本文介绍了一种用于实时语音增强的双信号变换LSTM 网络 (DTLN),作为深度噪声抑制挑战 (DNS-Challenge) 的一部分。该方法将短时傅立叶变换 (STFT) 和学习分析和综合基础结合在堆栈网络方法中,参数少于一百万个。该模型使用挑战组织者提供的 500 小时的嘈杂语音进行训练。 该网络能够进行实时处理(一帧输入,一帧输 出)并达到有竞争力的结果。将这两种类型的信号变换结合起来,使 DTLN 能够从幅度谱中稳健地提取信息,并从学习的特征基础中合并相位信息。该方法显示了最先进的性能,并且以平均意见得分 (MOS) 计绝对优于 DNS-Challenge 基线 0.24 分。
噪声抑制任务是语音增强领域的一个重要学科, 随着深度神经网络的兴起,提出了几种基于深度模型的音频处理新方法[1,2,3,4]。然而,这些通常是为离线处理而开发的,不需要考虑实时性。当使用神经网络设计基于框架的算法时,递归神经网络 (RNN)是常见的选择。 RNN 在语音增强 [7, 8] 和语音分离 [9, 10, 11] 领域取得了令人信服的结果。长短期记忆网络(LSTM)[12]代表了分离领域的最先进技术[13]。性能最佳的网络通常是通过使用双向 LSTM 以非因果方式构建的。
本文介绍的堆叠双信号变换LSTM 网络架构如下:
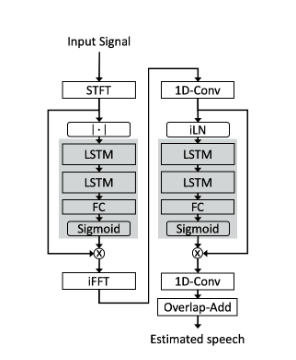
本文介绍的堆叠双信号变换LSTM 网络架构具有两个分离核心,其中包含两个 LSTM 层,后跟一个全连接(FC)层和一个用于创建掩码输出的 sigmoid 激活层。第一个分离核心使用 STFT 分析和合成基础。FC 层和 sigmoid 激活预测的掩模乘以混合的幅度,并使用输入混合的相位转换回时域。来自第一个网络的帧由 1D-Conv 层处理以创建特征表示。特征表示在被馈送到第二个分离核心之前由归一化层进行处理。第二个核的预测掩模与特征表示的非标准化版本相乘。结果用作 1D-Conv 层的输入,用于将估计表示转换回时域。在最后一步中,通过重叠相加过程重建信号。
训练数据集是根据DNS 挑战赛提供的音频数据创建的。语音数据是 Lib-rispeech 语料库 [23] 的一 部分,噪声信号源自 Audioset 语料库 [24]、 Freesound 和 DEMAND 语料库 [25]。使用提供的脚本创建了 500 小时的数据。默认 SNR 范围(0 至 40 dB)更改为 -5 至 25 dB,以包含负 SNR 并限制总范围。为了覆盖更细粒度的 SNR 分布,SNR 级别的数量从 5 增加到 30。所有其他参数保持不变。 500 小时的数据集分为训练数据(400 小时)和交叉验证数据(100 小时),这对应于常见的 80:20% 分割。所有训练数据均以 16 kHz 采样。挑战组织者还提供了一个测试集,其中包含四个不同类别, 每个类别包含 300 个样本。这些类别是无混响的合成剪辑、有混响的合成剪辑、Microsoft 内部收集的真实录音和 Audioset 的真实录音。合成数据取自格拉茨大学的干净语音数据集 [26]。合成数据的 SNR在0到25dB SNR之间随机分布。混响数据的脉冲响应是在 Microsoft 的多个房间中测量的,混响时间 (RT˯˩) 范围为 300 到 1300 毫秒。此外,组织者创建了盲测集,并在 ITU P-808 [27] 设置中进行评估。 [14] 中提供了训练和测试集的完整细节。为了正确估计噪声混响环境中所有客观测量的性能, 使用了 WHAMR 语料库 [19] 的混响单扬声器和噪声测试集,采样频率为 16 kHz。
本文中的DTLN 在其四个 LSTM 层中各有 128 个单元。帧大小为 32 ms,移位为 8 ms。 FFT 大小为 512,等于帧长度。用于创建学习特征表示的 1D-Conv 层有 256 个过滤器。在训练期间,在 LSTM 层之间应用 25% 的 dropout。使用 Adam 优化器,学习率为 10e-3,梯度范数裁剪为 3。如果验证集上的损失在十个时期内没有减少,则应用提前停止。该模型以 32 的批量大小进行训练,每个样本的长度为 15 秒。 Nvidia RTX 2080 TI 上一个训练周期的平均时间约为 21 分钟。使用尺度敏感的负 SNR [20] 作为训练目标。与尺度不变信噪比(SI-SNR)[11]相比,它应该避免输入混合和预测的干净语音之间可能存在的电平偏移,这在实时处理系统中是可取的。此外, 由于它在时域中操作,因此可以隐式地考虑相位信息。相比之下,语音信号的估计幅度和干净幅度 STFT 之间的均方误差作为训练目标无法在优化过程中使用任何相位信息。
模型效果的比较
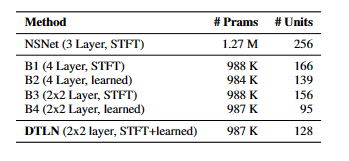
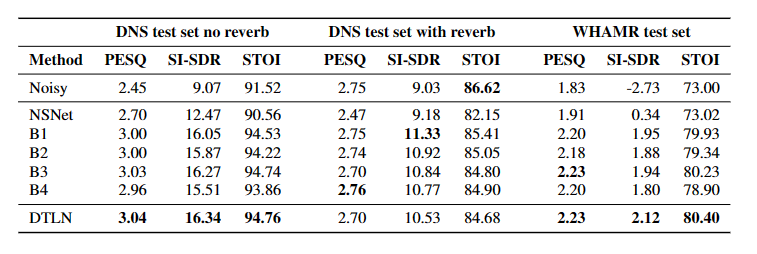
本文介绍了一种基于堆叠双信号变换LSTM 网络 的噪声抑制方法,用于实时语音增强,并在大规 模数据集上进行训练。我们能够展示在堆叠网络 方法中使用两种类型的分析和综合基础的优势。 DTLN 模型在嘈杂的混响环境中运行稳健。尽管 我们将基本训练设置与简单的架构相结合,但我 们观察到相对于噪声条件的所有主观评估在 MOS 方面的绝对改进为 0.22。
 0
0
|
|
|
|
|
|
|
 /7
/7 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号









 淘帖
淘帖 12890
12890







