Superscalar与 OOO(Out-of-order) 的引入极大促进了现代处理器微架构的发展。已知的高性能处理器,如Nehalem,Sandy Bridge,Opteron,Power甚至是ARM Cortex系列处理器都使用了这种架构。这类方法在有效提高了ILP(instruction level parallelism)的同时,加大了整个Cache Memory层次结构的实现难度。
在此我们讨论存储器读写指令在Superscalar与OOO环境下的执行过程。存储器读写指令的执行过程似乎非常简单。即使是只写过几行汇编代码的程序员亦可对此娓娓道来。许多人认为存储器读不过是将数据从主存储器中读入寄存器,存储器写是将寄存器中的数据写入到主存储器中。
这个执行过程很难用一句话回答,即便是将使用的处理器模型进行大规模的约束。在一个支持Superscalar和OOO的处理器中,一条指令的执行被分解为若干步骤。指令首先进入Pipeline的Front-End,包括Fetch与Decode,之后经过Dispatch和Scheduler后进入执行单元,最后Commit执行结果。
假设在一个微架构中,所有指令使用In-Order方式通过Front-End,并采用Out-of-Order方式进行Issue,之后使用Out-of-Order Execution和Completion方式,在最后进行Commitment时使用In-order的方式。其中指令Commitment的定义是在其执行完毕,并将最后结果更新至 ROB(re-order buffer) 和 LSQ(Load-Store Queue) 的过程。
现代处理器在Commit最后的执行结果时大多都采用In-order方式,这也保证了指令在经过Out-of-Oder的流水线后,程序员看到的最终结果与程序应有的顺序一致。多数程序员被这一假象迷惑,认为CPU的乱序执行仅与硬件流水线相关,并不会影响软件程序。
事实并非如此。微架构为了实现乱序执行,有些指令,比如存储器读指令,可能会提前执行,而后因为种种原因,如分支预测失败,可能会被迫重新执行。虽然乱序流水线可以保证最后的结果与程序期待的结果一致,但是无法完全抹去这条本不该执行的指令在存储器子系统中留下的执行痕迹。
为了进一步简化模型,我们仅讨论在经过这些约束后的CPU中,存储器读写指令的执行过程。与其他指令相比,这两条指令的执行过程更加显得步履蹒跚。下文以Nehalem微架构为参照说明存储器指令的执行过程。Nehalem微架构Pipeline的组成结构如图1‑3所示。
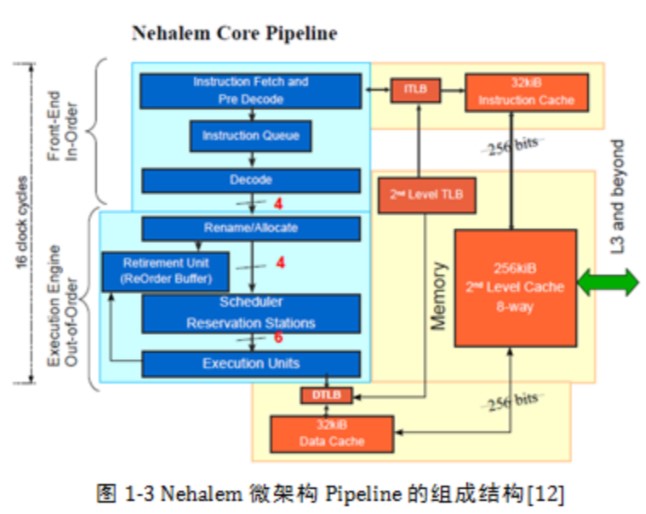
存储器读写指令在经过Front-End之后,将首先通过Rename/Allocate部件,使用Renaming技术可以解决与存储器读写最直接相关的WAW,WAR相关,之后等待源Operand准备就绪,并将其Dispatch给Scheduler。这些指令需要从RS(Reservation Stations)获得可用的Entry,对于存储器读写指令还需要从LSQ中预留空间,最后插上ROB Tag的翅膀,经In-Order或者Out-of-Order的发射(Issue)过程,自由飞翔。
这些飞翔的指令无序,而且 指令流水线会让最笨的鸟尽可能的提前飞翔 。存储器读写指令就是其中最笨的几只鸟。这些飞翔着的存储器读写指令将飞向第一个目的地LSQ,还有一些执行信息会同步到ROB和RS的对应Entry中。
这些飞翔的指令有快有慢,有应该飞的也有不应该飞的。速度不同的指令必须在到达第一个终点LSQ时, 按序等待提交 。不应该飞的指令必须在最后的Commitment阶段之前被发现,然后被抛弃,重新飞翔。这也造成了在一条指令流水线中存在多个Outstanding的读和写指令,可并行的最大读写指令由ROB,LSQ和RS中的Entry数目决定。在很多现代处理器中,LSQ的Entry数目多小于ROB和RS中的Entry数目,因此在一个Pipeline中可以并发的读写指令首先由LSQ的深度决定。
无序飞翔存储器读写指令在执行过程中,需要尽量无视对方的存在,最大可能的实现飞翔。因此也引入了读写指令的Speculation机制。由于Out-of-Order Issue的原因,后续的指令可能先于之前的指令执行,由于Out-of-Order Execution和Out-of-Completion的原因,率先发射的指令也不一定最先抵达目的地。
这些机制制造了多种乱序的可能。虽然指令的最终结果仍然是In-Order Commitment,但是这一机制 并不能保证存储器指令的执行轨迹是in-order的。 存储器指令的执行与其执行轨迹的异步引出了一个异常沉重的话题Memory Consistency。这个话题将有专门的篇章讨论。
原作者:sailing
|  /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2391
2391
 淘帖
淘帖




