现在市面上有很多APP,都或多或少对图片有模糊上的设计,所以,图片模糊效果到底怎么实现的呢?
首先,我们来了解下模糊效果的对比

从视觉上,两张图片,有一张是模糊的,那么,在实现图片模糊效果之前,我们首先需要了解图片模糊的本质是什么?
在此介绍模糊本质之前,我们来了解下当前主流的两个移动端平台(Android与iOS)的实现。
对Android开发者而言,比较熟悉且完善的图片变换三方库以glide-transformations(https://github.com/wasabeef/glide-transformations)为样例,来看看它是基于什么实现的。
Android中有两种实现:
1、 FastBlur,根据stackBlur模糊算法来操作图片的像素点实现效果,但效率低,已过时。
2、 RenderScript,这个是Google官方提供的,用来在Android上编写一套高性能代码的语言,可以运行在CPU及其GPU上,效率较高。
而对iOS开发者而言,GPUImage(https://github.com/BradLarson/GPUImage/)比较主流。我们可以在其中看到高斯模糊过滤器(GPUImageGaussianBlurFilter),它里面是根据OpenGL来实现,通过GLSL语言定义的着色器,操作GPU单元,达到模糊效果。
所以,我们可以看出,操作GPU来达到我们所需要的效果效率更高。因此我们在OpenHarmony上也能通过操作GPU,来实现我们想要的高性能模糊效果。
回归正题,先来了解下模糊的本质是什么?
本质
模糊,可以理解为图片中的每个像素点都取其周边像素的平均值。

上图M点的像素点就是我们的焦点像素。周围ABCDEFGH都是M点(焦点)周围的像素点,那么根据模糊的概念:
M(rgb) =(A+B+C+D+E+F+G+H)/ 8
我们根据像素点的r、g、b值,得到M点的像素点值,就这样,一个一个像素点的操作,中间点相当于失去视觉上的焦点,整个图片就产生模糊的效果。但这样一边倒的方式,在模糊的效果上,达不到需求的,所以,我们就需要根据这个模糊的本质概念,去想想,加一些东西或者更改取平均值的规则,完成我们想要的效果。故,高斯模糊,一个家喻户晓的名字,就出现在我们面前。
高斯模糊
高斯模糊,运用了正态分布函数,进行各个加权平均,正态分布函数如下:
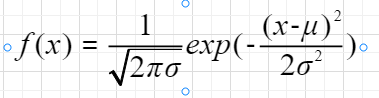
其中参数:μ为期望值,σ为标准差,当μ=0,σ=0的时候,为标准的正态分布,其形状参考如下图:

可以看出:
其一,离中心点越近,分配的权重就越高。这样我们在计算图片的焦点像素值时,将该点当作中心点,当作1的权重,其他周围的点,按照该正态分布的位置,去分配它的权重,这样我们就可以根据该正态分布函数及其各个点的像素ARGB值,算出经过正态分布之后的像素ARGB值。
其二,离中心点越近,若是设置的模糊半径很小,代表其模糊的焦点周围的像素点离焦点的像素相差就不大,这样模糊的效果就清晰。而模糊半径越大,其周围分布的像素色差就很大,这样的模糊效果就越模糊。
通过图片的宽高拿到每个像素点的数据,再根据这个正态分布公式,得到我们想要的像素点的ARGB值,之后将处理过的像素点重新写入到图片中,就能实现我们想要的图片模糊效果。
流程
根据上面的阐述,就可以梳理出在OpenHarmony中的具体的实现流程:
● 获取整张图片的像素点数据
● 循环图片的宽高,获取每个像素点的焦点
● 在上述循环里,根据焦点按照正态分布公式进行加权平均,算出各个焦点周围新的像素值
● 将各个像素点写入图片
关键依赖OpenHarmony系统基础能力如下:
第一、获取图片的像素点,系统有提供一次性获取整张图片的像素点数据,其接口如下。
readPixelsToBuffer(dst: ArrayBuffer): Promise
readPixelsToBuffer(dst: ArrayBuffer, callback: AsyncCallback
可以看出,系统将获取到像素点数据ARGB值,存储到ArrayBuffer中去。
第二、循环获取每个像素点,将其x、y点的像素点当作焦点。
for (y = 0; y < imageHeight; y++) {
for (x = 0; x < imageWidth; x++) {
}
}
第三、循环获取焦点周围的像素点(以焦点为原点,以设置的模糊半径为半径)。
for ( let m = centPointY-radius; m < centPointY+radius; m++) {
for ( let n = centPointX-radius; n < centPointX+radius; n++) {
this.calculatedByNormality(...);
}
}
第四、将各个图片的像素数据写入图片中。系统有提供一次性写入像素点,其接口如下。
writeBufferToPixels(src: ArrayBuffer): Promise
writeBufferToPixels(src: ArrayBuffer, callback: AsyncCallback
通过上面的流程,我们可以在OpenHarmony系统下,获取到经过正态分布公式处理的像素点,至此图片模糊效果已经实现。
但是,经过测试发现,这个方式实现模糊化的过程,很耗时,达不到我们的性能要求。若是一张很大的图片,就单单宽高循环来看,比如1920*1080宽高的图片就要循环2,073,600次,非常耗时且对设备的CPU也有非常大的消耗,因此我们还需要对其进行性能优化。
模糊性能优化思路
如上面所诉,考虑到OpenHarmony的环境的特点及其系统提供的能力,可以考虑如下几个方面进行优化:
第一、参照社区已有成熟的图片模糊算法处理,如(Android的FastBlur)。
第二、C层性能要比JS层更好,将像素点的数据处理,通过NAPI机制,将其放入C层处理。如:将其循环获取焦点及其通过正态分布公式处理的都放到C层中处理。
第三、基于系统底层提供的OpenGL,操作顶点着色器及片元着色器操作GPU,得到我们要的模糊效果。
首先,我们来根据Android中的FastBlur模糊化处理,参照其实现原理进行在基于OpenHarmony系统下实现的代码如下:
let imageInfo = await bitmap.getImageInfo();
let size = {
width: imageInfo.size.width,
height: imageInfo.size.height
}
if (!size) {
func(new Error("fastBlur The image size does not exist."), null)
return;
}
let w = size.width;
let h = size.height;
var pixEntry: Array
var pix: Array
let bufferData = new ArrayBuffer(bitmap.getPixelBytesNumber());
await bitmap.readPixelsToBuffer(bufferData);
let dataArray = new Uint8Array(bufferData);
for (let index = 0; index < dataArray.length; index+=4) {
const r = dataArray[index];
const g = dataArray[index+1];
const b = dataArray[index+2];
const f = dataArray[index+3];
let entry = new PixelEntry();
entry.a = 0;
entry.b = b;
entry.g = g;
entry.r = r;
entry.f = f;
entry.pixel = ColorUtils.rgb(entry.r, entry.g, entry.b);
pixEntry.push(entry);
pix.push(ColorUtils.rgb(entry.r, entry.g, entry.b));
}
let wm = w - 1;
let hm = h - 1;
let wh = w * h;
let div = radius + radius + 1;
let r = CalculatePixelUtils.createIntArray(wh);
let g = CalculatePixelUtils.createIntArray(wh);
let b = CalculatePixelUtils.createIntArray(wh);
let rsum, gsum, bsum, x, y, i, p, yp, yi, yw: number;
let vmin = CalculatePixelUtils.createIntArray(Math.max(w, h));
let divsum = (div + 1) >> 1;
divsum *= divsum;
let dv = CalculatePixelUtils.createIntArray(256 * divsum);
for (i = 0; i < 256 * divsum; i++) {
dv[i] = (i / divsum);
}
yw = yi = 0;
let stack = CalculatePixelUtils.createInt2DArray(div, 3);
let stackpointer, stackstart, rbs, routsum, goutsum, boutsum, rinsum, ginsum, binsum: number;
let sir: Array
let r1 = radius + 1;
for (y = 0; y < h; y++) {
rinsum = ginsum = binsum = routsum = goutsum = boutsum = rsum = gsum = bsum = 0;
for (i = -radius; i <= radius; i++) {
p = pix[yi + Math.min(wm, Math.max(i, 0))];
sir = stack[i + radius];
sir[0] = (p & 0xff0000) >> 16;
sir[1] = (p & 0x00ff00) >> 8;
sir[2] = (p & 0x0000ff);
rbs = r1 - Math.abs(i);
rsum += sir[0] * rbs;
gsum += sir[1] * rbs;
bsum += sir[2] * rbs;
if (i > 0) {
rinsum += sir[0];
ginsum += sir[1];
binsum += sir[2];
} else {
routsum += sir[0];
goutsum += sir[1];
boutsum += sir[2];
}
}
stackpointer = radius;
for (x = 0; x < w; x++) {
r[yi] = dv[rsum];
g[yi] = dv[gsum];
b[yi] = dv[bsum];
rsum -= routsum;
gsum -= goutsum;
bsum -= boutsum;
stackstart = stackpointer - radius + div;
sir = stack[stackstart % div];
routsum -= sir[0];
goutsum -= sir[1];
boutsum -= sir[2];
if (y == 0) {
vmin[x] = Math.min(x + radius + 1, wm);
}
p = pix[yw + vmin[x]];
sir[0] = (p & 0xff0000) >> 16;
sir[1] = (p & 0x00ff00) >> 8;
sir[2] = (p & 0x0000ff);
rinsum += sir[0];
ginsum += sir[1];
binsum += sir[2];
rsum += rinsum;
gsum += ginsum;
bsum += binsum;
stackpointer = (stackpointer + 1) % div;
sir = stack[(stackpointer) % div];
routsum += sir[0];
goutsum += sir[1];
boutsum += sir[2];
rinsum -= sir[0];
ginsum -= sir[1];
binsum -= sir[2];
yi++;
}
yw += w;
}
for (x = 0; x < w; x++) {
rinsum = ginsum = binsum = routsum = goutsum = boutsum = rsum = gsum = bsum = 0;
yp = -radius * w;
for (i = -radius; i <= radius; i++) {
yi = Math.max(0, yp) + x;
sir = stack[i + radius];
sir[0] = r[yi];
sir[1] = g[yi];
sir[2] = b[yi];
rbs = r1 - Math.abs(i);
rsum += r[yi] * rbs;
gsum += g[yi] * rbs;
bsum += b[yi] * rbs;
if (i > 0) {
rinsum += sir[0];
ginsum += sir[1];
binsum += sir[2];
} else {
routsum += sir[0];
goutsum += sir[1];
boutsum += sir[2];
}
if (i < hm) {
yp += w;
}
}
yi = x;
stackpointer = radius;
for (y = 0; y < h; y++) {
pix[yi] = (0xff000000 & pix[Math.round(yi)]) | (dv[Math.round(rsum)] << 16) | (dv[
Math.round(gsum)] << 8) | dv[Math.round(bsum)];
rsum -= routsum;
gsum -= goutsum;
bsum -= boutsum;
stackstart = stackpointer - radius + div;
sir = stack[stackstart % div];
routsum -= sir[0];
goutsum -= sir[1];
boutsum -= sir[2];
if (x == 0) {
vmin[y] = Math.min(y + r1, hm) * w;
}
p = x + vmin[y];
sir[0] = r[p];
sir[1] = g[p];
sir[2] = b[p];
rinsum += sir[0];
ginsum += sir[1];
binsum += sir[2];
rsum += rinsum;
gsum += ginsum;
bsum += binsum;
stackpointer = (stackpointer + 1) % div;
sir = stack[stackpointer];
routsum += sir[0];
goutsum += sir[1];
boutsum += sir[2];
rinsum -= sir[0];
ginsum -= sir[1];
binsum -= sir[2];
yi += w;
}
}
let bufferNewData = new ArrayBuffer(bitmap.getPixelBytesNumber());
let dataNewArray = new Uint8Array(bufferNewData);
let index = 0;
for (let i = 0; i < dataNewArray.length; i += 4) {
dataNewArray[i] = ColorUtils.red(pix[index]);
dataNewArray[i+1] = ColorUtils.green(pix[index]);
dataNewArray[i+2] = ColorUtils.blue(pix[index]);
dataNewArray[i+3] = pixEntry[index].f;
index++;
}
await bitmap.writeBufferToPixels(bufferNewData);
if (func) {
func("success", bitmap);
}
从上面代码,可以看出,按照FastBlur的逻辑,还是逃不开上层去处理单个像素点,逃不开图片宽高的循环。经过测试也发现,在一张400*300的图片上,完成图片的模糊需要十几秒,所以第一个优化方案,在js环境上是行不通的。
其次,将其像素点处理,通过NAPI的机制,将像素点数据ArrayBuffer传入到C层,由于在C层也需要循环去处理每个像素点,传入大数据的ArrayBuffer时对系统的native的消耗严重。最后经过测试也发现,模糊的过程也很缓慢,达不到性能要求。
所以对比分析之后,最终的优化方案是采取系统底层提供的OpenGL,通过GPU去操作系统的图形处理器,解放出CPU的能力。
基于OpenGL操作GPU来提升模糊性能
在进行基于OpenGL进行性能提升前,我们需要了解OpenGL中的顶点着色器(vertex shader)及其片元着色器(fragment shader)。着色器(shader)是运行在GPU上的最小单元,功能是将输入转换输出且各个shader之间是不能通信的,需要使用的开发语言GLSL。这里就不介绍GLSL的语言规则了。
顶点着色器(vertex shader)
确定要画图片的各个顶点(如:三角形的角的顶点),注意:每个顶点运行一次。一旦最终位置已知,OpenGL将获取可见的顶点集,并将它们组装成点、线和三角形。且以逆时针绘制的。
片元着色器(fragment shader)
生成点、线或三角形的每个片元的最终颜色,并对每个fragment运行一次。fragment是单一颜色的小矩形区域,类似于计算机屏幕上的像素,简单的说,就是将顶点着色器形成的点、线或者三角形区域,添加颜色。
片元着色器的主要目的是告诉GPU每个片元的最终颜色应该是什么。对于图元(primitive)的每个fragment,片元着色器将被调用一次,因此如果一个三角形映射到10000个片元,那么片元着色器将被调用10000次。
OpenGL简单的绘制流程:
读取顶点信息 ----------> 运行顶点着色器 ----------> 图元装配----------> 运行片元着色器----------> 往帧缓冲区写入----------> 屏幕上最终效果
简单的说,就是根据顶点着色器形成的点、线、三角形形成的区域,由片元着色器对其着色,之后就将这些数据写入帧缓冲区(Frame Buffer)的内存块中,再由屏幕显示这个缓冲区。
那模糊的效果怎么来实现呢?
首先我们来定义我们的顶点着色器及其片元着色器。如下代码:
顶点着色器:
const char vShaderStr[] =
"#version 300 es \\n"
"layout(location = 0) in vec4 a_position; \\n"
"layout(location = 1) in vec2 a_texCoord; \\n"
"out vec2 v_texCoord; \\n"
"void main() \\n"
"{ \\n"
" gl_Position = a_position; \\n"
" v_texCoord = a_texCoord; \\n"
"} \\n";
片元着色器:
const char fShaderStr0[] =
"#version 300 es \\n"
"precision mediump float; \\n"
"in vec2 v_texCoord; \\n"
"layout(location = 0) out vec4 outColor; \\n"
"uniform sampler2D s_TextureMap; \\n"
"void main() \\n"
"{ \\n"
" outColor = texture(s_TextureMap, v_texCoord); \\n"
"}";
其中version代表OpenGL的版本,layout在GLSL中是用于着色器的输入或者输出,uniform为一致变量。在着色器执行期间一致变量的值是不变的,只能在全局范围进行声明,gl_Position是OpenGL内置的变量(输出属性-变换后的顶点的位置,用于后面的固定的裁剪等操作。所有的顶点着色器都必须写这个值),texture函数是openGL采用2D纹理绘制。然后,我们还需要定义好初始的顶点坐标数据等;
const GLfloat vVertices[] = {
-1.0f, -1.0f, 0.0f,
1.0f, -1.0f, 0.0f,
-1.0f, 1.0f, 0.0f,
1.0f, 1.0f, 0.0f,
};
const GLfloat vTexCoors[] = {
0.0f, 1.0f,
1.0f, 1.0f,
0.0f, 0.0f,
1.0f, 0.0f,
};
const GLfloat vFboTexCoors[] = {
0.0f, 0.0f,
1.0f, 0.0f,
0.0f, 1.0f,
1.0f, 1.0f,
};
下面就进行OpenGL的初始化操作,获取display,用来创建EGLSurface的
m_eglDisplay = eglGetDisplay(EGL_DEFAULT_DISPLAY)
初始化 EGL 方法
eglInitialize(m_eglDisplay, &eglMajVers, &eglMinVers)
获取 EGLConfig 对象,确定渲染表面的配置信息
eglChooseConfig(m_eglDisplay, confAttr, &m_eglConf, 1, &numConfigs)
创建渲染表面 EGLSurface,使用 eglCreatePbufferSurface 创建屏幕外渲染区域
m_eglSurface = eglCreatePbufferSurface(m_eglDisplay, m_eglConf, surfaceAttr)
创建渲染上下文 EGLContext
m_eglCtx = eglCreateContext(m_eglDisplay, m_eglConf, EGL_NO_CONTEXT, ctxAttr)
绑定上下文
eglMakeCurrent(m_eglDisplay, m_eglSurface, m_eglSurface, m_eglCtx)
通过默认的顶点着色器与片元着色器,加载到GPU中
GLuint GLUtils::LoadShader(GLenum shaderType, const char *pSource)
{
GLuint shader = 0;
shader = glCreateShader(shaderType);
if(shader)
{
glShaderSource(shader, 1, &pSource, NULL);
glCompileShader(shader);
GLint compiled = 0;
glGetShaderiv(shader, GL_COMPILE_STATUS, &compiled);
if (!compiled){
GLint infoLen = 0;
glGetShaderiv(shader, GL_INFO_LOG_LENGTH, &infoLen);
if (infoLen)
{
char* buf = (char*) malloc((size_t)infoLen);
if (buf)
{
glGetShaderInfoLog(shader, infoLen, NULL, buf);
LOGI("gl--> GLUtils::LoadShader Could not link shader:%{public}s", buf);
free(buf);
}
glDeleteShader(shader);
shader = 0;
}
}
}
return shader;
}
创建一个空的着色器程序对象
program = glCreateProgram()
将着色器对象附加到program对象
glAttachShader(program, vertexShaderHandle);
glAttachShader(program, fragShaderHandle);
连接一个program对象
glLinkProgram(program);
创建并初始化缓冲区对象的数据存储
glGenBuffers(3, m_VboIds)
glBindBuffer(GL_ARRAY_BUFFER, m_VboIds[0])
glBufferData(GL_ARRAY_BUFFER, sizeof(vVertices), vVertices, GL_STATIC_DRAW)
glBindBuffer(GL_ARRAY_BUFFER, m_VboIds[1])
glBufferData(GL_ARRAY_BUFFER, sizeof(vFboTexCoors), vTexCoors, GL_STATIC_DRAW)
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, m_VboIds[2])
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW)
glGenVertexArrays(1, m_VaoIds)
glBindVertexArray(m_VaoIds[0])
到这,整个OpenGL的初始化操作,差不多完成了,接下来,我们就要去基于OpenGL去实现我们想要的模糊效果。
考虑到模糊的效果,那么我们需要给开发者提供模糊半径blurRadius、模糊偏移量blurOffset、模糊的权重sumWeight。所以我们需要在我们模糊的片元着色器上,定义开发者输入,其模糊的片元着色器代码如下:
const char blurShaderStr[] =
"#version 300 es\\n"
"precision highp float;\\n"
"uniform lowp sampler2D s_TextureMap;\\n"
"in vec2 v_texCoord;\\n"
"layout(location = 0) out vec4 outColor;\\n"
"uniform highp int blurRadius;\\n"
"uniform highp vec2 blurOffset;\\n"
"\\n"
"uniform highp float sumWeight;\\n"
"float PI = 3.1415926;\\n"
"float getWeight(int i)\\n"
"{\\n"
"float sigma = float(blurRadius) / 3.0;\\n"
"return (1.0 / sqrt(2.0 * PI * sigma * sigma)) * exp(-float(i * i) / (2.0 * sigma * sigma)) / sumWeight;\\n"
"}\\n"
"vec2 clampCoordinate(vec2 coordinate)\\n"
"{\\n"
" return vec2(clamp(coordinate.x, 0.0, 1.0), clamp(coordinate.y, 0.0, 1.0));\\n"
"}\\n"
"\\n"
"void main()\\n"
"{\\n"
"vec4 sourceColor = texture(s_TextureMap, v_texCoord);\\n"
"if (blurRadius <= 1)\\n"
"{\\n"
"outColor = sourceColor;\\n"
"return;\\n"
"}\\n"
"float weight = getWeight(0);\\n"
"vec3 finalColor = sourceColor.rgb * weight;\\n"
"for (int i = 1; i < blurRadius; i++)\\n"
"{\\n"
"weight = getWeight(i);\\n"
"finalColor += texture(s_TextureMap, clampCoordinate(v_texCoord - blurOffset * float(i))).rgb * weight;\\n"
"finalColor += texture(s_TextureMap, clampCoordinate(v_texCoord + blurOffset * float(i))).rgb * weight;\\n"
"}\\n"
"outColor = vec4(finalColor, sourceColor.a);\\n"
"}\\n";
里面的逻辑暂时就不介绍了,有兴趣的朋友可以去研究研究。
通过上述的LoadShader函数将其片元着色器加载到GPU的运行单元中去。
m_ProgramObj = GLUtils::CreateProgram(vShaderStr, blurShaderStr, m_VertexShader,
m_FragmentShader);
if (!m_ProgramObj)
{
GLUtils::CheckGLError("Create Program");
LOGI("gl--> EGLRender::SetIntParams Could not create program.");
return;
}
m_SamplerLoc = glGetUniformLocation(m_ProgramObj, "s_TextureMap");
m_TexSizeLoc = glGetUniformLocation(m_ProgramObj, "u_texSize");
然后我们就需要将图片的整个像素数据传入;
定义好ts层的方法:
setImageData(buf: ArrayBuffer, width: number, height: number){
if(!buf){
thrownewError("this pixelMap data is empty");
}
if(width <=0|| height <=0){
thrownewError("this pixelMap of width and height is invalidation");
}
this.width = width;
this.height = height;
this.ifNeedInit();
this.onReadySize();
this.setSurfaceFilterType();
this.render.native_EglRenderSetImageData(buf, width, height);
};
将ArrayBuffer数据传入NAPI层。通过napi_get_arraybuffer_info NAPI获取ArrayBuffer数据。
napi_value EGLRender::RenderSetData(napi_env env, napi_callback_info info) {
....
void* buffer;
size_t bufferLength;
napi_status buffStatus= napi_get_arraybuffer_info(env,args[0],&buffer,&bufferLength);
if (buffStatus != napi_ok) {
return nullptr;
}
....
EGLRender::GetInstance()->SetImageData(uint8_buf, width, height);
return nullptr;
}
将其数据绑定到OpenGL中的纹理中去
void EGLRender::SetImageData(uint8_t *pData, int width, int height){
if(pData && m_IsGLContextReady)
{
...
m_RenderImage.width = width;
m_RenderImage.height = height;
m_RenderImage.format =IMAGE_FORMAT_RGBA;
NativeImageUtil::AllocNativeImage(&m_RenderImage);
memcpy(m_RenderImage.ppPlane[0], pData, width*height*4);
glBindTexture(GL_TEXTURE_2D, m_ImageTextureId);
glTexImage2D(GL_TEXTURE_2D,0,GL_RGBA, m_RenderImage.width, m_RenderImage.height,0,GL_RGBA,GL_UNSIGNED_BYTE, m_RenderImage.ppPlane[0]);
glBindTexture(GL_TEXTURE_2D,GL_NONE);
....
}
}
然后就是让开发者自己定义模糊半径及其模糊偏移量,通过OpenGL提供的
glUniform1i(location,(int)value); 设置int 片元着色器blurRadius变量
glUniform2f(location,value[0],value[1]); 设置float数组 片元着色器blurOffset变量
将半径及其偏移量设置到模糊的片元着色器上。之后,通过GPU将其渲染
napi_value EGLRender::Rendering(napi_env env, napi_callback_info info){
glDrawElements(GL_TRIANGLES,6,GL_UNSIGNED_SHORT,(const void *)0);
glBindVertexArray(GL_NONE);
glBindTexture(GL_TEXTURE_2D,GL_NONE);
return nullptr;
}
最后,就剩下获取图片像素的ArrayBuffer数据了,通过glReadPixels读取到指定区域内的像素点了
glReadPixels(x,y,surfaceWidth,surfaceHeight,GL_RGBA,GL_UNSIGNED_BYTE,pixels);
但是,在这里,因为OpenGL里面的坐标系,在2D的思维空间上,与我们通常认知的是倒立的,所以需要对像素点进行处理,得到我们想要的像素点集
int totalLength= width * height * 4;
int oneLineLength = width * 4;
uint8_t* tmp = (uint8_t*)malloc(totalLength);
memcpy(tmp, *buf, totalLength);
memset(*buf,0,sizeof(uint8_t)*totalLength);
for(int i = 0 ; i< height;i ++){
memcpy(*buf+oneLineLength*i, tmp+totalLength-oneLineLength*(i+1), oneLineLength);
}
free(tmp);
最后在上层,通过系统提供的createPixelMap得到我们想要的图片,也就是模糊的图片。
getPixelMap(x: number,y: number,width: number,height: number): Promise<image.PixelMap>{
.....
let that =this;
returnnewPromise((resolve, rejects)=>{
that.onDraw();
let buf =this.render.native_EglBitmapFromGLSurface(x, y, width, height);
if(!buf){
rejects(newError("get pixelMap fail"))
}else{
let initOptions ={
size:{
width: width,
height: height
},
editable:true,
}
image.createPixelMap(buf, initOptions).then(p=>{
resolve(p);
}).catch((e)=>{
rejects(e)
})
}
})
}
综上,本篇文章介绍了由单纯的在JS中用正态分布公式操作像素点实现模糊效果,引出性能问题,最后到基于OpenGL实现模糊效果的优化,最后性能上也从模糊一张大图片要十几秒提升到100ms内,文章就介绍到这了,欢迎有兴趣的朋友,可以参考学习下,下面提供具体的项目源码地址。
项目地址:https://gitee.com/openharmony-tpc/ImageKnife/tree/master/gpu_transform
 /7
/7 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 525
525

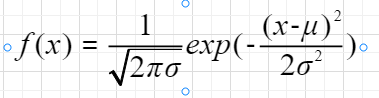

 淘帖
淘帖






