在处理繁重的计算工作负载(例如 ML 推理)时,优化和分析是必不可少的。它需要正确的方法和正确的工具。
精简
Streamline 是一种工具,可让您分析在基于 Arm 的移动设备上运行的程序。它提供 CPU 和 GPU 计数器。GPU 计数器对于 GPU ML 推理或组合的 ML 和图形应用程序特别有用。我们可以使用 Streamline 估计的最重要的指标是:
- CPU 使用率(包括每个核心的活动);
- GPU 使用情况(包括片段和非片段队列的使用);和
- GPU显存带宽
Streamline 包含在 Arm Mobile Studio 中,可以从我们开发人员门户下载。
实际例子
在我们之前的一篇博客中,我们描述了一个AR 过滤器项目更多信息")。让我们看看 Streamline 如何帮助我们分析应用程序的性能。
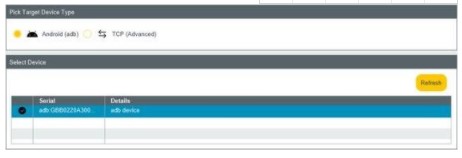
在 Streamline 中,我们可以看到通过 adb 连接的设备列表。
选择设备后,我们可以看到可用于分析的 Android 包。
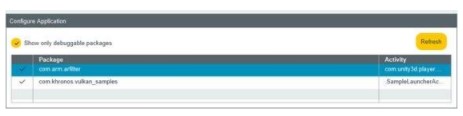
包必须是“可调试的”才能使用 Streamline 进行分析。
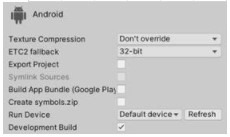
Unity 开发人员注意事项 :要使应用程序包“可调试”,您应该在构建设置中启用“开发构建”选项。*
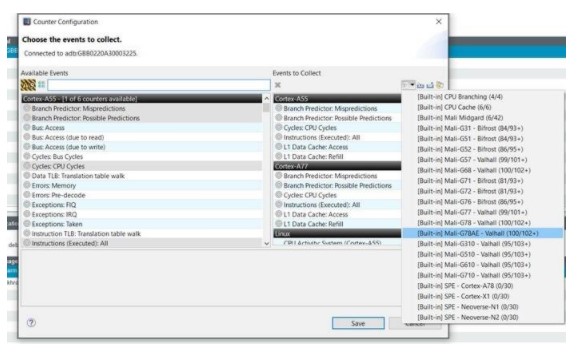
最后,我们可以按“配置计数器”来选择我们想在捕获中看到的计数器并开始捕获本身(应用程序将自动启动)。

在我们的案例中,应用程序使用 GPU ML 推理,因此我们对 GPU 计数器感兴趣。配置它们的最简单方法是选择现有模板(在本例中为 Arm Mali G78 GPU):
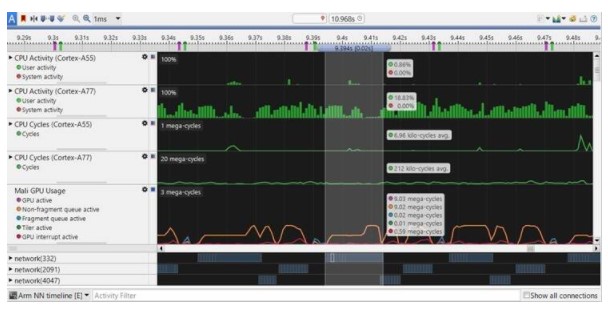
捕获完成后,我们可以使用卡尺选择一个区域并查看特定于该区域的数据。在下图中,所选区域对应于我们的 AR 应用程序中的单个帧。
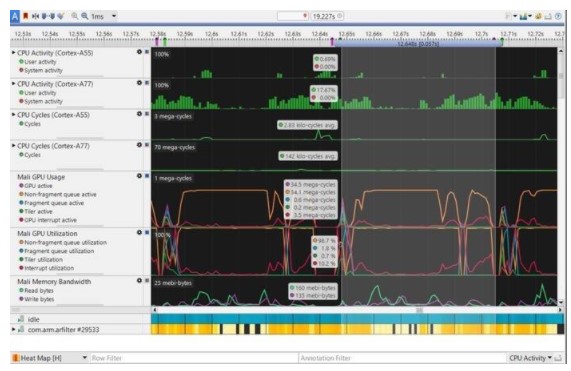
每个计数器的值(例如 CPU 活动、Mali GPU 使用情况、Mali 内存带宽)都是针对我们选择的范围计算的。这些显示在它的左侧。
在 AR Filter 应用程序中,我们对每一帧执行 3 个神经网络模型:
请注意非碎片队列活动的高时段如何对应于这 3 个网络。
大多数 ML 框架使用计算着色器或 OpenCL 内核进行 GPU 推理。在 Mali 的情况下,这种 GPU 工作负载被调度到非分片队列。在图形和 ML 组合应用程序中,这就是我们如何区分推理和图形渲染(依赖于片段和非片段队列)的方式。图形工作负载也将在顶点(非片段)阶段之后直接具有片段着色器活动。
将 Streamline 与 ArmNN 结合使用
在我们的 AR 项目中,我们使用ArmNN在 developer.arm.com 上了解有关 Arm NN 的更多信息")进行神经网络推理。它在基于 Arm 的移动设备上提供了良好的性能,但我们也可以从结合使用 ArmNN 和 Streamline 中受益。如果将 ArmNN 运行时配置为进行分析,我们可以在时间线上看到每个神经网络执行甚至单个层。
ArmNN 必须使用 -DPROFILING_BACKEND_STREAMLINE=1 标志构建以添加对此功能的支持。此外,您需要在初始化 ArmNN 运行时时在代码中启用它:
全屏

像往常一样配置和记录捕获。然后我们可以选择“Arm NN 时间线”:
在下面的截图中,您可以看到 3 个模型是如何在每一帧中一个接一个地执行的。所选范围代表第一个模型(背景分割)。请注意它如何匹配 Mali GPU 上的高非片段队列使用率。
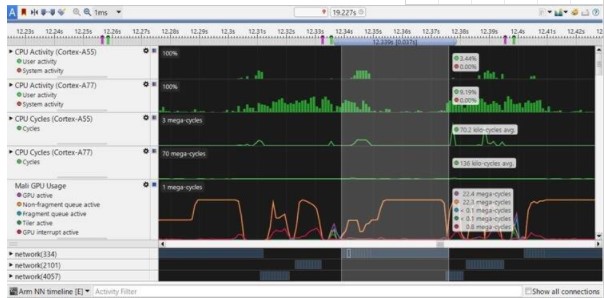
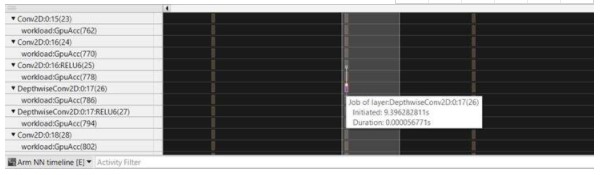
我们可以扩展每个模型并查看各个层的执行和它们之间的链接。
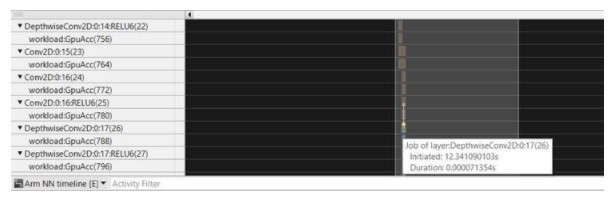
如您所见,第一个模型是我们管道中的真正瓶颈。我们优化模型并将第一个解码器层中的过滤器数量从 512 减少到 128。
整体模型执行时间从 37ms 减少到 20ms:
名为“DepthwiseConv2D:0:17”的层的持续时间从 71 微秒减少到 51 微秒:
简化注释
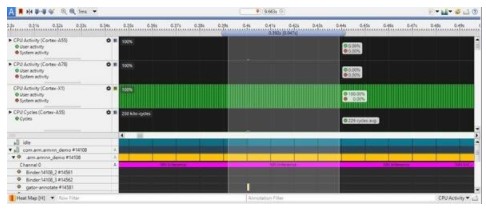
流线型的另一个有用特性是注释。您可以标记代码的特定部分并在 Streamline 捕获中查看它们。例如,我们可以标记每个神经网络执行的开始和结束:

如果我们在热图中展开主线程条目,我们将能够看到时间轴上的每个执行,并使用卡尺选择相应的范围:
概括
我们已经介绍了配置 Streamline 和获取 Android 应用程序的分析捕获的过程。
使用 Streamline 分析基于 ML 的应用程序允许您:
- 查找 ML 工作负载中的瓶颈
- 看看神经网络执行之间是否有任何可以减少的差距
- 检查 CPU 或 GPU 是否被有效利用
- 看看某个模型优化对减少推理时间或内存带宽有多大帮助。
这将帮助您找到优化应用程序并获得更好性能的方法。
原作者:帕维尔·鲁德科
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2611
2611













 淘帖
淘帖




