多线程并发有两个主要特性
同步带来的开销,比如,锁固有的序列化
编程,调试和验证的难易程度
当采用不同的同步策列,比如粗粒度锁, 细粒度锁和 lock-free算法时,以上两个属性经常呈负相关性。
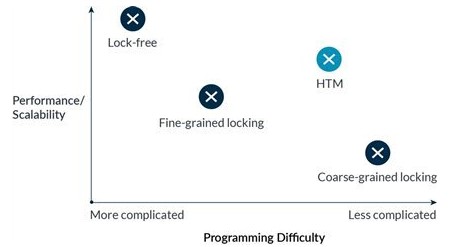
图一: 达到更高性能/可伸缩的并发通常以增加编程难度为代价
Hardware Transactional Memory (HTM) 可以让两个或更多线程安全地在关键段中并行执行-也叫 transactions, 这不需要使用 Mutex这样的序列化原语。Transactions有原子性,一贯性和隔离性的属性,Transactions推测性地执行( Harris,et al., 2007), 微构架负责检测竞争,比如,一个线程写一个内存地址,另一个线程读这个内存地址,并从竞争条件恢复原来状态。HTM使用更简单的编程模型方式增加并行性。
Arm TME
Transactional Memory Extension (TME)是arm A-profile 将来构架技术计划的一部分。TME是best try(尽最大努力)的HTM构架,它不能保证transaction的完成。程序员必须提供fallback的路径来保证可以继续,比如使用mutex的关键段。它提供强隔离性,意味着一个transaction和另一个transaction,一个transaction和另一个并发的非transactional的内存访问,它们相互隔离。它采用transaction的扁平嵌套,将被嵌套的transactions归入 outer transaction。被嵌套的transactions的效果不会被其他观测者观测到,直到 outer transaction commit了。当一个被嵌套的transaction失败了,它也导致outer transaction(和包含其中的所有被嵌套transaction)失败。
TME包含4条指令:
TSTART - 这条指令开始一个新的transaction。 如果这个transaction成功开始,目标寄存器Xd被设置为0,处理器进入transactional 状态。如果transactional失败或是取消,那么在transaction里面所有被修改的状态都被丢弃。目标寄存器被设置为失败原因编码的非零值。
TCOMMIT – 这条指令提交当前的transaction。如果当前的transaction是outer transaction,那么退出transactional状态,在transaction里面所有被修改的状态提交为构架状态,修改对其他观察者可见。
TCANCEL # - 这条指令退出transactional状态,放弃transaction里面所有的修改,执行outer transaction中TSTART后面的一条指令,目标寄存器Xd里面包含TCANCEL指令中的#imm立即数。
TTEST - 这条指令将transaction的深度(嵌套数)写到目标寄存器,如果处理器不在transactional状态,则写0.
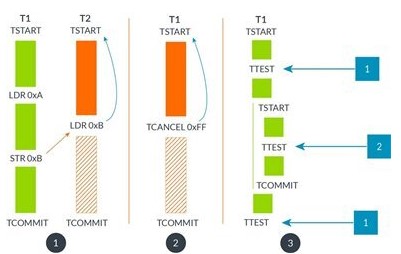
图二 呈现TME四条指令的场景
呈现2线程创建和提交transactions。 线程T1和线程T2冲突,因此线程T2终止它的transaction并roll back到TSTART指令(译者:应为TSTART后面的一条指令)。 T2的 TCOMMIT指令永远不会被执行。
呈现线程T1创建了一个transaction但手动地采用TCANCEL指令终止transaction,transaction终止并roll back到TSTART指令(译者:应为TSTART后面的一条指令),TCOMMIT指令永远不会被执行
呈现线程T1创建和提交一个嵌套的transaction,在嵌套的transaction中测试transaction的深度。当在outer transaction中的TTEST执行时,它返回值为1, 而在inner transaction中的TTEST返回值为2
在gem5里建模TME
gem5是一个开源的系统和处理器模拟器,它广泛地使用在计算机构架研究学术和产业界。 gem5提供了两种内存系统- 经典和Ruby。
在经典内存系统是从 gem5的前身 M5继承过来的,实现了 MOESI一致性协议。相反, Ruby内存系统提供了定义和模拟定制的cache一致性协议的灵活方法,包括一序列的互联和技术。协议是通过状态,transitions,事件 和actions,采用domain-specific语言,SLICC (specification language including cache coherence)来定义。
gem5包含各种可用的 Ruby cache一致性协议,但是,目前没有一种协议支持HTM。
HTM可以通过各种带trade-offs的方式实现。为了建立arm TME原型,我们选择了在处理器中实现指令集扩展的特殊方法。简单地说,它采用了以cache line为粒度的lazy version管理和eager conflict 检测方法。其他的实现方式是可能的,为gem5设计的选择不一定反映了现有的或是将来的芯片实现。
TME要求实现必须
Checkpointh和恢复architectural寄存器状态
追踪transactionally的读和写状态
缓存推测性的内存更新
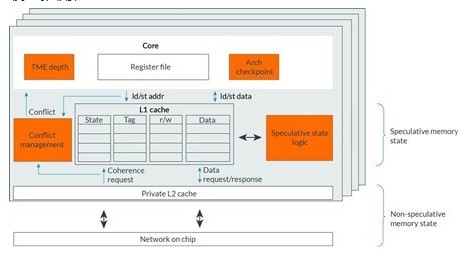
图三: 橙色框部分是微构架为了支持TME增加/修改的组件
有很多技术可以用来做register checkpoint, 包括影子register file和冻结physical registers. 在 gem5中,我们优化了一个功能正确的 checkpointing机制,而且没有开销,也就是 0 cylce的即时整个 register file的备份。这使得我们可以在core model之间共享一个通用的checkpointing机制。
为了从HTM支持区分TME特有的功能(译者:arm TME是计算机构架HTM的一种实现),在srcarch目录下增加了一个checkpoint和恢复的通用接口。指令集可以根据它们的特殊需求实现这个接口,这让HTM功能可以被共享和再次利用。TME实现必须可以roll back构架状态,在transaction失败或是取消时丢弃推测性的更新。这可以通过重用 gem5的异常机制来实现。
为了追踪一个transaction 读/写集合和缓存推测性的内存更新,我们借用cache一致性协议。 gem5 包括 Ruby协议MESI_Three_Level. MESI是指一个cache line可以所处的状态: Modifed,exclusive, Shared 或Invalid。 这个协议利用私有的 L1数据和指令cache, 它们的内容来自一个更大inclusive的私有L2 cache。 L2 cache后面有一个更大的inclusive的共享L3 cache和一致性目录(coherence directory)。
在MESI_Three_Level协议上增加TME的支持。L1 数据cache用来缓存和系统其他部分隔离的推测性状态。因为L2 cache是inclusive的,它包含相同的transaction 读/写集合的cache lines,但是它也保持了transaction之前的值。这种配置的结果是,一个transaction的working集合必须仅仅存在于L1数据cache。如果一个transactionally的读或写cache line溢出,也就是从L1 data cache evict到L2 cache,那么这个transaction必须失败中断,所有推测性写的数据必须丢弃。
为了追踪transactionally的读写状态,两个额外的bit加入到每个L1数据cache line的tag里。 1 bit表示这个cache line在 transaction读集合,另一个bit表示这个cache line在 transaction写集合。
这些bits在从一个cache line状态转换为另一个状态时使用。在提交(commit)一个transaction时,这两个bit都被清除。在终止(abort)一个transaction时,如果一个cache line时modified状态同时在transaction写集合里,那么状态转换为invalid,这2个bits被清零。我们假设2 bits可以被自动清零,这样对外部的观察者来说,可以观察到所有的transactional状态的提交(变成非推测性状态),或都被丢弃然后roll back。 这样可以满足transactional内存的原子性属性。
编程例子
为了测试gem5的这个新功能,我们用C写了一个简单程序,它使用TME transactions来并行更新一个直方图。这个程序使用手工的 lock elision- 用一个lock用来保护共享数据结构,但是当有可能使用transaction的情况下,就不用使用这个lock,也就是这个lock被bypass或elided(省略)。lock满足当一个transaction不能继续的时候需要一个fallback路径的要求。
我们首先定义一个符合AArch64 weak memory model的简单spinlock
#include <stdatomic.h>
typedef atomic_int lock_t;
inline void lock_init(lock_t *lock) {
atomic_init(lock, 0);
}
inline void lock_acquire(lock_t *lock) {
while (atomic_exchange_explicit(lock, 1, memory_order_acquire))
;
}
inline int lock_is_acquired(lock_t *lock) {
return atomic_load_explicit(lock, memory_order_acquire);
}
inline void lock_release(lock_t *lock) {
atomic_store_explicit(lock, 0, memory_order_release);
}
然后,我们用TME transaction写一个bypass/省略lock的功能。如果lock成功被省略,lock_acquire_elided返回1,否则返回0. 这个函数开始一个新的transaction并检查这个lock是否还是 free的,这时把这个锁加入到transaction的读集合中。如果这个锁不是free的,这个transaction显示地被TCANCEL指令终止。那个_TMFAILURE_RTRY 在我们的例子里不重要,但是,用来设置MSB保证transaction可以被重试。
#include <arm_acle.h>
#define TME_MAX_RETRIES 3
#define TME_LOCK_IS_ACQUIRED 65535
int lock_acquire_elided(lock_t *lock) {
int num_retries = 0;
uint64_t status;
do {
status = __tstart();
if (status == 0) {
if (lock_is_acquired(lock)) {
__tcancel(TME_LOCK_IS_ACQUIRED);
__builtin_unreachable();
}
return 1;
}
++num_retries;
} while ((status & _TMFAILURE_RTRY) && (num_retries < TME_MAX_RETRIES));
return 0;
}
void lock_release_elided() {
__tcommit();
}
这个spinlock+transaction路径然后用来创建work函数,它用来更新全局共享数组结构。这个函数可以并行被多线程调用。
#include <stdio.h>
#include <stdlib.h>
#include "lock.h"
#define ARRAYSIZE 512
#define ITERATIONS 10000
volatile long int histogram[ARRAYSIZE];
lock_t global_lock;
void* work(void* void_ptr) {
// Use thread id for RNG seed,
// this will prevent threads generating the same array indices.
long int idx = (long int)void_ptr;
unsigned int seedp = (unsigned int)idx;
int i, rc;
printf("Hello from thread %ld
", idx);
for (i=0; i<ITERATIONS; i++)
{
int num1 = rand_r(&seedp)%ARRAYSIZE;
rc = lock_acquire_elided(&global_lock);
if (rc == 0) // eliding the lock failed
lock_acquire(&global_lock);
// start critical section
long int temp = histogram[num1];
temp += 1;
histogram[num1] = temp;
// end critical section
if (rc == 1)
lock_release_elided();
else
lock_release(&global_lock);
}
printf("Goodbye from thread %ld
", idx);
}
最后,我们把这些放入main函数中,用来创建和加入worker线程。
#include <assert.h>
#include <pthread.h>
#include <unistd.h>
int main() {
long int i, total, numberOfProcessors;
pthread_t *threads;
int rc;
numberOfProcessors = sysconf(_SC_NPROCESSORS_ONLN);
printf("TME parallel histogram with %ld procs
", numberOfProcessors);
lock_init(&global_lock);
// initialise the array
for (i=0; i<ARRAYSIZE; i++)
histogram[i] = 0;
// spawn work
threads = (pthread_t*) malloc(sizeof(pthread_t)*numberOfProcessors);
for (i=0; i<numberOfProcessors-1; i++) {
rc = pthread_create(&threads[i], NULL, work, (void*)i);
assert(rc==0);
}
work((void*)(numberOfProcessors-1));
// wait for worker threads
for (i=0; i<numberOfProcessors-1; i++) {
rc = pthread_join(threads[i], NULL);
assert(rc==0);
}
// verify array contents
total = 0;
for (i=0; i<ARRAYSIZE; i++)
total += histogram[i];
// free resources
free(threads);
printf("Total is %lu
Expected total is %lu
",
total, ITERATIONS*numberOfProcessors);
return 0;
}
编译和运行
TME在GCC 10中已经支持,它包含一个ACLE intrinsics。 为了编译这些带TME功能的源文件,必须使用AArch64 compiler,并使用march选项,比如-march=armv8-a+tme 来使能TME功能。
aarch64-linux-gnu-gcc -std=c11 -O2 -static -march=armv8-a+tme -pthread -o histogram.exe ./histogram.c
gem5必须编译成带新Ruby MESI_Three_Level_HTM 协议的
scons CC=gcc CXX=g++ build/ARM_MESI_Three_Level_HTM/gem5.opt TARGET_ISA=arm PROTOCOL=MESI_Three_Level_HTM SLICC_HTML=True CPU_MODELS=AtomicSimpleCPU,TimingSimpleCPU,O3CPU -j 4
接下来可以在系统模式下运行这个直方图可执行程序
./gem5/build/ARM_MESI_Three_Level_HTM/gem5.opt ./gem5/configs/example/se.py --ruby --num-cpus=2 --cpu-type=TimingSimpleCPU --cmd=./blogexample/histogram.exe
它将有如下面的输出
TME parallel histogram with 2 procs
Hello from thread 1
Hello from thread 0
Goodbye from thread 1
Goodbye from thread 0
Total is 20000
Expected total is 20000
Exiting @ tick 718668000 because exiting with last active thread context
为了验证是否用任何关键段被transactionally执行,我们检查m5out/stats.txt,里面包含HTM相关统计。
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::explicit 35 22.01% 22.01% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::transaction_size 38 23.90% 45.91% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::memory_conflict 86 54.09% 100.00% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::total 159 # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::samples 9927 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::mean 63.466103 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::gmean 56.438036 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::stdev 29.029108 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::32-47 4854 48.90% 48.90% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::48-63 2 0.02% 48.92% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::64-79 195 1.96% 50.88% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::80-95 4627 46.61% 97.49% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::96-111 188 1.89% 99.39% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::112-127 60 0.60% 99.99% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::128-143 1 0.01% 100.00% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::total 9927 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::samples 9927 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::mean 12 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::gmean 12.000000 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::12-13 9927 100.00% 100.00% # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::total 9927 # number of instructions spent in an outer transaction
这个每个core单独的统计,包含了transaction长度信息(cycles数或是指令数),也包含了一个transaction失败终止原因。 在TCANCEL被执行时,Explicit会增加。这会发生在当transaction已经开始后发现global lock被占用。 Memory_conflict 发生在另外一个处理单元(译者:可以简单理解为一个core)试图修改在transaction 读/写集合里的cache line时。Transaction_size表示transaction从L1 data cache溢出,因为这个比较难精确追踪,通过抓取因为同一core load/store引发的一个cache line从 L1 数据cache evict出的信息统计替代。由于比如cache set替换策略的因素,这个统计经常出现一些假的postive。
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::2 12 7.55% 100.00% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::total 159 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::samples 159 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::mean 0.169811 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::stdev 0.376653 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::0 132 83.02% 83.02% # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::1 27 16.98% 100.00% # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::total 159 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::samples 9927 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::mean 1.987710 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::gmean 1.983035 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::stdev 0.110181 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::1 122 1.23% 1.23% # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::2 9805 98.77% 100.00% # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::total 9927 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::samples 9927 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::mean 1 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::gmean 1 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::1 9927 100.00% 100.00% # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::total 9927 # write set size of a committed transaction
这是包含以使用的cache line数量计算的transaction大小的直方图。可以看到大多数的成功transaction是从两个unique的cache line的读,或是对一个cache line的写。这是有用的衡量是否使用 TME-enable应用的标尺。
即刻可用
Arm坚持和开源社区工作,我们视这个创新是为了arm生态系统的持续成功。在gem5 中支持Arm TME的工作已经开源并upstreamed, 从v20.1版本可用,这是我们商业界和学术界的伙伴可以使能很多用例,比如:
在芯片可用之前,测试和benchmark TME-enable应用
决定微构架影响TME实现的功效的参数的敏感性分析
作为发掘和演示这个技术发展的研究平台
原作者:Timothy Hayes
 /7
/7 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 1550
1550


 淘帖
淘帖






