机器学习 (ML) 是云和边缘基础设施中增长最快的部分之一。在 ML 中,深度学习推理预计会增长得更快。
在本博客中,我们比较了三种 Amazon Web Services (AWS) EC2 云实例类型在运行两种常见的 FP32 ML 模型时的 ML 推理性能。我们将在以后的博客中介绍量化推理 (INT8) 的性能。
工作负载
[MLCommons]在其[MLPerf 推理基准套件]中提供了代表性的 ML 工作负载。MLCommons 是一个开放的工程联盟,通过基准、指标、数据集和最佳实践来支持和改进机器学习行业。
在此分析中,我们为两个广泛使用的 ML 用例(图像分类和语言处理)运行了基准模型:
| 区域 |
任务 |
模型 |
| 想象 |
图像分类 |
Resnet50-v1.5 |
| 语 |
自然语言处理 |
BERT-大 |
平台
我们在三种 AWS EC2 云实例类型上运行,涵盖两代 Arm Neoverse 内核(Arm Neoverse N1 和 V1)和最新的 Intel Xeon CPU(第三代 Intel Xeon Scalable Processor)。
| AWS 实例类型 |
中央处理器 |
配置 |
| c6g |
手臂 Neoverse N1 |
4xlarge (16-vCPU) |
| c7g |
Arm Neoverse V1 |
4xlarge (16-vCPU) |
| c6i |
第三^代^英特尔至强可扩展处理器 |
4xlarge (16-vCPU) |
AWS Graviton3 (c7g) 与 AWS Graviton2 (c6g) 的性能特点
AWS Graviton3 (c7g) 引入了 Arm Neoverse V1 CPU,与 AWS Graviton2 (c6g) 中的 Arm Neoverse N1 相比,带来了两大 ML 相关升级: (1) BFloat16 支持;(2) 更宽的向量单位
BFloat16 支持
BFloat16 或 BF16 是一种 16 位浮点存储格式,具有 1 个符号位、8 个指数位和 7 个尾数位。它具有与行业标准 IEEE 32 位浮点格式相同的指数位数,但精度较低。
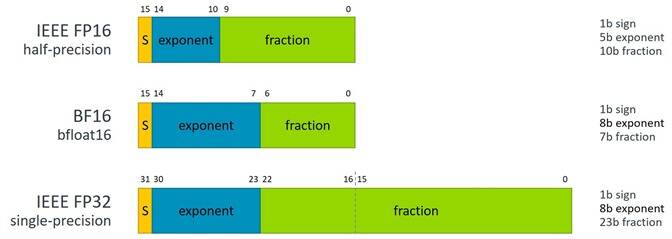
图 1:BFloat16 与 IEEE 754 单精度和半精度的比较。
BF16 非常适合加速深度学习矩阵乘法运算,其中使用 BF16 浮点数格式进行乘法运算并使用 32 位 IEEE 浮点数进行累加。
[Arm 在2019 年 Arm 架构更新]中引入了新的 BF16 指令,以提高 ML 训练和推理工作负载性能。Neoverse V1 是第一个支持这些 BF16 指令的 Neoverse 内核。
更宽的向量单位
Neoverse V1 还具有更宽的矢量单元,每个内核有两个 256 位 SVE 单元,而 Neoverse N1 则有两个 128 位 NEON 单元。
软件堆栈
对于所有平台,我们都使用了 TensorFlow v2.9.1 包。
Arm 上的 TensorFlow 软件堆栈
Arm 上的 TensorFlow 包支持两种不同的后端——Eigen 后端(默认启用)和更快的 oneDNN 后端。
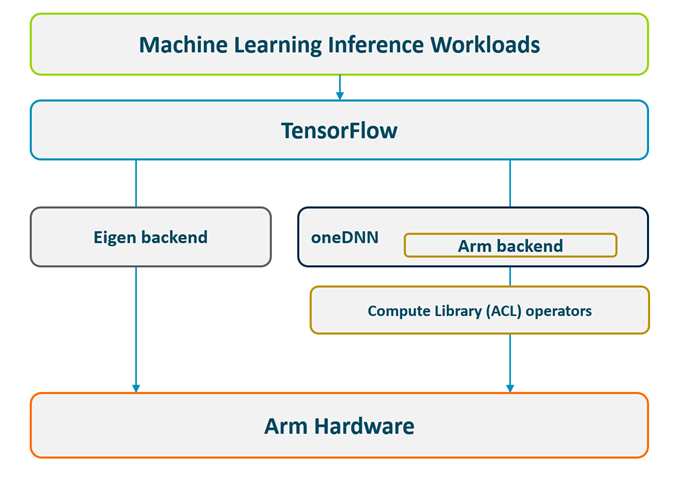
图 2:具有两个后端(Eigen 和 oneDNN/ACL)的 Arm 上的 TensorFlow 软件堆栈。
oneAPI 深度神经网络库 ( [oneDNN] ) 是一个开源的跨平台性能库,包含用于深度学习应用的基本构建块。该库以前称为 MKL-DNN,已与 TensorFlow、PyTorch 和其他框架集成。[Compute Library (ACL)]是一个 Arm 优化库,具有 100 多个优化的机器学习函数,包括多种卷积算法。Arm 已将 ACL 与 oneDNN 集成,因此框架可以在 Arm 内核上运行得更快。
我们使用 AWS 构建的 TensorFlow v2.9.1 包 进行此基准测试。我们设置了两个额外的环境变量 (1) 来启用 oneDNN ( TF_ENABLE_ONEDNN_OPTS=1) 和 (2) 使用 BF16 来加速 FP32 模型推理 ( ONEDNN_DEFAULT_FPMATH_MODE=BF16)。
对于未来的版本(从 2.10 版开始),AWS、Arm、Linaro 和 Google 正在共同努力,通过为 Arm 提供 TensorFlow 包。
x86 上的 TensorFlow 软件堆栈
对于 x86,我们使用了官方的 TensorFlow v2.9.1 包,其中默认使用 oneDNN。
AWS Graviton3 (c7g) 与 AWS Graviton2 (c6g) 的性能比较
与 AWS Graviton2 (c6g) 中的 Neoverse-N1 相比,AWS Graviton3 (c7g) 中的 Neoverse-V1 具有更宽的向量单元和新的 BF16 指令,进一步提高了机器学习性能。
在下图中,我们看到 AWS c7g(带有 Neoverse-V1)的实时推理性能优于 AWS c6g(带有Neoverse -N1)2.2 倍的RESNET ****-50和2.4 倍的BERT-Large 。
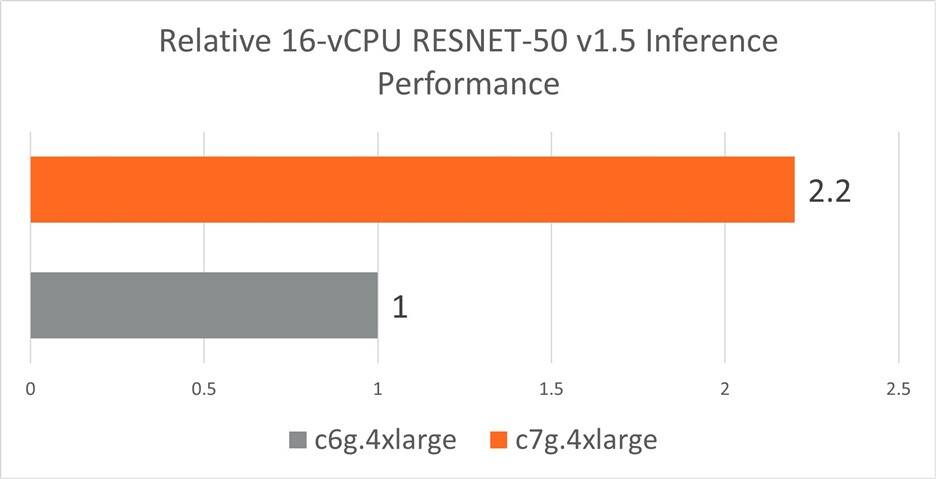
图 3:具有 AWS Graviton3 处理器的 c7g.4xlarge 实例集群和具有 AWS Graviton2 处理器的 c6g.4xlarge 实例集群实现的 Resnet-50 v1.5 实时推理性能(批量大小 = 1)。越高越好。
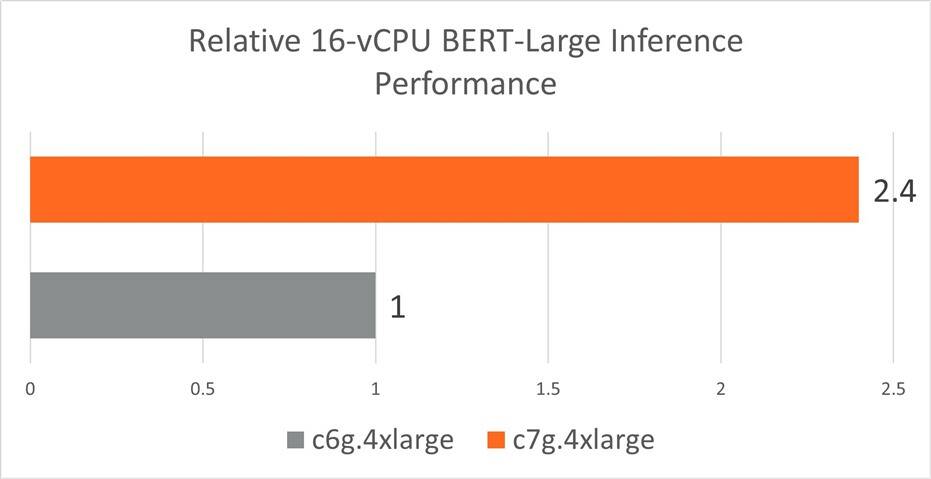
图 4:使用 AWS Graviton3 处理器的 c7g.4xlarge 实例集群和使用 AWS Graviton2 处理器的 c6g.4xlarge 实例集群实现的 BERT-Large 实时推理性能。越高越好。
AWS Graviton3 (c7g) 与 AWS Intel Ice Lake (c6i) 的性能比较
以下图表总结了 AWS Graviton3 (c7g) 与 AWS Intel Ice Lake (c6i) 平台的性能。
总之,对于BERT-Large, AWS c7g(基于 Arm Neoverse V1)的性能比 c6i(基于 Intel Ice Lake x86)高 1.8 倍 ,对于RESNET-50 FP32 模型高1.3 倍。这主要是由于 c7g 中 BF16 指令的可用性,而当前 c6i 一代中缺少这些指令。
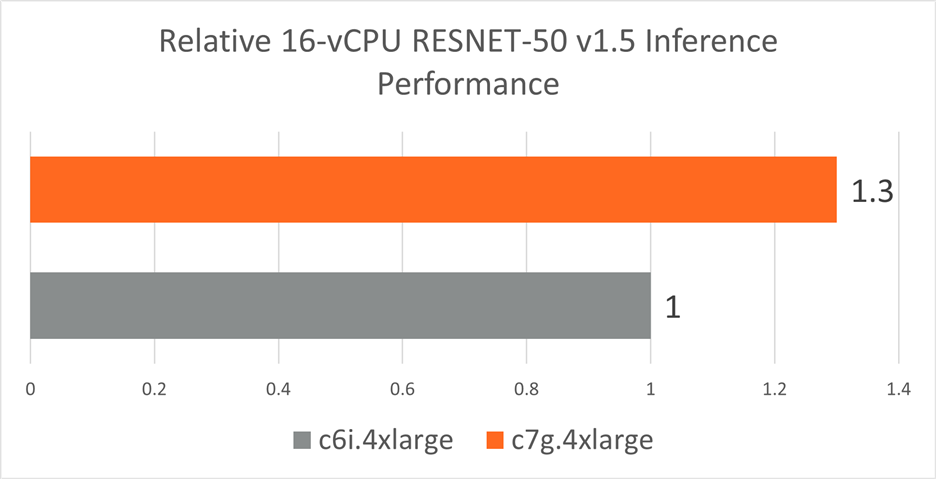
图 5:具有 AWS Graviton3 处理器的 c7g.4xlarge 实例集群和具有第三代 Intel Xeon 可扩展处理器的 c6i.4xlarge 实例集群实现的 Resnet-50 v1.5 实时推理性能(批量大小 = 1)。越高越好。
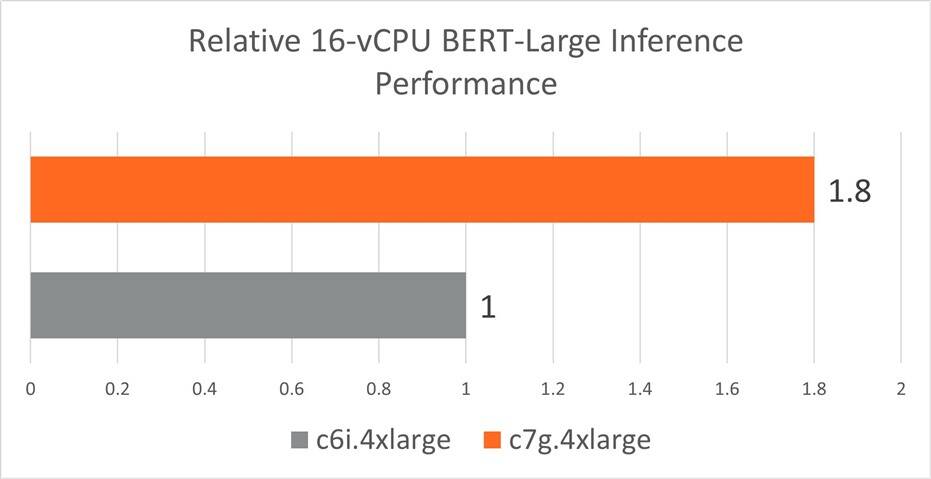
图 6:使用 AWS Graviton3 处理器的 c7g.4xlarge 实例集群和使用第三代 Intel Xeon 可扩展处理器的 c6i.4xlarge 实例集群实现的 BERT-Large 实时推理性能。越高越好。
结论
我们的 MLPerf BERT-large 和 Resnet50-v1.5 基准分析表明,Amazon EC2 c7g实例(使用 Arm Neoverse V1 CPU)比 Amazon EC2 c6i实例(使用 Intel Ice Lake CPU)快 1.8 倍,快2.4倍比 Amazon EC2 c6g实例(使用 Arm Neoverse N1 CPU)。
这是由于 Neoverse V1 中改进的硬件功能(新的 BF16 指令和更宽的向量单元)和改进的软件堆栈(其中 ACL 使用 BF16 加速 FP32 ML 操作)的组合。通过在基于 Graviton3 的实例上运行 FP32 ML 模型推理,与 x86 架构实例相比,消费者可以从提供的更低的每小时价格中进一步受益。
原作者:Ashok Bhat
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 3355
3355





 淘帖
淘帖





