一、前言
随着数字经济的发展,作为数字基础设施根技术的操作系统成为数字变革的关键力量,OpenAtom OpenHarmony(以下简称“OpenHarmony”) 以泛智能终端数字为底座支撑着千行百业的产业生态。
构建开源生态,需要让开发者先用起来,本文希望通过分享 OpenHarmony 的 LiteOS-M 内核对象队列的算法详解,让大家对这一算法有更加清晰的认识。
OpenHarmony 当前分为以下几种系统类型:轻量系统
、小型系统、标准系统。针对不同量级的系统,分别使用了不同形态的内核。在轻量系统上,可以选择 LiteOS-M;在小型系统和标准系统上,可以选用
LiteOS-A;在标准系统上,可以选用 Linux。
在轻小型系统中,OpenHarmony 所使用的内核为 LiteOS,在标准系统中使用 Linux。LiteOS-M 在面向 loT
领域构建了一款轻量级物联网操作系统内核,嵌入式从业者如果能更好地掌握内核相关的知识,就能在未来做研发或者定制产品的时候独当一面。
二、关键数据结构
首先关注队列的关键数据结构 LosQueueCB,有了这个数据,才能理解队列是如何工作的:
typedef struct {
UINT8 *queue;
UINT16 queueState;
UINT16 queueLen;
UINT16 queueSize;
UINT16 queueID;
UINT16 queueHead;
UINT16 queueTail;
UINT16 readWriteableCnt[OS_READWRITE_LEN];
LOS_DL_LIST readWriteList[OS_READWRITE_LEN];
LOS_DL_LIST memList;
}LosQueueCB;
*queue: 指向消息节点内存区域,创建队列时按照消息节点个数乘每个节点大小从动态内存池中申请一片空间。
queueState: 队列状态,表明队列控制块是否被使用,有 OS_QUEUE_INUSED和OS_QUEUE_UNUSED 两种状态。
queueLen: 消息节点个数,表示该消息队列最大可存储多少个消息。
queueSize: 每个消息节点大小,表示队列每个消息可存储信息的大小。
queueID: 消息 ID,通过它来操作队列。
消息节点按照循环队列的方式访问,队列中的每个节点以数组下标表示,下面的成员与消息节点循环队列有关:
queueHead: 循环队列的头部。
queueTail: 循环队列的尾部。
readWriteableCnt[OS_QUEUE_WRITE]: 消息节点循环队列中可写的消息个数,为 0 表示循环队列为满,等于 queueLen 表示循环队列为空。
readWriteableCnt[OS_QUEUE_READ]: 消息节点循环队列中可读的消息个数,为 0 表示循环队列为空,等于 queueLen 表示消息队列为满。
readWriteList[OS_QUEUE_WRITE]: 写消息阻塞链表,链接因消息队列满而无法写入时需要挂起的 TASK。
readWriteList[OS_QUEUE_READ]: 读消息阻塞链表,链接因消息队列空而无法读取时需要挂起的 TASK。
memList: 申请内存块阻塞链表,链接因申请某一静态内存池中的内存块失败而需要挂起的 TASK。
注意:在老的版本中,readWriteableCnt 和 readWriteList 拆分为 4
个变量,新版本用宏定义合并,OS_QUEUE_READ 标识是读操作,OS_QUEUE_WRITE 标识为写操作。从中可看到代码的微妙之处,0
的含义和 queueLen 对于读写是统一的,内核开发者不断使用抽象手段来优化内核。
三、关键算法
队列的算法和 FIFO、FILO 有关,今天先给大家介绍 FIFO 算法。
百度定义:FIFO(First Input First Output),即先进先出队列。例如,在超市购物之后我们会到收银台排队结账,看着前面的客户一个个离开,这就是一种先进先出机制,先排队的客户先行结账离开。
那么 OpenHarmony 的队列如何实现这个算法?
3.1 FIFO算法之入队列
第一步:队列初始化
由于 LOS_QueueCreate 函数太长,便只截取关键函数 LOS_QueueCreate。
LITE_OS_SEC_TEXT_INIT UINT32 LOS_QueueCreate(CHAR *queueName,
UINT16 len,
UINT32 *queueID,
UINT32 flags,
UINT16 maxMsgSize)
{
LosQueueCB *queueCB = NULL;
UINT32 intSave;
LOS_DL_LIST *unusedQueue = NULL;
UINT8 *queue = NULL;
UINT16 msgSize;
...
queue = (UINT8 *)LOS_MemAlloc(m_aucSysMem0, len * msgSize);
...
queueCB->queueLen = len;
queueCB->queueSize = msgSize;
queueCB->queue = queue;
queueCB->queueState = OS_QUEUE_INUSED;
queueCB->readWriteableCnt[OS_QUEUE_READ] = 0;
queueCB->readWriteableCnt[OS_QUEUE_WRITE] = len;
queueCB->queueHead = 0;
queueCB->queueTail = 0;
LOS_ListInit(&queueCB->readWriteList[OS_QUEUE_READ]);
LOS_ListInit(&queueCB->readWriteList[OS_QUEUE_WRITE]);
LOS_ListInit(&queueCB->memList);
LOS_IntRestore(intSave);
*queueID = queueCB->queueID;
OsHookCall(LOS_HOOK_TYPE_QUEUE_CREATE, queueCB);
return LOS_OK;
}
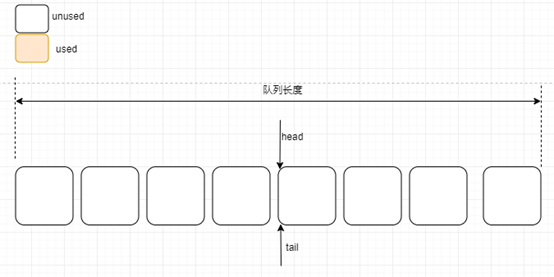
数据结构是支撑算法的灵魂,内核对象的队列控制结构 LosQueueCB 通过 queue 指针来指向具体队列的内容,队列分配了 queueLen 个消息,每个消息的大小为 queueSize,与此同时头指针和尾指针不约而同初始化为 0。
第二步:第一个消息入队列
生产者通过队列来传递信息,这个生产者可以是形形色色的各个任务,产生一个队列后,任务就迫不及待的需要放置消息,选择 FIFO 还是 FILO?这一次我们选择了 FIFO。
下图是 FIFO 插入第一个数据后的内存形态。
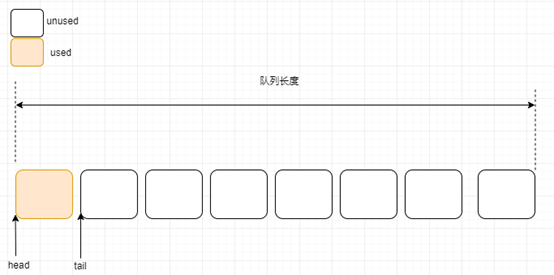
OpenHarmony 作为一个开源系统,在下面的代码中很好地体现了这个操作:
static INLINE VOID OsQueueBufferOperate(LosQueueCB *queueCB, UINT32 operateType,
VOID *bufferAddr, UINT32 *bufferSize)
{
UINT8 *queueNode = NULL;
UINT32 msgDataSize;
UINT16 queuePosition;
errno_t rc;
switch (OS_QUEUE_OPERATE_GET(operateType)) {
case OS_QUEUE_READ_HEAD:
queuePosition = queueCB->queueHead;
((queueCB->queueHead + 1) == queueCB->queueLen) ? (queueCB->queueHead = 0) : (queueCB->queueHead++);
break;
case OS_QUEUE_WRITE_HEAD:
(queueCB->queueHead == 0) ? (queueCB->queueHead = (queueCB->queueLen - 1)) : (--queueCB->queueHead);
queuePosition = queueCB->queueHead;
break;
case OS_QUEUE_WRITE_TAIL:
queuePosition = queueCB->queueTail;
((queueCB->queueTail + 1) == queueCB->queueLen) ? (queueCB->queueTail = 0) : (queueCB->queueTail++);
break;
...
}
OsQueueBufferOperate 是队列内存的核心操作函数,FIFO
算法本质是往队列的尾处添加数据,代码抽象为 OS_QUEUE_WRITE_TAIL 操作,请注意队列是个循环队列,插入数据后移动 tail
这个“尾巴”指针要尤为小心,在最后一个物理空间用完成后需要移到队列头部,这就是环形队列的“循环大法”。
如何判断最后一个物理空间已经用完?(queueCB->queueTail + 1) ==
queueCB->queueLen)C 语言语句很好地解释了这个疑问。queueLen
是队列物理空间的边界值,如果下一个消息已经指到这个边界值,那么内核必须让它回到原位,即 queueCB->queueTail =
0,不然可能会出现“内存越界”的问题,可能会造成机毁物亡。因为 OpenHarmony
应用在各个领域,如果是自动化驾驶领域那么造成的后果非常严重。
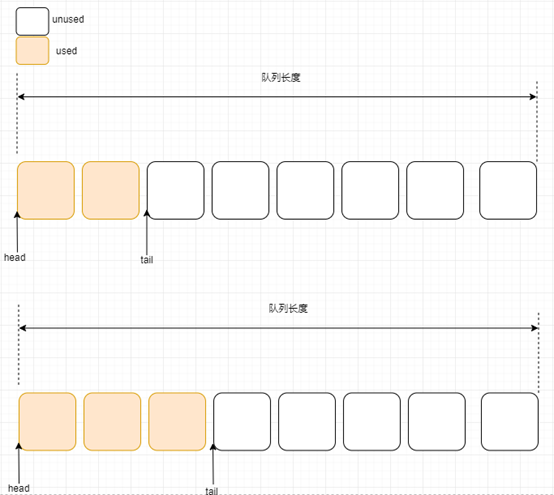
第三步:继续生产数据
接下来,再来一些图片示例:
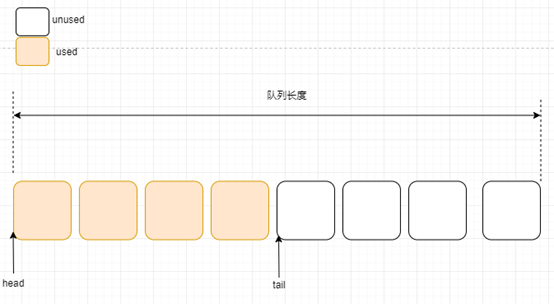
第四步:生产数据结束
生产者生产了四个消息后就结束了。
3.2 FIFO算法之出队列
第一步:队列第一个消息
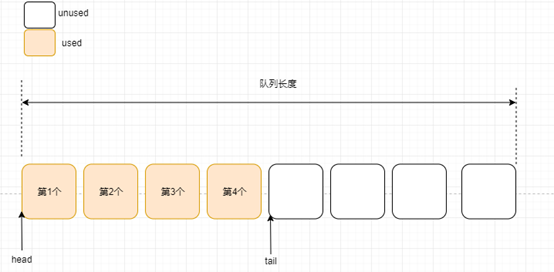
如上图所示我们回顾下入队列的步骤,知道了每个消息的入队顺序,于是第一个消息被消费后:
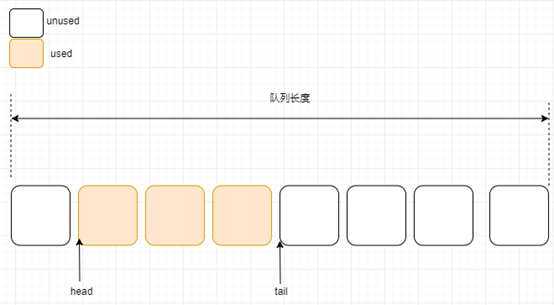
在生产消息过程中我们已经提到 OsQueueBufferOperate 这个函数,我们回顾关键代码:
switch (OS_QUEUE_OPERATE_GET(operateType)) {
case OS_QUEUE_READ_HEAD:
queuePosition = queueCB->queueHead;
((queueCB->queueHead + 1) == queueCB->queueLen) ? (queueCB->queueHead = 0) : (queueCB->queueHead++);
break;
queueHead 就是我们的头指针,它的移动也面临着生产过程相同的问题,在最后一个物理空间用完成后需要移到队列的头部。OS_QUEUE_READ_HEAD 是出队列的关键处理,解决了 queueHead 头指针如何移动的问题。
第二步:继续消费
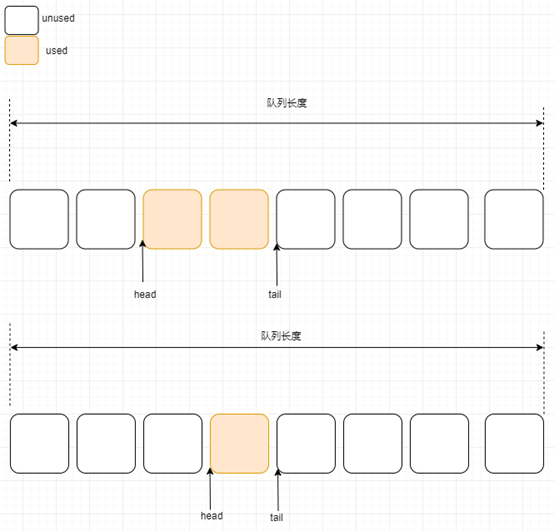
第三步:消费完毕
最后一个消息也消失了,head指针和tail指针均移动到下图的位置,此时队列为空。
四、总结
本文主要介绍了 OpenHarmony 内核对象队列的算法之 FIFO,在后续的篇章中将给大家介绍内核对象队列另外一种算法——FILO。希望通过这篇文章,可以让开发者们对于目前 OpenHarmony LiteOS-M 内核队列算法有了更全面的概念。
当然队列算法也不远远如此,linux 标准内核有加权队列等更复杂的算法。但是“他山之石,可以攻玉”,技术万变不离其宗,掌握了 FIFO 的细节有助于工程师设计其它队列算法,也能够把更多更新的技术带入到 OpenHarmony 社区,繁荣开源生态。
OpenHarmony:内核对象队列之算法详解(下)
作者:蒋卫峰
深圳开鸿数字产业发展有限公司
OS内核开发工程师
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 4372
4372






 淘帖
淘帖
 显身卡
显身卡




