根据不同的arm CPU构架,可以用不同的方式来实现spinlock.
基于load-exclusive/store-exclusive(也是load linked, store conditional)这种retry机制的atomic操作实现的spinlock.
基于1同等方式,改进的ticket spinlock。
基于armv8.1-a LSE atomic机制的spinlock.
queued spinlock.
不同的机制会有不同的CPU获取到锁的公平性问题。为了得到比较直观感受,我写了一个test application,在big.LITTLE的A53+A73的平台,和在一个Neoverse N1的平台(因为N1支持armv8.1-a LSE)上运行,得到基于1,2,3机制的锁的机会数据。
这个测试程序创建两个线程,分别分配到不同的CPU核上运行,线程做的主要事情是获取一个锁,然后对一个锁保护的共享变量加1,并记录是哪个CPU加的,等这个变量加到一个特定数字时停下来,然后分析每个CPU加的次数,以此获得每个CPU获得到锁的次数。
测试结果
先贴出结果,
在big.LITTLE的A53+A73的平台上(因为不支持armv8.1 LSE, 所以只测1, 2)
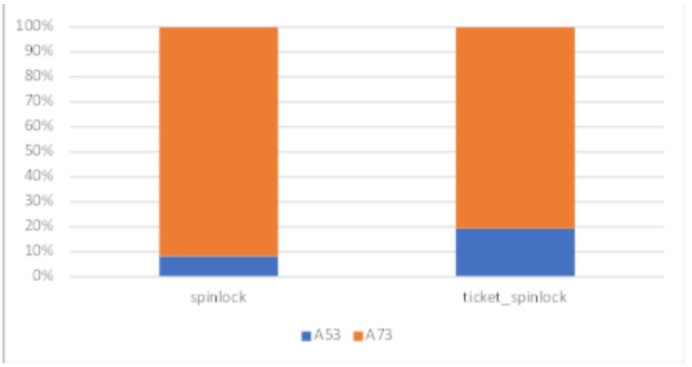
在这个平台上A53是小核,有比A73更低的频率和性能。
可以看出,基于1的spinlock测试,A53能获取到锁的概率大致为8%,A73得到了90%以上获取到锁的概率。基于2的ticket spinlock可以改善A53获取到锁的概率到20%。主要是因为A53+A73+CCI的设计,对锁的访问因为MESI一致性协议的latency和在local cache里面做store-exclusive要比先通过MESI从别的CPU snoop过来然后再store-exclusive要快的原因。
在N1的平台的结果:

在这个平台上N1 CPU 通过mesh互联网络连接,他们在系统中硬件上处于同等的地位,频率和性能都是一样的。但是可以看出,还是由于在local cache里面做store-exclusive要比先通过MESI从别的CPU snoop过来然后再store-exclusive要快的原因,基于1的spinlock,N1 CPU0, 有80%的概率获得锁,基于ticket spinlock的测试中,CPU0有45%的概率获得到锁。基本上那个CPU首先获得到锁,后面更有机会获取到锁。基于3的测试中,因为采用了直接的atomic指令而不是1,2采用的retry的load-exclusive/store-exclusive atomic方式,所以没有MESI协议的ping-pong效应,公平性较好,基本上50%.
近水楼台先得月和MESI乒乓
为了解释公平性其中的原因,需要理解MESI cache一致性协议和load-exclusive/store-exclusive,armv8.1-a LSE atomic实现spinlock的原理,这方面的文章非常多,就不多费口舌。
简单用几个图来说明MESI协议:
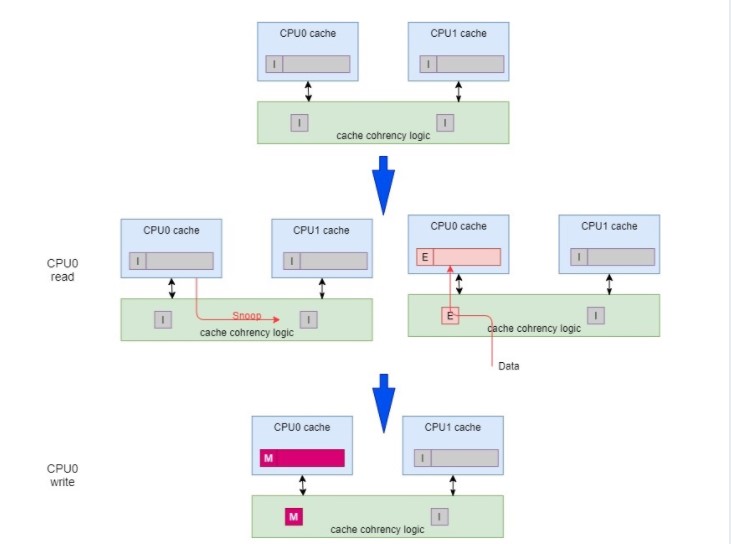
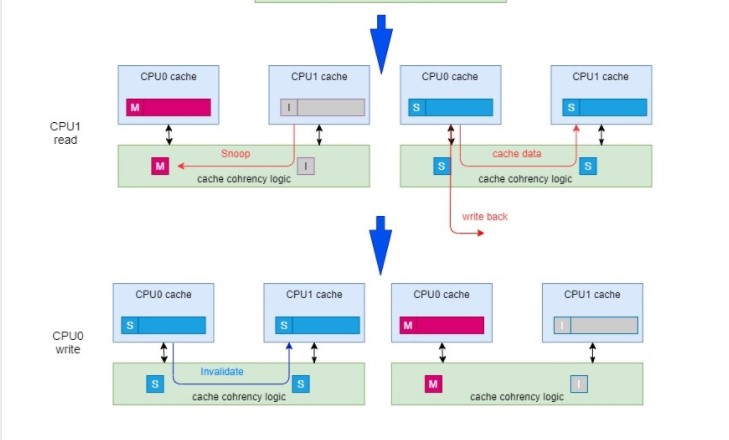
由图中可以看出,当在某个CPU的cache line处于MESI中的M,E状态时(表示这个数据只在这个CPU cache line有,其他CPU里没有),对这个cache line里面的数据的写,不是需要snoop,比较快速。
考虑到跨CPU cluster的MESI,完成snoop的过程会更长。
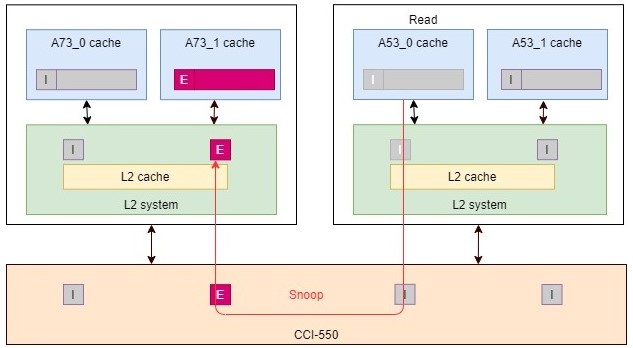
如果CPU比其他CPU慢,那么它发出的snoopable的访问需要在cache coherency logic(可以是L2 memory system或是CCI的PoS点)序列化排队时靠后。
再简单用一个图来表示基于1的spinlock的过程:
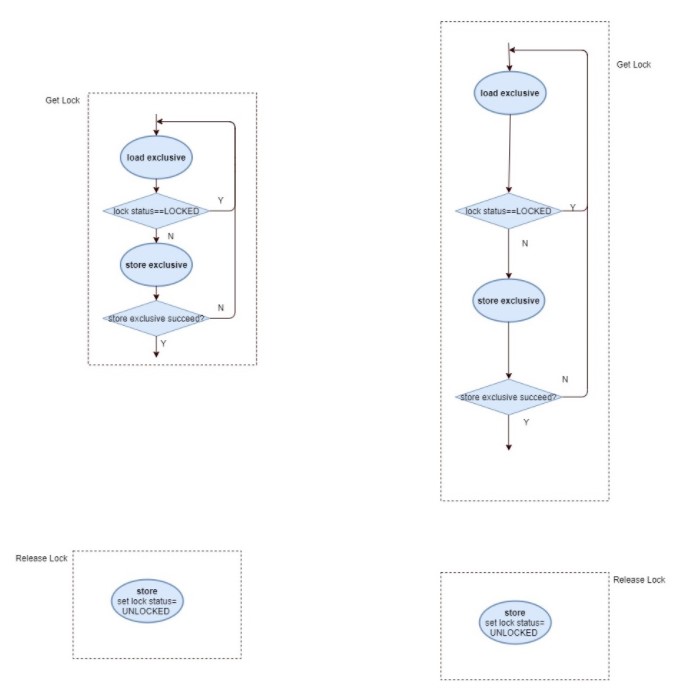
结合MESI协议来分析这个2 CPU循环抢锁的test application,
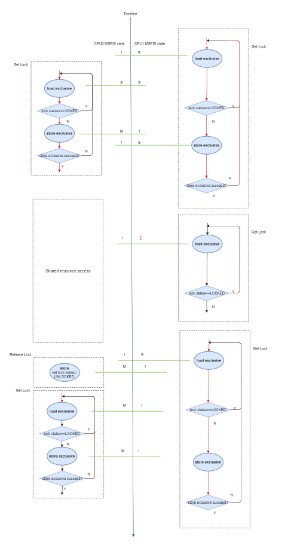
可以看出,即使是慢的CPU1先load-exclusive, 快的CPU0也可以先store-exclusive这个锁, 从而先获取到锁。
更重要的是,但CPU0 release这个锁的时候,做正常的store操作,会把cacheline变成是独占的M状态,然后在这个测试中CPU0又马上开始获取lock的过程,这时CPU0相当于近水楼台,它比要通过MESI snoop过程的CPU1有更多的机会再次获取到锁。
这个类似于去没有排号系统的餐馆吃饭,顾客都去抢桌子,没抢到桌子的顾客都在餐馆外面等着。但是如果吃完的顾客,刚离开桌子,马上又去抢桌子,外面的人或许还没来得及跑进来,那么他会有更多的机会抢到。
而ticket spinlock类似于有排号系统的餐馆,顾客去了先抢排队的号码,虽然大家一起抢号码还是快的人先抢到,但是在吃饭的顾客是不会和其他人竞争拿号码,吃完了需要再去拿新的号码。大家都是等号码轮上了才去吃。在一定程度上改善了公平性。
而基于armv8.1-a LSE的spinlock对lock的read-modify-write操作本身是原子的,不会发生load exclusive 到store exclusive中间被抢的情况,可以有较好的公平性。
原作者:修志龙_ZenonXiu
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2033
2033






 淘帖
淘帖





