3 编译SVE代码
上一章从很多方面阐述了如何使用SVE编程。因为宽向量,可变长向量长度,predication和first-fault支持的推测性向量化的影响,如何将这些技术转化到编译器中, 需要我们重新思考编译策略。
3.1 宽向量和可变长向量
当编译器使用高级SIMD(NEON)这类固定长度向量时,一个方法是‘Unroll and Jam’,这种方法先将循环按向量中的元素个数展开(unroll),然后每次迭代中的相应操作合并为向量操作。这种方法显然和可伸缩向量长度不匹配,因为向量长度在编译时是未知的。解决方式是向量化工具直接映射标量操作为对应的向量操作。第二个挑战是:向量长度常量(VL)的可知性在向量化中扮演重要角色。比如,当处理归纳变量时,可能通过从内存取出向量下标为[0, 1, … VL-1]这些值来初始化这个向量,然后每次迭代递增VL长度来访问下一个向量。SVE通过引入把当前向量长度作为隐含操作数的一类指令来解决这个问题,比如, index指令可以初始化向量归纳变量,inc指令基于当前向量长度和特定的元素大小来更新归纳变量。
可变长向量长度也会影响由于寄存器压力导致的寄存器压栈和出栈操作, 或是作为函数调用规范中把向量作为函数参数的传参数操作。在现有编译器中支持它是个挑战,因为编译器通常假设在栈帧中所有的东西都在常数(固定)偏移位置,并且这些常数在编译器的很多地方使用。我们的解决方式是:引入栈区域,每个区域决定常数偏移代表什么。对现有栈区域,常数保持不变(如 byte偏移),但SVE寄存器区域可以动态分配,并在这个区域的常数偏移的存取隐含地要乘以VL。
3.2 Predicate
Predicate是参考传统“if-conversion” (If转换)方式引入的,使用计算predicate的指令,再将这些predicate作用于由条件控制的每个操作上,利用这种方式替换if-statement (if 表述)。
我们扩展了这种方式,通过插入一条产生向量分割(导致只有循环退出条件之前的那些lane才会是有效的(active))的brk指令,来处理有条件的循环退出(如 if-break)。
3.3 浮点数
浮点数对编译器向量化来说是个挑战,因为向量化一个缩减的循环(reduction loop)会改变浮点数操作的顺序,可能会导致和元素标量代码不一样的结果。程序员需要做一个选择:关闭向量化来得到一致的结果,还是可以容忍一些差异来得到更好性能。
可变长变量可能会引入更大的差异,因为不同的向量长度会带来不同的差异,因而导致的不同结果。SVE通过通过引入fadda指令来缓解这个问题,此指令在浮点数加的准确顺序对正确性很关键时,让编译可以向量化这些场景。
3.4 推测性向量化
我们能用LLVM[10]编译器扩展现有向量化方式实现以上的挑战,但使用现有方式支持推测性向量化不可行。我们使用另外的方式实现推测性向量化,这种方式现在着重于扩大循环覆盖率而不是产生最高质量的代码。
这个向量化器在很大程度上和现在LLVM向量化器类似,但是有更先进的predicate处理来支持有多退出的循环。它将循环体分割成多个区域,每个区域由不同的predicate控制。大概地说,这些区域代表了:
• 总能安全执行的那些指令
• 需要计算条件退出predicate的那些指令
• 条件退出之后的那些指令
对于后面两个区域,我们使用first-fault load和分割操作。
4 实现挑战
对定长编码指令集来说,编码空间是稀缺资源,因此 一个SVE 早期设计约束是要限制它中的编码面积,为将来A64指令扩展预留空间。为达到这个目标,在ISA各个方面使用了些不同的方式:
构建性 vs 解构性的方式:虽然编译器更希望使用指令构建性的方式(如 支持目的操作数不同于源操作数),但指令编码空间为整个数据处理操作同时提供可预测性和构建性的话,很容易超过给定的编码空间预算(3个向量,1个predicate寄存器标志就需要19个bit,还没算上其他控制部分)。SVE做的取舍是:仅为大多数的数据处理指令提供结构性的predicate形式,但是提供大多数常见opcode的构建性unpredicated形式。
更多前缀:为了满足完全的构建性Predicate形式,SVE引入了movprfx指令,它稍微让硬件可以解码并合并紧接着的指令为单个构建性操作。但这条指令也可以实现为单独向量copy操作。这对指不管有没有合并,它们得到的结果是一样的。SVE既支持predicated形式的,又支持unpredicated形式的movprfx指令。
Predicate寄存器的访问限制:为了进一步减小编码空间,如2.3章节提到的,predicated形式的数据处理指令对predicate寄存器的访问限制在P0-P7, 但predicate产生指令通常可以访问所有16个predicate寄存器。
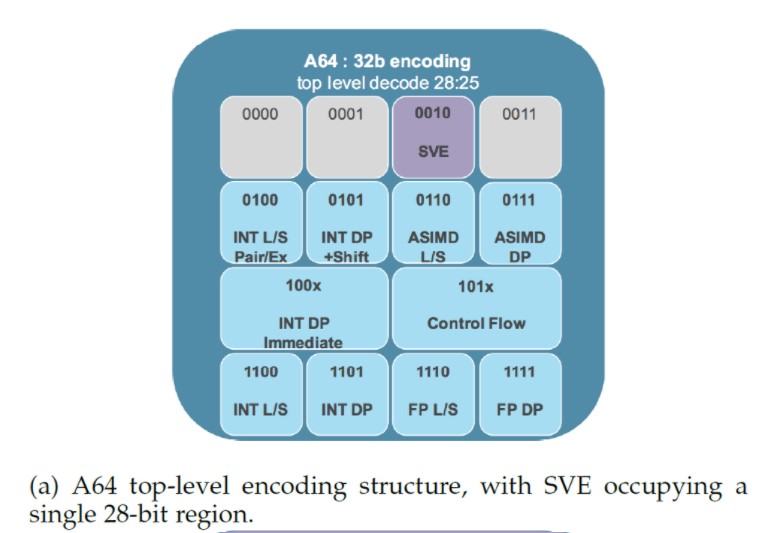
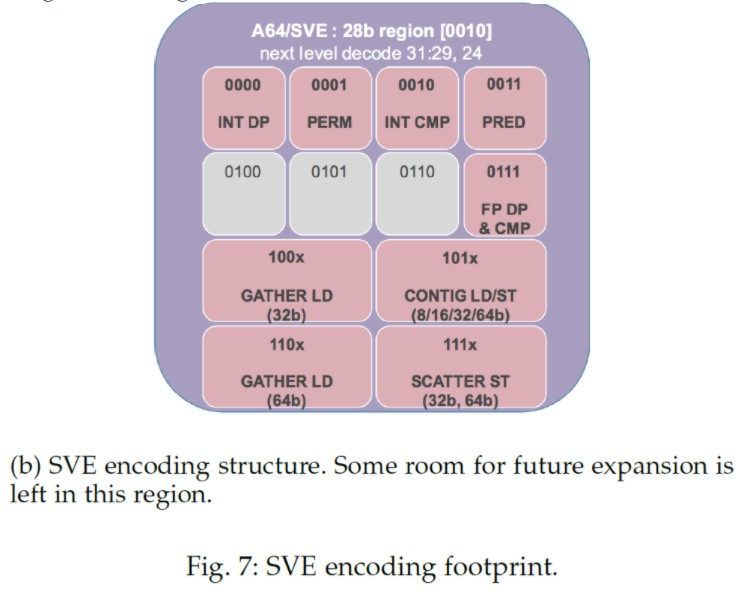
上面提到的方案让SVE使用的编码空间少于28bit(图7)。除了编码空间,另一个SVE实现的关注点是:为了支持超越高级SIMD(NEON)的额外功能带来的额外硬件代价。一个重要的决定是:新的SVE向量寄存器(register file)和现存的SIMD/浮点寄存器重叠(见图1a),因此减少面积开销,这对那些小核特别适合。
更进一步,当高级SIMD和浮点数指令写SIMD/浮点数寄存器时,它们需要零扩展对应向量寄存器,避免部分更新的情况(众所周知,这在高性能微构架中很难处理)。另外,大多数的SVE操作可以高效地映射到现有的高级SIMD datapath和功能单元,有必要的话,为predicate功能做些改动来支持更大的宽度。
虽然更宽的向量处理是发挥数据并行的关键需求,但它还必须与之匹配的内存访问能力和带宽的提升。SVE提供了很多带丰富地址访问模式的连续地址存取指令,和load-and-broad指令(它复制单个元素给整个向量元素),通常是load/store datapath的一部分,因此通常情况下不需要额外的排列单元。
聚合-分散 内存访问操作是使访问不连续地址数据的循环可以向量化的关键功能,没有它们可能向量化不会带来好处。获益于高级的向量存取单元,它们提升了并行度,而且对把它们分解为微操作(uops)的传统方式更加友好,只要它们不明显地慢于用标量实现的存取过程。
5 SVE的性能
我们预计Arm多个合作伙伴会用不同的微构架实现SVE。因此,我们评估SVE性能采用了几种代表性的微构架模型。对呈现在这里的结果,我们选择了与任何真实设计无关的典型,中等大小,乱序的单一微构架模型,但我们相信它会给出SVE公平的评估。整个模型的主要参数在表2中给出。
模型中指令执行和寄存器file访问延迟是根据RTL综合结果设定的。对跨lane操作(如 向量排序和缩减),模型施加了与VL相称的惩罚。模型使用的cache是真双端口cache,它最大的访问大小是整个cache line,512bit。跨cache line访问施加了对应的惩罚。
我们的评估采用了实验性的编译器,可以采用SVE做自动向量化。我们选择了各种知名benchmark套件[11], [12], [13], [14], [15], [16], [17],[18]中的高性能计算应用。目前,我们的编译器仅支持C和C++,因此benchmark的选择受制于此。我们采用benchmark公开可获取的原始代码,并在有些情况下稍微修改来帮助自动向量化(如 加上restrict限定词 或是 OpenMP simd pragmas)。
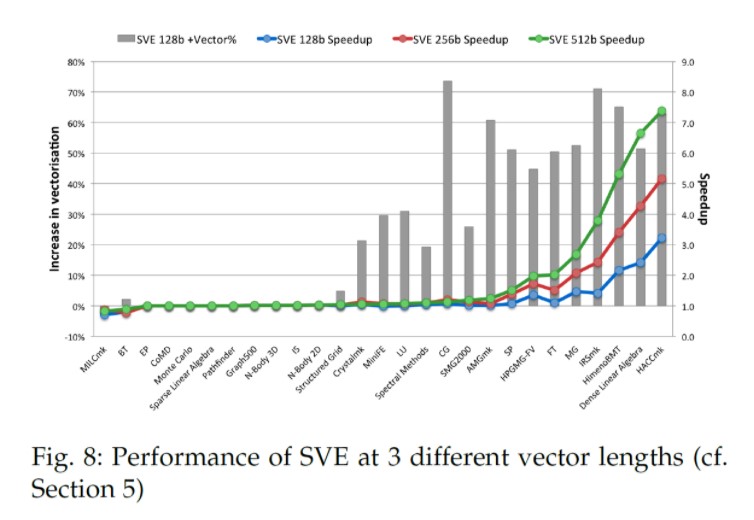
图8 呈现了我们的评估结果。我们分别用3中SVE向量长度的配置, 128bit,256bit和512bit,与高级SIMD(NEON)进行比较。全部4个仿真采用一样的处理器配置,但是向量长度不同。图中有两类结果,图表中的线代表每种SVE配置相对高级SIMD的性能提升,图表中的柱状图表示SVE相对高级SIMD带来的额外向量化。这是使用动态执行128bit向量长度的向量指令的百分比来测量的。
显而易见,结果显示SVE相对高级SIMD有更高的向量化程度。 这是因为我们引入构架的所有功能让编译器可以向量化复杂的控制流程,非连续内存访问等。因为这个原因,即使当向量大小与高级SIMD相同时,SVE可以得到3倍的性能提升。比如,特别是HACCmk场景,主循环中的两个条件赋值阻碍了高级SIMD的向量化,但是这个代码还是可以采用SVE向量化。
这图也演示了可变长度编程代码的好处。我们可以清楚地看到性能怎样随向量长度提升,只需简单在更大向量长度实现上运行同样的可执行文件。这也是SVE带来的非常好处之一。
有3种明显的benchmark类型:
在图右边,我们可以看到一组benchmark,显示了利用SVE有更高的向量化利用率,并且性能也随向量长度提升(可达7倍)。有些benchmark不像其他的那么倍增,这主要是因为使用了聚合-分散操作。虽然这些操作使能了向量化,我们认为CPU实现传统地分解了这些操作,因此不和向量长度一样倍增。其他的一些场景,如HimenoBMT, 比较差的性能提升是因为编译器比较差的指令重排(instruction scheduling)。
在图的左边我们可以看到一组benchmark,显示了具有采用高级SIMD和SVE的微小,甚至有些情况是0 的向量化利用率。我们的研究显示这是因为代码的结构或是编译器的限制,而不是构架的缺陷。比如,我们知道我们可以通过重构C0MD的代码得到明显的向量化和执行时间提升。同时,必须提醒现在使用的实验性的编译器没有一些基本数学库函数(如 pow(),log())的向量化实现的版本,在有些情况下,它阻碍了循环的向量化,如在EP中。最后,有些情况,算法本身不能被向量化,如Graph500,此程序主要是顺着指针遍历图表结构。这种情况下,我们不期望SVE有帮助。
第三组benchmark包含了一些相对高级SIMD,编译器明显利用SVE向量化了更多代码,但是没有太多的性能提升。所有的场景都是因为编译器的代码生成问题,我们正在处理。比如在SMG2000中,过度使用聚合-取 和错误的指令选择 导致了SVE带来非常小的性能好处。高级SIMD编译完全不能向量化这些代码,这不值一提。
MILCmk是另一个有趣的场景,一序列的糟糕编译器决定导致相对高级SIMD来说SVE的性能更差。编译器决定向量化一个嵌套循环的最外层循环,导致了不必要的开销(高级SIMD编译器向量化内层循环),并且也没识别一些明显可以被向量化的循环。
我们预计随着时间推进,编译器和库的改进,这些问题中很多都会被解决。
6 结论
SVE打开了arm构架的新篇章,让arm处理器核的向量处理更上一个台阶。现在还是SVE工具和软件的早期,SVE编译器和其他SVE软件生态的成熟还需要一些时间。HPC是现在的重点和编译器工作的催化剂,在这个领域推动开发工作,如Linux发行版,为SVE优化的库,Arm和第三方的工具和软件。
原作者:修志龙_ZenonXiu
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2718
2718


 淘帖
淘帖




