
文/KeenTune SIG
KeenTune(轻豚)是一款 AI 算法与专家知识库双轮驱动的操作系统全栈式智能优化产品,为主流的操作系统提供轻量化、跨平台的一键式性能调优,让应用在智能定制的运行环境发挥最优性能。自 2021年 9 月正式成立 SIG 并[宣布开源]以来,受到了广大开发者的关注。KeenTune 的整体开源框架聚焦于通用和灵活的设计原则,其中对于调优场景的扩展,通过分布式架构以及标准化的场景配置模式,可以方便的实现对于 Linux 内核参数,应用配置参数,编译器优化参数,benchmark 配置参数等调优对象和配套工具的快速适配。
今天, KeenTune 再次带来开源重磅特性——新增通用的调优算法框架:keenopt。有了 keenopt 的加持,KeenTune 不再仅仅是支持灵活扩展调优场景的调优工具,还成长为了具备灵活扩展调优算法的调优平台,不仅可以作为性能调优工程师的法宝,也可以成为算法工程师的利器。Keenopt 调优算法框架的开源设计,同样旨在方便快捷的扩展学术界和工业界新提出的调优算法,以及结合实际需要定制化的调优算法。
聪明的童鞋一定会自然问出一个问题:为什么不能只调用当前流行的调优算法库,而要打造一个算法框架呢?这就要从我们调优过程中趟过的一个一个坑说起了...
坑洼调优路
一提起调优,首先进入读者脑海的就是近年来愈发流行的针对机器学习模型,尤其是神经网络超参数的调优算法。这些调优算法从贝叶斯优化和遗传算法出发,凝聚了丰富多彩的调优思路,已经成为提升机器学习算法研发效率的利器。那么这些大多围绕着机器学习模型超参数优化的算法,是不是可以直接应用于比如系统软件配置和参数调优上来呢?答案是经典的 yes and no。
首先,经典的贝叶斯优化算法(基于高斯代理模型)及其衍生算法(如 TPE),当然是可以直接应用于系统参数调优的。但概括来说,这类算法整体的调优效率却经常无法满足无论是机器学习模型超参数调优还是系统参数调优。相应的,近年来的学术创新主要围绕着进一步提升调优的整体效率展开。也就是在这个层面上,机器学习模型超参数的调优和系统参数调优,走上了不同的道路。

(图1/条条调优路)
对于机器学习模型超参数调优来说,调优的时间开销主要来自两个方面:
(1)调优算法搜索策略所需要的运算耗时。
(2)机器学习模型训练的耗时。
对于近年来逐渐广为人知的基于高保真原理的优化算法,如 Successive Halving[1],HyperBand[2] 等,主要聚焦于减少第二个方面的时间开销,毕竟和训练动辄千万上亿级参数的模型,调优算法搜索策略的开销简直不值一提。幸运的事,机器学习模型训练的耗时确实是灵活可调整的。
然而,对于系统参数调优来说,虽然调优的时间开销也主要来自两个方面:
(1)调优算法搜索策略所需要的运算耗时。
(2)评估调优推荐参数配置的耗时。
但是其中(2)的耗时由于往往来自调用标准 benchmark 工具获得,是固定不可调整的。具体例子可以设想一下运行 Fio、SPEC CPU 2017 这类 benchmark 工具的过程。因此,针对系统参数调优的算法领域,无法通过优化(2)的开销曲线救国,只能老老实实的提升调优算法的搜索策略。到此,我们来到了第二个坑。

(图2/从满天星到一团火)
参数调优可谓是“维度灾难”的一个重灾区。基于贝叶斯优化框架的调优算法,本质上是在一个漆黑的空间中摸索,而随着维度的增加,这个漆黑的环境的 volume 急剧增大,摸索的时间成本的增加是不可避免的。对于机器学习模型超参数的调优来说,这个维度往往在十几到二十几这个量级,维度的铁拳仍然比较温柔。而对于系统参数调优来说,这个维度往往在几十到上百甚至过千的量级。在这个量级维度的铁拳下,经典的贝叶斯调优算法及其衍生算法,往往就会被锤成齑粉。以基于高斯代理模型的贝叶斯优化算法来说,我们可以比较粗糙的概括这种算法为**“散点”法**,这并不是说这类算法就是乱枪打鸟,毕竟有强大的贝叶斯原理作为引领,搜索的策略和路径还是有迹可循的。
然而,当维度足够高的时候,已经有相关研究证明,贝叶斯优化算法和随机搜索算法基本上是一对卧龙凤雏的存在[3]。因此,近年来 AI 领域顶会的学术成果,已经开始关注高维空间中的贝叶斯优化问题,由这种“散点”法,逐渐过渡到 “局域”法 [4,5]。这里“局域”又是我们的一个比较概括的说法,主要原理是在高维空间中,搜索主要被限制在于较小的局部区域进行,而各个局部区域本身的取舍依然服从贝叶斯原理。这类“局域”法有效的限制了搜索区域的 volume,因此往往有更高效的收敛和更好的调优效果。尤其是更好的收敛效果这种特性,对于系统参数的调优实践来说,可谓一定程度上减轻了燃眉之急,因为实际的系统参数调优实践,往往要考虑系统资源开销和整体时间限制,从而需要在尽可能少的调优轮次中给出最优或略低于最优的调优结果。当我们欣喜的准备吸取这些算法进入 KeenTune 去磨刀霍霍的时候,我们来到了第三个坑。
如前所述,当前主流的调优算法库或工具,往往围绕着机器学习模型超参数调优的场景进行扩展。因此如 Scikit-Optimize (skopt)[6] 和 NNI[7] 这类算法库,更多的聚焦于支持 Successive Halving 和 HyperBand 这些针对模型训练开销优化的算法,而对于解决高维贝叶斯优化问题的算法不够及时。此外,即使想在这些算法库中定制化实现这些算法,也依然需要详细的研读这些库中算法的实现,照猫画虎的在复杂的代码逻辑中前进,这种苦楚只能说懂得都懂。因此,当我们拔剑四顾的时候,刀鞘却阻碍了我们披巾斩棘的身影。至此,读者已经和我们来到了同样的境地,也看到那临门一脚的必选项 -- 打造更灵活通用的调优算法框架。
KeenOpt 的初心
当我们谈论参数调优算法框架的时候,我们谈论的是 :
(1)算法集成和定制化的方便快捷。
(2)算法的标准化和模块化。
围绕着这两个设计初心,我们的算法框架尽可能的将各个主要功能模块独立的抽象成类。
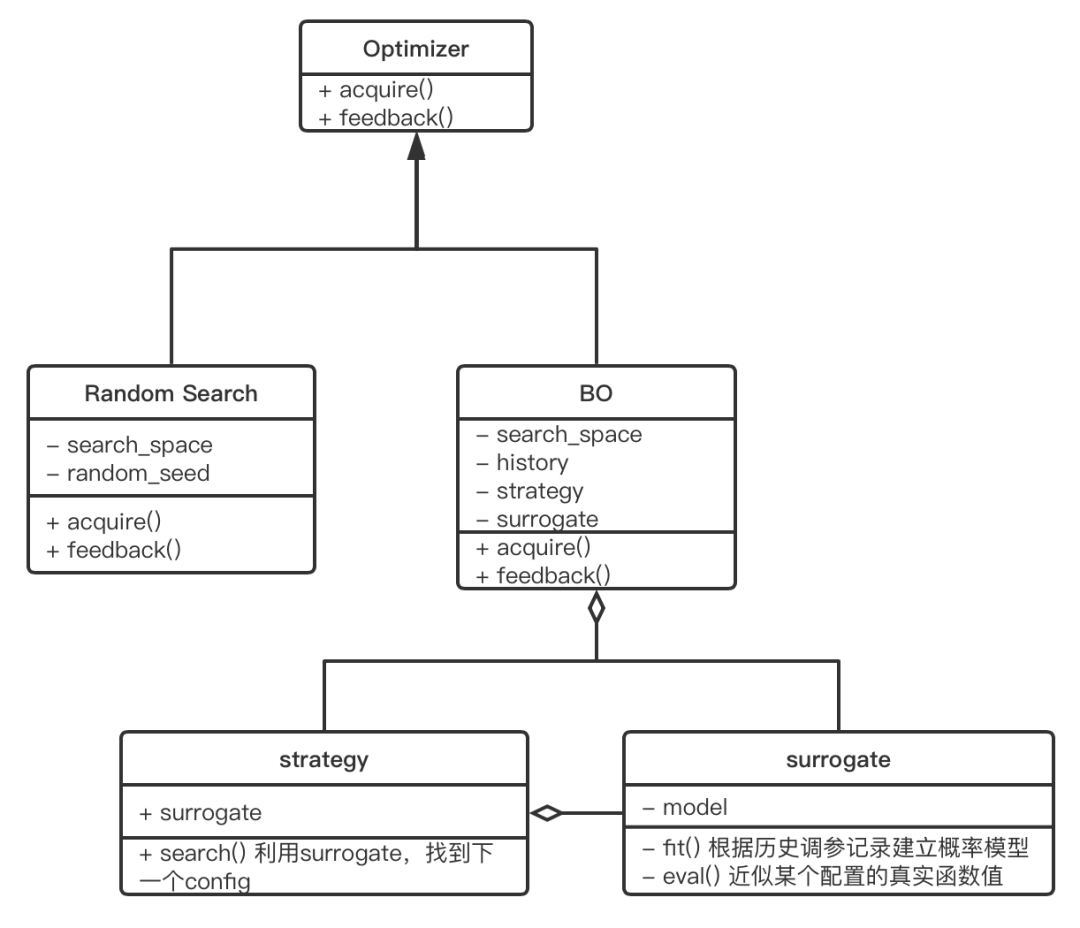
(图3/ KeenOpt框架概图)
如图 3 所示,自顶向下的从优化总体控制类,衍生出如随机和网格搜索的经典优化算法类,和基于贝叶斯优化的优化算法类。其中优化总体控制类,只要求提供 acquire() 和 feedback() 函数,分别负责选取参数和获得 benchmark 执行的反馈结果。其中针对贝叶斯优化的算法类,又进一步抽象出:
- 调优控制类: 提供贝叶斯优化必须依赖的接口参数。在最基础的优化类中,一定程度上实现了对于贝叶斯优化算法接口的标准化,包括参数空间,历史数据记录,代理模型,和搜索策略。
- **参数空间类:**参数空间可以灵活定义整型,浮点型,类别型的参数和其取值范围。由于实际的调优场景中,无可能出现真正意义上的连续参数空间,因此每个参数相应的还搭配了可定义的步长。
- **代理模型类:**代理模型的选择可以根据具体需要,灵活的选择经典回归类机器学习模型和基于 pytorch 实现的神经网络类模型。
- **搜索策略类:**具体的搜索策略可以实现经典的贝叶斯优化算法,也可以实现如上所述的“局域”搜索策略,整个类只要求实现具体的 search()方法。
下图 4 中展示了当前 KeenOpt 的支持的部分算法(TPE, LA-MCTS-Bo和LA-MCTS-TuRBO) 在 4 中常见的 synthetic 函数在低维(20)和高维(100)情况下的对比结果,可见“局域”算法确实比经典贝叶斯优化算法有更好的优化结果和更高的收敛效率。
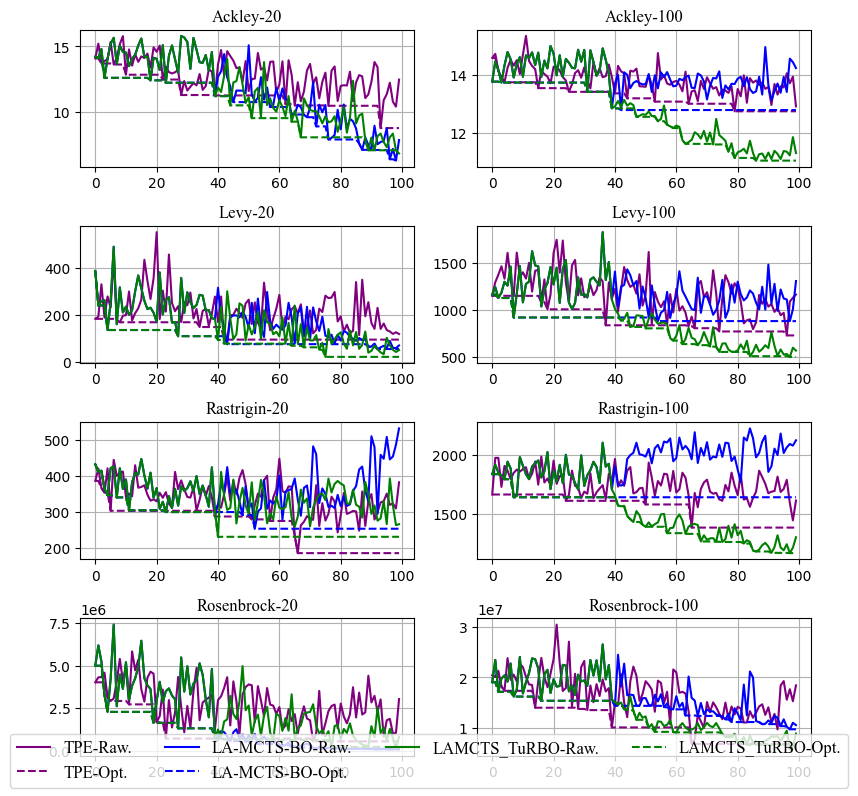
(图4/ KeenOpt支持算法效果对比)
后记
因为篇幅优先,带领大家走马观花的看一看 keenopt 的部分能力,今天的 KeenTune 旅行就先到此结束。具体详细信息及功能,请大家关注后续的 KeenOpt 的介绍,期待与各位开发者一起讨论交流。
近一年来,KeenTune 在龙蜥社区、阿里集团内外的项目中积极参与共建,在此期间,也遇到到了一起做项目的小伙伴,非常感谢能够一起并肩作战的大家,非常欢迎有更多的小伙伴参与 SIG 共建(SIG 地址见文末)。
keenopt 的仓库(链接见文末)也将近期基于keentune-brain进行更新,源码部分也在逐步的开放给大家。
有兴趣的小伙伴,欢迎加入我们 KeenTune SIG,这里汇聚了一群有想法有能力的小伙伴~(每双周周四上午11:00-12:00 是 KeenTune 的双周会,会议日程在龙蜥官网首页可以查看)。
相关链接地址:
KeenTune SIG地址:
https://openanolis.cn/sig/KeenTune
keenopt 仓库链接地址:
https://gitee.com/anolis/keentune_brain
龙蜥官网:
https://openanolis.cn/
引用
[1] Kevin G. Jamieson, Ameet Talwalkar: Non-stochastic Best Arm Identification and Hyperparameter Optimization. AISTATS2016: 240-248
[2] Lisha Li, Kevin G. Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, Ameet Talwalkar: Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. J. Mach. Learn. Res.18: 185:1-185:52 (2017)
[3] Marc-André Zöller , Marco F. Huber: Benchmark and Survey of Automated Machine Learning Frameworks. J. Artif. Intell. Res.70: 409-472 (2021)
, Marco F. Huber: Benchmark and Survey of Automated Machine Learning Frameworks. J. Artif. Intell. Res.70: 409-472 (2021)
[4] David Eriksson, Michael Pearce, Jacob R. Gardner, Ryan Turner, Matthias Poloczek: Scalable Global Optimization via Local Bayesian Optimization. NeurIPS2019: 5497-5508
[5] Linnan Wang, Rodrigo Fonseca, Yuandong Tian: Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search.NeurIPS2020
[6] https://scikit-opt.github.io/scikit-opt/#/
[7] https://nni.readthedocs.io/
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号





 16260
16260




 , Marco F. Huber: Benchmark and Survey of Automated Machine Learning Frameworks. J. Artif. Intell. Res.70: 409-472 (2021)
, Marco F. Huber: Benchmark and Survey of Automated Machine Learning Frameworks. J. Artif. Intell. Res.70: 409-472 (2021) 淘帖
淘帖






