码为数十个微操作。例如,FADDA(“浮点加法严格有序归约,以标量累加”)解码为 63 个微操作。其中一些微操作单独具有 9 个周期的延迟。对于在单个周期中执行的 ARM/RISC 指令来说,就这么多了……
另外需要注意的是,ARM 并不是一个纯粹的加载存储架构。例如,LDADD 指令从内存中加载一个值,添加到它,然后将结果存储回内存。A64FX 将其解码为 4 个微操作。
x86 和 ARM:都因遗留问题而臃肿
这对他们中的任何一个都没有关系。
在 Anandtech 的采访中,Jim Keller 指出,随着软件需求的发展,x86 和 ARM 都随着时间的推移增加了功能。当它们进入 64 位时,两者都得到了一些清理,但仍然是经过多年迭代的旧指令集,迭代不可避免地会带来臃肿。
Keller 好奇地指出,RISC-V 没有任何历史遗留文呢提,因为它“处于复杂性生命周期的早期”。他继续:
“如果我今天想真正快速地构建一台计算机,并且我希望它能够快速运行,那么 RISC-V 是最容易选择的。它是最简单的一个,它具有所有正确的功能,它具有您实际需要优化的正确的前八条指令,而且它没有太多的垃圾。”
如果遗留膨胀起重要作用,我们可以期待很快会出现 RISC-V 的猛攻,但我认为这不太可能。旧版支持并不意味着旧版支持必须快速;它可以进行微编码,从而最大限度地减少芯片面积的使用。就像可变长度指令解码一样,这种开销在现代高性能 CPU 中不太重要,因为芯片区域由缓存、宽执行单元、大型乱序调度程序和大型分支预测器主导。
结论:实施很重要,而不是ISA
我很高兴看到来自 ARM 的竞争,因为高端 CPU 空间需要更多玩家,但由于指令集差异,ARM 玩家并没有超越 Intel 和 AMD。要赢得胜利,ARM 制造商将不得不依靠其设计团队的技能。或者,他们可以通过针对特定的功率和性能目标进行优化来超越英特尔和 AMD。AMD 在这里尤其容易受到攻击,因为它们使用单核设计来涵盖从笔记本电脑和台式机到服务器和超级计算机的所有内容。
原作者:半导体行业观察
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2948
2948




 淘帖
淘帖




