Arm Streamline性能分析器提供系统性能指标、软件跟踪和统计分析,以帮助工程师从硬件中获得最大性能并找到软件中的重要瓶颈。
Streamline v7.4 增加了对用于 CPU、GPU 和 NPU 的 Arm NN 机器学习推理引擎的支持。Arm NN 弥合了现有框架和底层硬件之间的差距。Streamline 可以自动分析 Arm NN 应用程序并提供有关推理运行时的有用性能信息。
此处讨论的示例是在 Arm 上运行 ML 推理的 Linux 应用程序。我们之前已经在MNIST 数据集上训练了一个神经网络 来识别手写数字。使用Arm NN和 Streamline,我们希望了解我们模型的效率以及如何进一步优化它。
在应用程序中启用 Arm NN 分析
要在应用程序中启用 Streamline 分析,必须使用 Streamline 分析标志编译 Arm NN。这是使用定义完成的:
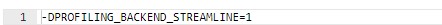
此外,对于使用分析的应用程序,它必须启用分析选项,通常在应用程序源代码中完成。在应用程序中启用 Arm NN 分析选项:
全屏

让我们看看如何启用分析并捕获在 N1 SDP上运行的应用程序的 Streamline 跟踪 并显示 ML 推理信息。
设置一个 ML 应用程序来分析
首先,我们将使用之前指定的定义选项构建 Gator、Arm Streamline 的分析代理、依赖库和 Arm NN。可以使用 github 上 Arm 工具解决方案存储库中的脚本之一轻松完成。安装所需的包并运行脚本以在 ${HOME}/armnn-devenv 中构建 Arm NN。

要安装 ML 应用程序,请转到以下存储库并编译示例:

我们已经添加了启用 Arm NN 分析的选项。我们现在准备使用 Gator 分析应用程序并连接 Streamline:
$ ~/gatord --app ./mnist_tf_convol 0 80
要在时间轴中可视化 Arm NN 事件,需要从计数器配置菜单中启用 Arm NN_Runtime 事件,以便 Gator 收集它们。请注意,应用程序需要先运行一次才能在菜单中看到这些事件,因为 Arm NN 需要计数和收集与 ML 相关的计数器以将它们传递给 Gator。此外,我们还启用了指令 PMU 以了解 SIMD 性能。
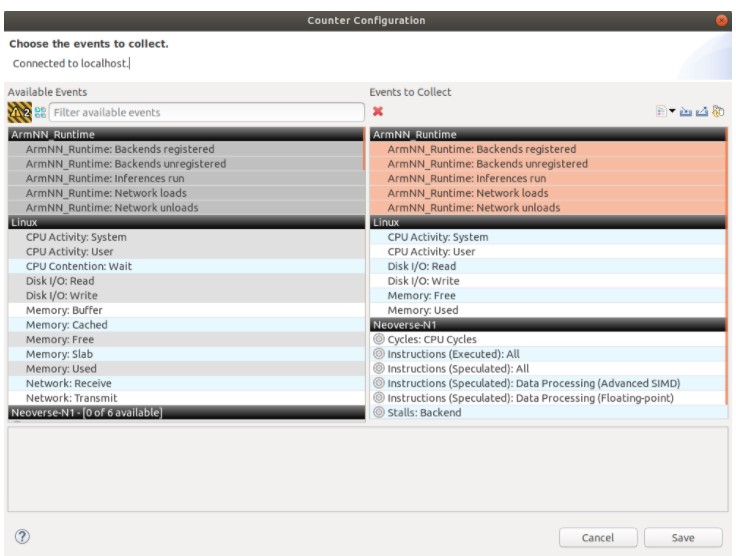
使用 Streamline 分析 Arm NN 活动
在 Streamline 中打开结果时,时间轴选项卡中会显示额外信息:
Arm NN_Runtime 图表显示后端注册(后端是将网络图的层映射到负责执行这些层的硬件的抽象:Arm Cortex-A、Mali-GPU 或 Arm ML 处理器)、网络负载和推论。此图表有助于监控推理,使用在许多后端运行的不同模型。在我们的示例中,我们在Neoverse N1 CPU上运行单个推理;
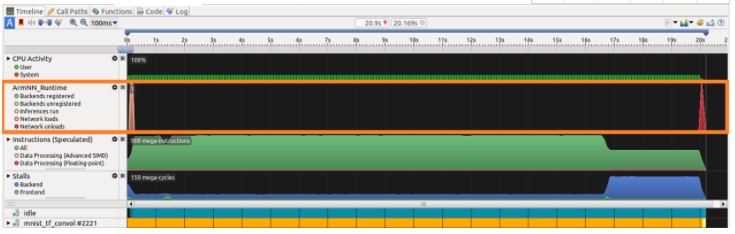
在时间轴视图的详细信息面板中
可以选择“Arm NN 时间线”以显示有关 NN 管道的信息。
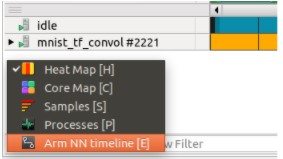
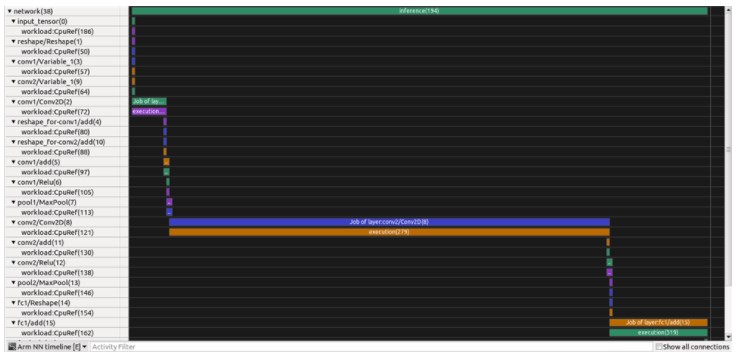
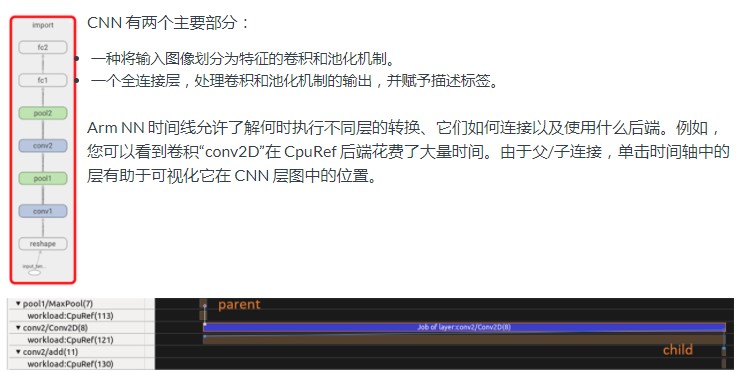
“Arm NN 时间线”显示神经网络的不同层——与Tensorboard可以显示的方式类似。在我们的案例中,我们训练了一个卷积神经网络(CNN),它在识别和分类用于计算机视觉的图像方面非常有效。
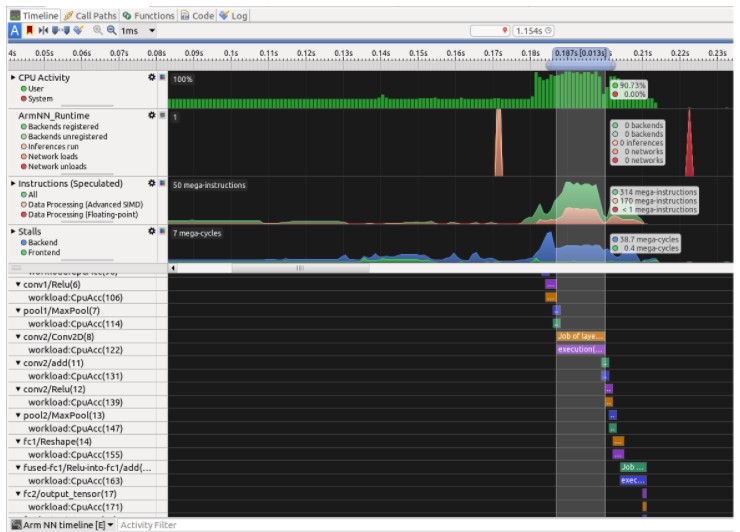
总结性能分析,配置文件表明应用程序没有利用所有 CPU 资源:
- CPU 活动平均为 25%——当 N1SDP 有 4 个内核时,推理仅在 1 个 N1 内核上运行;
- “高级 SIMD”指令非常少,尽管在执行卷积时会发出大量指令。该应用程序没有利用矢量化。
最大化 Arm NN 效率
在我们的示例中,将应用程序的第一个参数从 0 切换到 1 可以实现更快的应用程序版本:
$ ~/gatord --app ./mnist_tf_convol 1 80
此参数设置优化模式:0 使用可移植 CpuRef 模式,1 使用可在 Neoverse、Cortex-A 和一些 Cortex-R 处理器上工作的 CpuAcc 模式。
在 Streamline 中打开结果时,我们可以自然地将 PMU 指标与推理的不同步骤相关联。
我们可以看到,目标 CpuAcc 后端启用了高级 SIMD 指令以及多线程,以利用 Neoverse N1 CPU 上的所有计算资源。这导致了重要的加速,特别是对于卷积操作。
原作者:弗洛伦特·勒博
 /9
/9 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2154
2154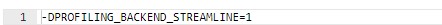









 淘帖
淘帖




