随着 Arm 硬件在Amazon 和 Microsoft 等主要云提供商以及新的客户端设备中的兴起,更优化的应用程序正在寻求支持 Arm NEON 和 SVE。这篇文章展示了我们在从 x86 移植到 Arm 时使用的一些优化技术。
迁移到 Arm 时,需要重新编译应用程序代码。虽然这通常很简单,但一个挑战可能是移植手写的 x86 内部代码以充分利用 Arm 架构。有一些SSE 到 Neon 移植博客可以使运行某些东西变得容易,但它们专注于可移植性,有时可以进一步优化以获得最佳性能。
在 Google,我们发现如果我们使用可移植库或直接用等效的 Arm 指令序列替换 x86 内部函数,某些工作负载的速度会慢 2 倍。我们想分享我们的经验,以突出一些未被充分认识的 Arm 优化,并展示它们如何使广泛使用的库受益,如哈希表、ZSTD、、、、、变量strlen整数等。memchr``memcmp
将 Arm NEON 与 SSE 指令集进行比较时,大多数指令都存在于两者中。例如,16 字节内存加载(<span>_mm_loadu_si128</span>和vld1q_u8(https://developer.arm.com/architectures/instruction-sets/intrinsics/vld1q_u8))、向量比较(<span>_mm_cmpgt_epi8</span>和[vcgtq_s8])或字节洗牌(<span>_mm_shuffle_epi8</span>和)。但是,开发人员经常遇到问题,因为 Arm NEON 指令在转换到标量代码和返回时成本很高。对于移动字节掩码 ( ) 指令尤其如此。vqtbl1q_s8[](https://developer.arm.com/architectures/instruction-sets/intrinsics/vqtbl1q_s8)PMOVMSKB`
移动字节掩码 ( PMOVMSKB) 是 x86 SSE2 指令,它从 128 位寄存器中每个 8 位通道的最高有效位创建掩码,并将结果写入通用寄存器。它通常与向量比较指令一起使用,例如PCMPEQB,快速扫描缓冲区中的某个字节值,一次 16 个字符。
例如,假设我们要索引字符串“Call me Ishmael”中出现的空格字符 (0x20)。使用 SSE2 指令,我们可以执行以下操作:

然后很容易知道向量是否有一些匹配字符(只需将此掩码与零进行比较)或找到第一个匹配字符,您需要做的就是通过bsf(位扫描转发)或tzcnt指令计算尾随零的数量。这种方法也与现代库(如 Google SwissMap 和 ZSTD 压缩)中的位迭代一起使用:
ZSTD_VecMask ZSTD_row_getSSEMask(int nbChunks, const BYTE* const src,
const BYTE tag, const U32 head) {
// …
const __m128i chunk = _mm_loadu_si128((const __m128i*)(src + 16*i));
const __m128i equalMask = _mm_cmpeq_epi8(chunk, comparisonMask);
matches[i] = _mm_movemask_epi8(equalMask);
// …
}
MEM_STATIC U32 ZSTD_VecMask_next(ZSTD_VecMask val) {
return ZSTD_countTrailingZeros64(val);
}
for (; (matches > 0) && (nbAttempts > 0); --nbAttempts, matches &= (matches - 1)) {
U32 const matchPos = (head + ZSTD_VecMask_next(matches)) & rowMask;
// …
}
matches &= (matches - 1)将 1 的最低位设置为零,有时称为Kernighan 算法。
此类技术用于字符串比较、字节搜索等。例如,在 中,算法应该在第一个不匹配字节中,在第一个匹配字符中strlen找到第一个零字节。Arm NEON 没有阻止它从相同方法中受益的等价物。从 x86 直接转换将需要重新设计程序或模拟 x86 内在函数,这将是次优的。让我们看一些使用SSE2NEON和SIMDe的示例:memcmp``memchr``PMOVMSKB
SSE2NEON :

辛德:
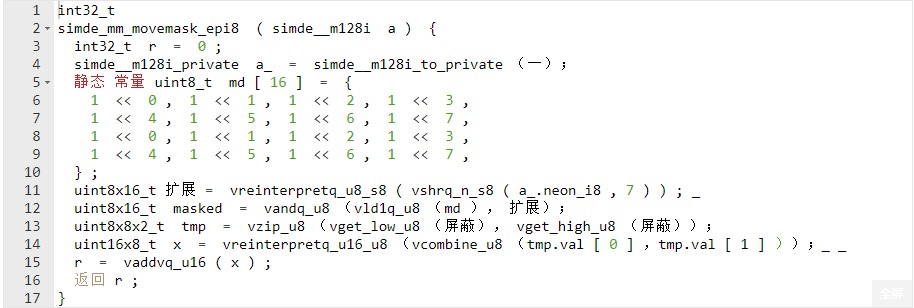
我们不打算深入了解上述任何实现的细节。它们是移植时很好的默认选项。但是,它们的性能并不是最好的,因为它们都需要至少 4 条指令,每条指令至少有 2 个周期延迟,而movemask在大多数现代 x86 平台上只需要一个周期。
glibc包括shrn在内 的大多数库都没有充分考虑的一条指令具有<span><span> </span>reg.8b reg.8h, #imm</span>``.以下语义:让我们将 128 位向量视为八个 16 位整数,将它们右移<span>#imm</span>并“缩小”(换句话说,截断)到 8 位。最后,我们将从这样的截断中得到一个 64 位整数。当我们用它移位时,<span>imm = 4</span>会产生一个位图,其中每个输出字节包含高输入字节的低四位和低输入字节的高四位。
该视频显示shrn正在运行。
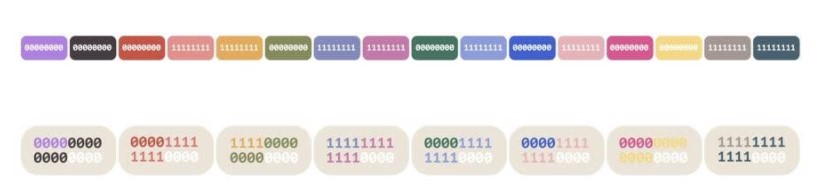
这是一个通过查找字节标记来获取用于比较 128 位块的掩码的示例:

换句话说,它从每个字节中产生 4 位,在 16 字节向量的高 4 位和低 4 位之间交替。假设比较运算符给出 16 字节的结果<span>0x00</span>or <span>0xff</span>,结果接近于 a PMOVMSKB,唯一的区别是每个匹配位重复 4 次并且是 64 位整数。但是,现在您可以执行几乎所有与使用PMOVMSKB. 将 两种情况下的结果视为or的结果:PMOVMSKB``shrn

我们使用 和 的组合,<span>rbit</span>因为<span>clz<span> </span></span>arm 指令集没有<span>ctz</span>(Count Trailing Zeros) 指令。对于迭代使用第一个版本,如果匹配集不大,因为第二个需要预加载到单独的寄存器中。例如,对于探测开放地址的哈希表,我们建议使用第一个版本,但对于匹配带有小字母的字符串,我们建议使用第二个版本。如有疑问,请使用第一个或衡量两者的性能。0xf000000000000000ull
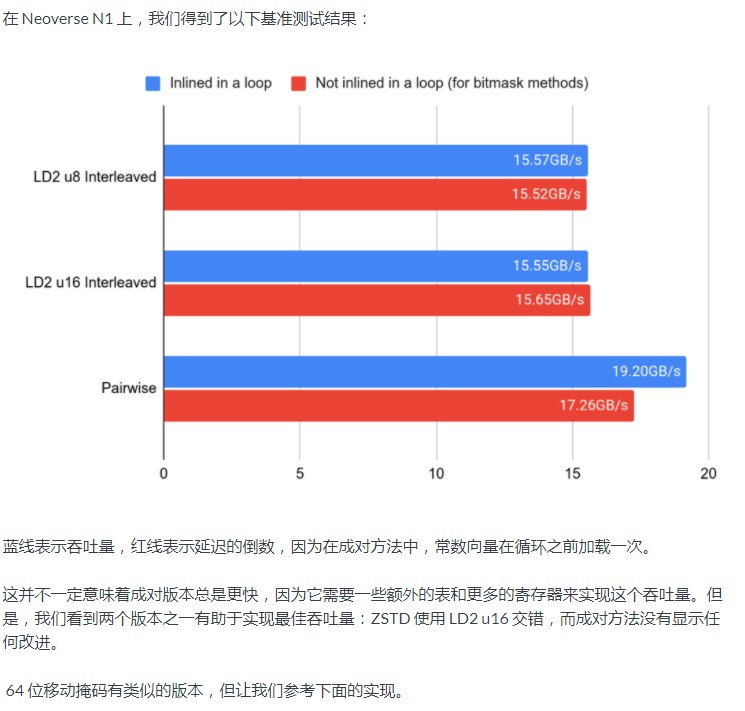
案例研究:ZSTD
1.5.0 版的 ZSTD为 5-12 级引入了基于 SIMD 的匹配。我们将 5-9 级优化了 3.5-4.5%,将 10 级优化了 1%。
前
if (rowEntries == 16) {
const uint8x16_t chunk = vld1q_u8(src);
const uint16x8_t equalMask = vreinterpretq_u16_u8(vceqq_u8(chunk, vdupq_n_u8(tag)));
const uint16x8_t t0 = vshlq_n_u16(equalMask, 7);
const uint32x4_t t1 = vreinterpretq_u32_u16(vsriq_n_u16(t0, t0, 14));
const uint64x2_t t2 = vreinterpretq_u64_u32(vshrq_n_u32(t1, 14));
const uint8x16_t t3 = vreinterpretq_u8_u64(vsraq_n_u64(t2, t2, 28));
const U16 hi = (U16)vgetq_lane_u8(t3, 8);
const U16 lo = (U16)vgetq_lane_u8(t3, 0);
return ZSTD_rotateRight_U16((hi << 8) | lo, head);
}
// …
U32 const head = *tagRow & rowMask;
ZSTD_VecMask matches = ZSTD_row_getMatchMask(tagRow, (BYTE)tag, head, rowEntries);
for (; (matches > 0) && (nbAttempts > 0); --nbAttempts, matches &= (matches - 1)) {
U32 const matchPos = (head + ZSTD_VecMask_next(matches)) & rowMask;
// …
}
后
U32 ZSTD_row_matchMaskGroupWidth(const U32 rowEntries) {
#if defined(ZSTD_ARCH_ARM_NEON)
if (rowEntries == 16) { return 4; }
if (rowEntries == 32) { return 2; }
if (rowEntries == 64) { return 1; }
#endif
return 1;
}
// …
if (rowEntries == 16) {
const uint8x16_t chunk = vld1q_u8(src);
const uint16x8_t equalMask = vreinterpretq_u16_u8(vceqq_u8(chunk, vdupq_n_u8(tag)));
const uint8x8_t res = vshrn_n_u16(equalMask, 4);
const U64 matches = vget_lane_u64(vreinterpret_u64_u8(res), 0);
return ZSTD_rotateRight_U64(matches, headGrouped) & 0x8888888888888888ull;
}
// …
const U32 groupWidth = ZSTD_row_matchMaskGroupWidth(rowEntries);
U32 const headGrouped = (*tagRow & rowMask) * groupWidth;
ZSTD_VecMask matches = ZSTD_row_getMatchMask(tagRow, (BYTE)tag, headGrouped, rowEntries);
for (; (matches > 0) && (nbAttempts > 0); --nbAttempts, matches &= (matches - 1)) {
U32 const matchPos = ((headGrouped + ZSTD_VecMask_next(matches)) / groupWidth) & rowMask;
// …
}
案例研究:memchr 和 strlen
C 标准库中的内存和字符串 函数是处理字符串和字节搜索的基本函数。该 <span>memchr</span>函数搜索一个特定字节,该 <span>strlen</span>`` 函数搜索第一个零。在我们工作之前,glibc(C 标准库的最流行的实现)中的实现试图借助另一种方法获得类似的 64 位掩码。
对于每个 16 字节块,计算一个 64 位半字节掩码值,每个字节有 4 位。对于偶数字节,如果相关字节匹配,则设置位 0-3,但位 4-7 必须为零。同样对于奇数字节,相邻字节可以通过<span>addp</span>成对添加字节(第 1 和第 2、第 3 和第 4 等)的指令合并,如下图所示:
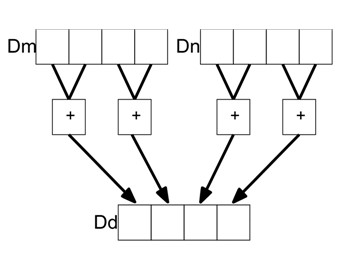
获取 64 位掩码,其中 16 字节向量的每个匹配字节对应于最终值中的 4 位:

shrn vend.8b, vhas_chr.8h, 4 /* 128->64 */
并在从 SPEC CPU 2017 基准测试中提取的分布上strlen获得了 10-15% 的改进。作为参考,请查看Arm Optimized Routines]和glibc中的补丁。
我们要注意的是,主循环仍然通过指令从四个 32 位整数中查找最大值memchr``<span>umaxp</span>:比较时,它检查最大字节不为零。如果不是,它使用shrn来获取掩码。实验表明,对于字符串(>128 个字符)来说,这比在 Neoverse N1 等内核上更快,它使用 2 个管道 V0/V1,而<span>shrn</span>只使用一个管道 V1,但两者具有相同的延迟。这种方法总体上显示了更好的结果,并且适用于更多的工作负载。因此,如果您在循环中检查是否存在,请考虑使用<span>umaxp</span>后跟指令的指令<span>shrn</span>:它可能有一个阈值,比仅使用更快<span>shrn</span>。
案例研究:Vectorscan
Vectorscan 是著名的正则表达式引擎Hyperscan的便携式分支,它针对 x86 平台进行了高度优化,内部函数遍布各处。创建这种分叉的部分原因是为 Arm 提供更好的性能。我们应用了相同的优化,并通过优化模式匹配在实际工作负载上获得了一些好处。
您可以在pull request中查看代码,或查看Arm DevSummit 2021 的此视频了解更多详情。
案例研究:谷歌瑞士地图
在 Google,我们使用 abseil 哈希图的实现,我们将其称为“瑞士地图”。在我们的设计文档中,我们将哈希的最后 7 位存储在单独的元数据表中,并查找向量中的最后 7 位哈希以探测位置:
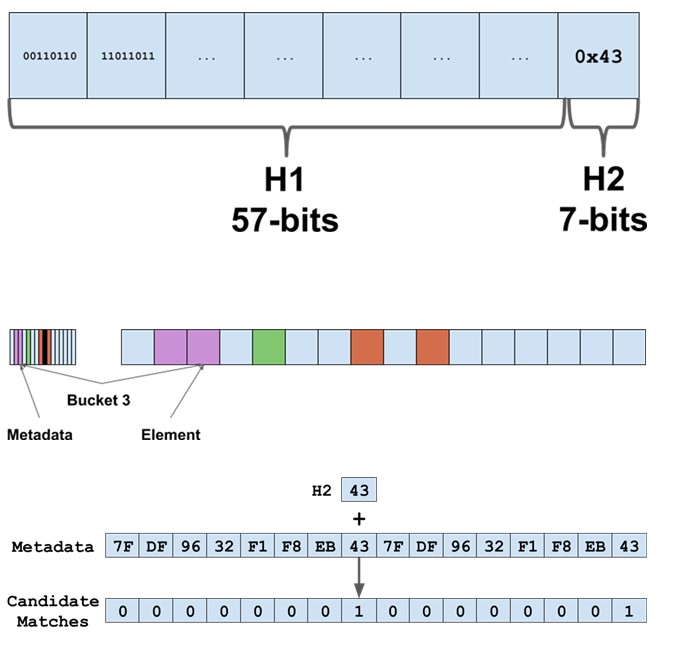
对于 x86,我们使用 movemasks 来实现:

对于 Arm NEON,我们使用 64 位 NEON,它为我们提供了 0x00 或 0xff 的 8 字节掩码,然后我们使用类似的想法进行迭代,但使用不同的常量,每个字节中只标记一位。使用指令等其他选项shrn并不是最佳选择。

最后,我们将哈希表的所有操作优化了 3-8%。提交和确切的细节可以在这里找到。
引人入胜的指令:cls
一条很少使用但可能有用的指令是cls——计算前导符号位。它计算在符号位之后开始的连续位等于它的数量。例如,对于 64 位整数,我们有:
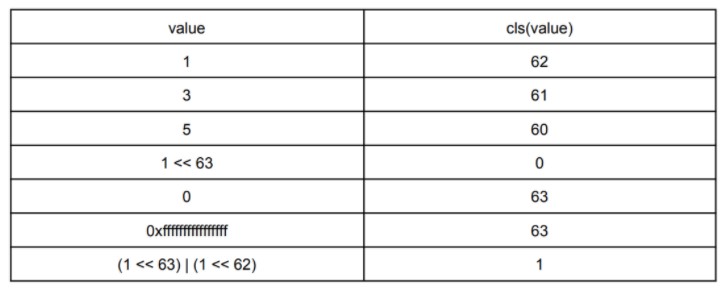
我们发现在您知道第一场比赛发生的情况下很有用:

这对于散列表迭代跳过空或删除的元素很有用。尽管我们最终使用了另一个版本,但<span>cls</span>发现技巧还是很有用的。
发现指令的另一个有用应用<span>cls</span>是了解变量整数的最终位长度,其中每个字节的第一位表示后续字节中是否存在值的延续。要找到长度,可以将每个字节从 1 到 7 的所有位标记为 1,然后执行以下操作<span>__clsll(__rbitll(value))</span>:如果前导位为 0,则结果为零,如果非零,则为length * 8 - 1 。

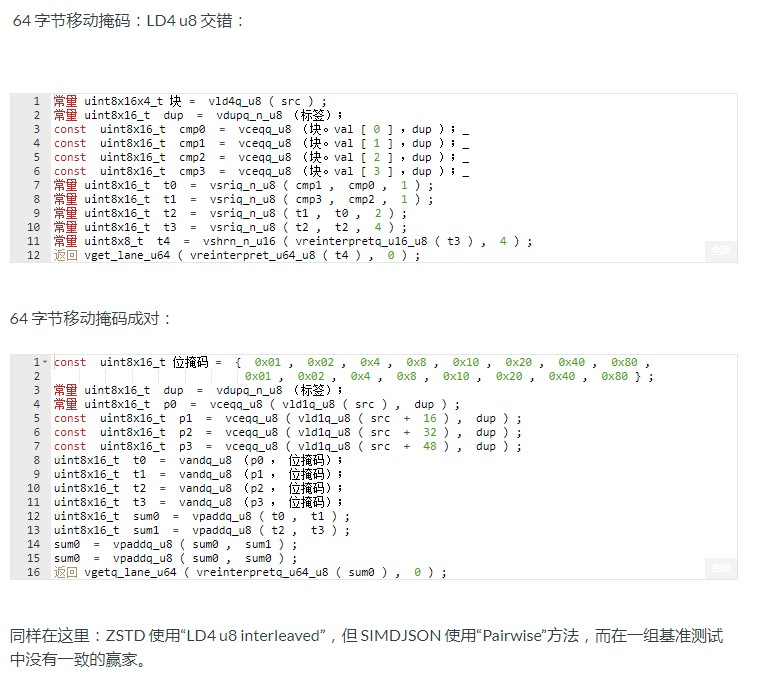
32 位和 64 位移动掩码
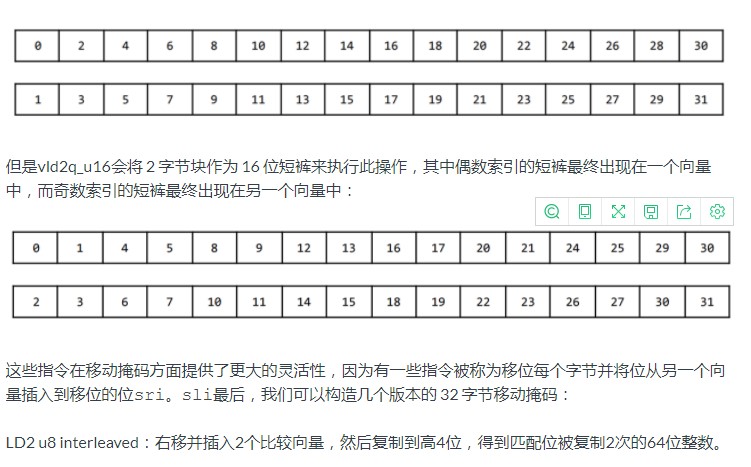
Arm NEON 主要支持使用 64 位或 128 位向量。有一些例外 - 交错加载。指令ld2、ld3和ld4` 以交错方式加载 32、48 和 64 个字节。
例如,intrinsic将按以下方式将 32 个字节(从 0 到 31 枚举)加载到 2 个向量中,以便偶数索引字节最终在一个向量中,奇数索引字节在另一个向量中:vld2q_u8

结论
Arm NEON 在许多方面与 x86 SSE 不同,本文阐明了如何将流行的 x86 矢量位掩码优化转换为 Arm,同时保持高性能。最后,它们为各个主要图书馆节省了大量资金。
原作者:Danila Kutenin
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 1886
1886

















 淘帖
淘帖





