介绍
作为计算机视觉(CV)领域的关键应用之一,光学字符识别(OCR)旨在识别固定图像区域的文本内容。OCR已广泛应用于卡票信息提取与审核、制造产品追溯、电子政务医疗单证处理等诸多行业场景。文本识别是OCR 的子任务。它是OCR的两阶段算法中文本检测之后的下一步,可以将图像信息转换为文本信息。

图1 英文文本识别示例(图片来源:ICDAR2015)
在本博客中,我们将深度学习 (DL) 应用于 OCR 文本识别任务。我们将向您展示从模型训练到应用程序部署的端到端开发工作流程。您将学习如何:
1. 使用PaddleOCR获得经过训练的英文文本识别模型
2. 导出 Paddle 推理模型
3. 使用TVMC为目标设备编译 Paddle 推理模型4. 构建文本识别应用程序并将其部署在 Arm Virtual带有Arm Cortex-M55的硬件Corstone-300平台
该项目突出了 Arm 和百度之间的合作,填补了之前在 Arm Cortex-M 上直接部署 PaddlePaddle 模型的工作流程中的空白。这增加了Cortex-M 上支持的深度学习模型的数量,为开发人员提供了更多选择。
PP-OCRv3
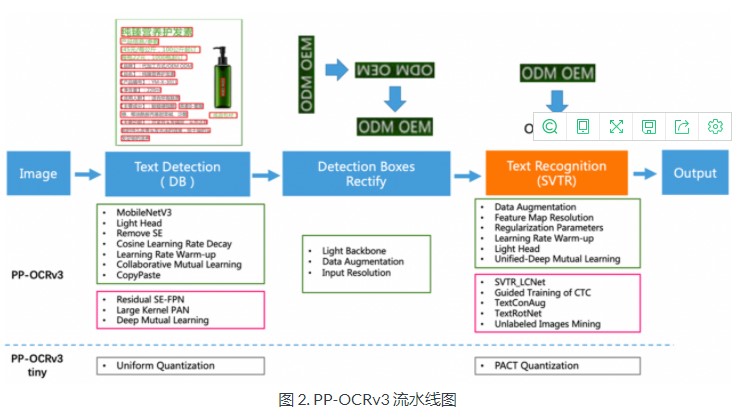
PaddleOCR 提供了一个名为 PP-OCR 的 OCR 系统。这是百度桨团队自主研发的一款实用的超轻量级OCR系统。它是一个两阶段的 OCR系统,其中文本检测算法称为DB,文本识别算法称为CRNN。如图 2 所示,PP-OCRv3 的整体流程类似于PP-OCRv2,但对检测模型和识别模型进行了一些进一步的优化。例如,文本识别模型引入了基于 PP-OCRv2 的SVTR (Scene Text Recognition with a Single Visual Model)。 该模型还使用GTC (CTC的引导训练)来指导训练和模型蒸馏。更多细节请参考这份PP-OCRv3技术报告.
Arm 虚拟硬件
作为 Arm 物联网整体解决方案核心技术的一部分,Arm 虚拟硬件 (AVH)提供可在云端部署的 Arm 设备虚拟模型。AVH
解决了物理硬件测试和开发面临的许多痛点。其中包括测试扩展困难、电路板测试场的高成本运维等。AVH提供了一种简单、方便且可扩展的方式,将物联网应用程序的开发从对物理硬件的依赖中解放出来。
它还使云原生技术(如持续集成/持续部署 (CI/CD) 和其他DevOps 方法)能够应用于嵌入式物联网和边缘/端点机器学习 (ML) 领域。尽管当前供应链紧缩,但使用 Arm虚拟硬件立即开始您的开发,无需等待硬件交付或访问,仍有许多优势。
目前,Arm 直接提供了两种访问 Arm 虚拟硬件的方式供开发者使用。一种是 Arm 虚拟硬件Corstone和Cortex CPU ,另一种是Arm 虚拟硬件 3rd-party 硬件。您可以在avh.arm.com上查看更多详细信息。在本博客中,我们使用 Arm 虚拟硬件 Corstone 和
Cortex CPU 介质,在 AWS 和 AWS 中国托管为亚马逊机器映像 (AMI)。
端到端工作流程
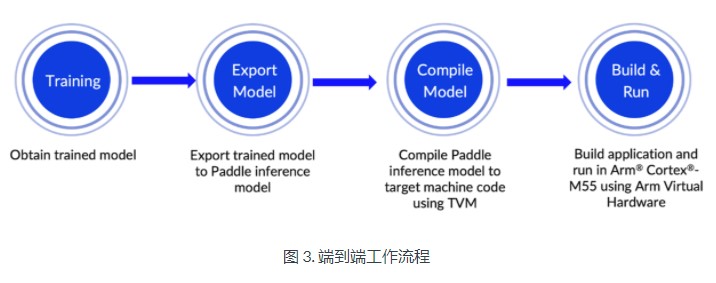
1.用PaddleOCR训练一个英文文本识别模型
PaddleOCR 提供了许多实用的 OCR 工具,可帮助您训练模型并将其应用到实践中。PaddleOCR 使用配置文件 (.yml)
来控制网络训练和评估参数。在配置文件中,您可以设置构建模型、优化器、损失函数以及模型前后处理的参数。PaddleOCR
从配置文件中读取这些参数,然后形成一个完整的训练过程,完成模型训练。微调也可以通过修改配置文件中的参数来完成,简单方便。有关更详细的描述,请参阅配置文件。
要获得适应 Cortex-M 的训练模型,我们必须修改用于模型训练的配置文件。删除了不受支持的运算符,例如LSTM。为了优化模型,我们在模型调整阶段使用BDA(基础数据增强)。这包括多种基本数据增强方法,例如随机裁剪、随机模糊、随机噪声和图像反转。在开始之前,您必须先安装 PaddleOCR 工具。

您可以使用 PaddleOCR 通过以下命令验证推理模型。训练模型通常需要一些时间。

2.导出Paddle推理模型
我们必须将经过训练的文本识别模型导出到 Paddle 推理模型中,我们可以对其进行编译以生成适合在 Cortex-M
处理器上运行的代码。使用以下命令导出 Paddle 推理模型:

您可以使用 PaddleOCR 通过以下命令验证推理模型。训练模型通常需要一些时间。

我们使用图 4作为可用于验证推理结果的图像类型的单个示例。识别结果如下图所示。与图文内容“QBHOUSE”一致,置信度高,0.9867左右。这表明我们的推理模型已为下一步做好准备。
全屏1path_to_word_116.png 的预测:(‘QBHOUSE’, 0.9867456555366516)
3.用TVMC编译Paddle推理模型
我们使用深度学习编译器TVM 进行模型转换和适配。TVM
是一个开源的深度学习编译器。它主要用于解决在广泛的硬件目标上部署各种深度学习框架的适应性问题。如图 5 所示,TVM 编译器接受由经典深度学习训练框架(如PaddlePaddle)编写的模型。然后将这些模型转换为可以在目标设备上运行推理任务的代码。
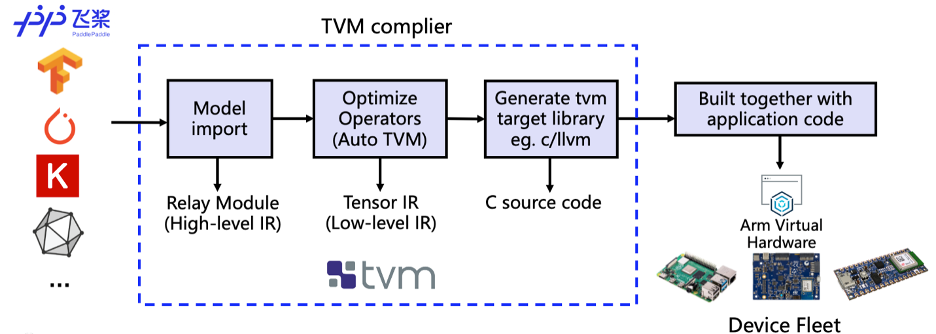
图 5. 编译过程示意图
我们使用 TVM 的 Python 应用程序 TVMC 来编译模型。您可以使用以下命令编译 Paddle推理模型。通过指定--target=cmsis-nn,c,Arm CMSIS-NN 库支持的运算符将被卸载到 CMSIS-NN 内核。它可以充分利用底层 Arm硬件加速。否则,它会退回到标准 C库实现。通过指定--target-cmsis-nn-mcpu=cortex-m55和--target-c-mcpu=cortex-m55,它编译适合在Cortex-M55 处理器上运行的代码。有关每个参数的更具体说明,您可以在安装 TVM Python 包后使用命令tvmc compile --help。
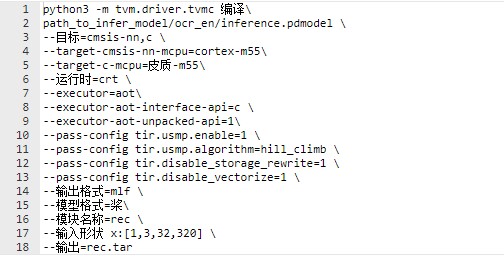
编译后,模型文件可以在参数--output指定的目录下找到。在此示例中,它最终出现在当前目录中名为 rec.tar 的文件中。
4. 部署在带有 Arm Cortex-M55 的 AVH Corstone-300 平台上
使用 ssh 命令连接到您之前启动的 AVH AMI 实例,您可以看到下面的终端界面。它表明您已经成功登录。
图 6. 成功登录页面
1-3中描述的模型训练、导出和编译步骤可以在本地机器上完成,也可以在AVH AMI环境中完成。根据自己的需要确定。可以从命令行运行的完整示例代码可从PaddleOCR 的 GitHub 存储库(在 dygraph 分支下)下载。这使开发人员更容易体验整个工作流程,尤其是部署。
成功连接 AVH AMI 实例后,您可以使用以下命令完成模型部署并查看应用执行结果。
run_demo.sh脚本自动化了我们刚刚描述的整个过程。它通过以下 6 个步骤帮助您在 Corstone-300 平台上使用 Arm
虚拟硬件自动构建和执行英文文本识别应用程序。
Step 1. 设置运行环境
Step 2. 下载 PaddlePaddle 推理模型
Step 3. 使用 TVMC 编译模型并为 Arm Cortex-M 处理器生成代码
Step 4. 构建应用程序映像的处理资源
Step 5. 使用 Makefile构建目标应用程序
步骤 6. 在集成在 AVH 中的 Corstone-300 平台上运行应用程序二进制文件
我们可以以上图 4 中的图像(QBHOUSE)为例,在 AVH Corstone-300 平台上使用 Arm Cortex-M55验证推理结果。结果如图7所示,与服务器主机直接推理的推理结果高度一致。这表明我们已经成功地直接在 Arm Cortex-M 上部署了 PP-OCRv3
英文识别模型。
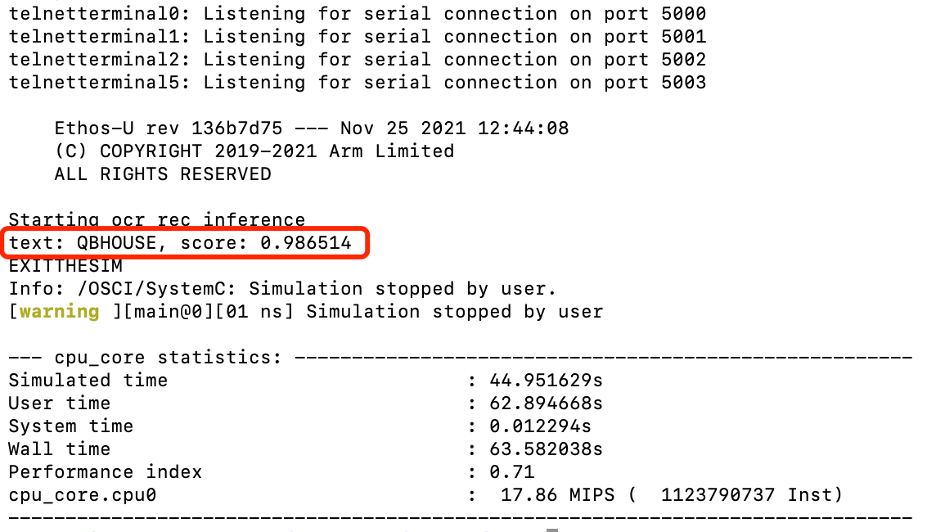
图 7. 带有 Cortex-M55 推理结果的 AVH Corstone-300
结论
在这篇博客中,我们向您展示了如何在 AVH Corstone-300 平台上部署 PP-OCRv3 中发布的英文文本识别模型,并使用Cortex-M55。
原作者:Liliya Wu
 /7
/7 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2637
2637










 淘帖
淘帖






