恩智浦最新的应用处理器 i.MX 95使用恩智浦专有的NPU IP进行片上AI加速,这与之前使用第三方IP的 i.MX 产品不同。
i.MX 95 系列专为汽车、工业和物联网市场中的人工智能应用而开发,具有符合 ISO 26262 ASIL-B 和 IEC 61508 SIL-2 功能安全标准的安全功能,包括安全岛。典型应用包括工厂机器视觉和车辆语音警告、仪器仪表和摄像系统。
i.MX 95系列具有多达六个ARM Cortex-A55 CPU,以及用于3D图形的ARM Mali GPU,以及恩智浦专用的2-TOPS中子NPU和内部开发的图像信号处理器(ISP)。ISP 处理相机接口和图像预处理,包括高动态范围 (HDR)、去噪和边缘增强等任务。

恩智浦 i.MX 95应用处理器框图(点击放大)(来源:恩智浦半导体)
恩智浦的Neutron NPU是一款通用矩阵乘法加速器,旨在从片上CPU内核卸载AI工作负载。i.MX 95版本的Neutron是以前在MCX-N中使用的IP的放大版本。MCX-N 中的加速器是一款 150 MHz 微控制器,每个周期提供 16 个 MAC,而 95 i.MX 的 2-TOPS NPU 可以在 1 GHz 或更高频率下运行。(总体而言,IP 每个周期最多可扩展到 10,000 个操作。
扩大规模带来了自己的挑战,恩智浦全球人工智能战略和边缘处理技术总监Ali Ors告诉EE Times。
“当你开始在计算能力方面变得更大时,你必须照顾更多的数据移动、暂存、权重管理、DMA 缓冲等,”他说。
Neutron可以运行神经网络,包括CNN,RNN,TCN和变压器。Ors说,对包括MobileNet,MobileNet-SSD和Yolo在内的CNN的内部测试表明,与片上Cortex-A100s相比,Neutron将吞吐量提高了300×至55×,具体取决于型号。
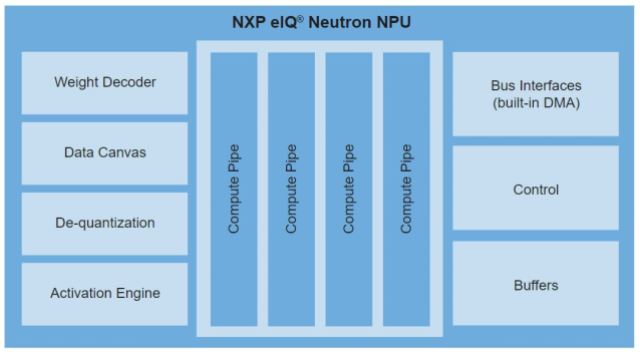
恩智浦的Neutron NPU,出现在 i.MX 95应用处理器中(来源:恩智浦半导体)
i.MX 95中的中子NPU取代了 i.MX 65中的ARM Ethos-U93。为什么要更改为内部?
“这是我们自己战略的一部分,独立于ARM围绕加速器的产品和业务战略,”Ors说。“我们在市场上看到的以及我们决定执行的是,机器学习加速是我们在嵌入式处理器节点上大量参与的所有三个市场空间的基本组成部分。因此,我们拥有这座建筑是有意义的。
他说,如果恩智浦拥有硬件IP,这意味着恩智浦的eIQ软件开发环境可以作为当今和未来具有AI加速芯片部件的统一因素。
Ors还指出,AI工作负载仍然非常动态;模型仍在快速发展,它们使用的基元和数据类型也是如此。
“不断依赖软件,能够匹配硬件来运行这个领域的新事物,这是一个挑战,”他说。“我们认为我们可以更好地支持我们的客户 - 特别是考虑到恩智浦对供应可用性有15年的保证 - 我们必须维护,支持并确保这些[零件]在部署到市场后仍在工作。
他补充说,这包括能够更好地支持现场更新。
在 i.MX 93之前,i.MX 8M +采用了芯原的片上加速器IP,尺寸为2.3 TOPS。i.MX 2 中的 95 个 TOPS 引擎是否代表比前一部分更小的 AI 功能?
“它的原始性能大致相同,但根据型号的不同,我们至少可以运行 2× 到 4×,因为我们能够在 8M+ 与 i.MX 95 上运行,”Ors 说。“这是机器学习模型如何演变以及架构如何演变以匹配市场需求的功能......对于某些工作负载,95的NPU比8M +的NPU效率高得多,这些工作负载今天比8M +设计时更普遍。
未来的恩智浦应用处理器也将使用该公司的Neutron IP。
“我们计划围绕可能针对可能使用相同的2-TOPS变体[Neutron]的更具体的垂直市场的设备,但即使在该变体中,我们提供的内部缓冲区数量或我们提供的内部接口也可能存在差异DDR等,”Ors说。
恩智浦面向人工智能的eIQ软件开发环境包括用于数据收集和数据集管理的工具,以及为恩智浦目标和部署选择模型、训练和分析的工具。
“eIQ工具包是一个完整的流程,但在任何阶段,你都可以选择你想使用多少恩智浦工具,而不是你想从你自己的脚本或你自己的工具偏好中利用什么,”Ors说。
恩智浦的API目前以抢先体验的方式向合作伙伴开放;这允许第三方为特定用例和工具引入其数据集或模型,例如专有量化工具。Ors表示,恩智浦正在努力扩大此API的可用性。
也就是说,恩智浦不会依赖第三方为eIQ带来差异化功能。恩智浦自己添加的最新功能是水印,旨在减轻IP盗窃,因为它允许客户判断其部署的模型是否被盗。
Ors描述了如何使用蛮力从最终工作模型重新创建AI模型 - 使用某些输入,收集输出并从那里对权重进行逆向工程。这将允许某人在自己的产品中有效地复制该模型。恩智浦的水印工具旨在检测何时发生这种情况,并证明被盗IP合法属于谁。
水印工具将水印插入到训练数据中,在本例中,人眼可能可见也可能不可见的变化。结果是,该模型将错误分类某些带水印的测试图像,以便使用带水印的测试图像测试竞争对手的产品将证明IP的所有权。此水印不会影响模型的性能或准确性。
今天有人会费心对图像处理模型进行逆向工程而不是开发自己的模型,这现实吗?
“逆向工程可能比收集特定的训练数据更少,使模型真正健壮,”Ors说。“当图像很容易收集时,这是没有意义的,但是当你进入非常具体的工业应用或医疗应用时,训练数据比你从公开可用的图像数据集中获得的数据更有价值。
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 554
554

 淘帖
淘帖





