Arm Allinea Studio (AAS) 是 Forge(DDT、MAP 和性能报告)、Arm Compiler for Linux (ACfL) 和 Arm 性能库 (ArmPL) 的组合。
适用于 Linux 的 Arm 编译器 (ACfL) 21.1
Arm Compiler for Linux 是我们的“供应商编译器”包,适用于 HPC 和云工作负载。它包括 C、C++ 和 Fortran 编译器,以及 Arm 性能库。
LLVM12 更新
此版本的 ACfL 包含 LLVM 版本 11 并从版本 12 升级。 显然 LLVM 本身在不断改进,因此我们预计从版本 11 到版本 12 的功能、性能和稳定性将得到普遍改进。它从来没有像与编译器相比,因为要求编译器处理几乎无限的可能输入组合的事情的数量经常相互冲突,例如,快速编译我的代码,确保它是正确的并确保它在所有情况。基于 LLVM12 的 ACfL 的内部基准测试显示,在几个行业标准基准测试以及一些较小的性能回归方面有 1-2% 的改进,但总体上是一个积极的结果。
向量长度特定 (VLS) SVE ACLE 支持
尽管 Arm Compiler for Linux 具有完善的Scalable Vector Extensions(SVE) 支持 Arm C 语言扩展 (ACLE) 代码和自动向量化代码,两者都使用 SVE 自然允许的向量长度不可知 (VLA) 范例。VLA SVE 代码可以编译一次,并且将在您运行它的任何 SVE 实现上很好地矢量化。Vector Length Specific (VLS) SVE 范例是针对 SVE 指令但在编译时指定的固定向量宽度,是 Arm Compiler for Linux 的新增功能。此类 SVE 代码的预期应用是代码固有的固定向量宽度,甚至可能是算法所要求的,或者代码针对固定宽度向量进行了大量优化。有时,如果用户不介意为遇到的每个新矢量宽度重新编译,VLS SVE 可能比 VLA 更可取。霓虹灯目标。
VLS SVE ACLE 支持在 LLVM 12 中完成,因此 ACfL 继承了此功能作为上游合并的功能。新功能提供了一个新的 ACLE 功能宏和类型属性 arm_sve_vector_bits,可用于将普通 SVE ACLE 数据类型专门化为特定的向量宽度。此宽度的值由等效的编译器命令行选项 -msve-vector-bits= 设置。然后用户可以在正常的 SVE ACLE 代码中使用这些类型,但要对向量宽度进行假设。
以下示例对向量宽度以及一次处理多少个 svfloat64_t 变量进行了假设。
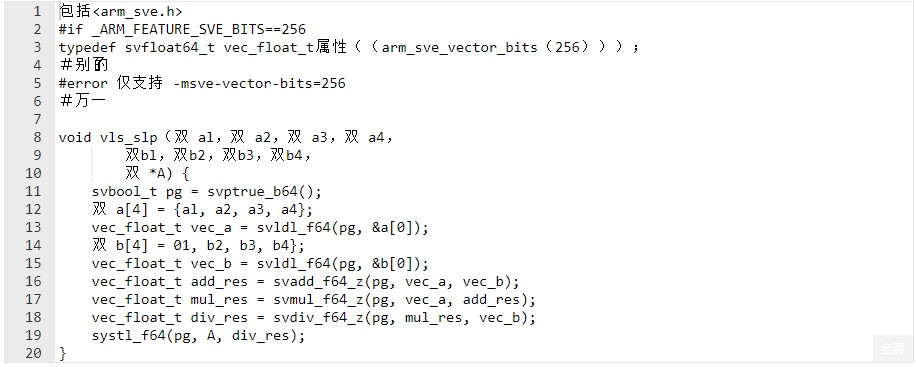
它必须使用 -msve-vector-bits=256 构建以生成以下代码:
全屏
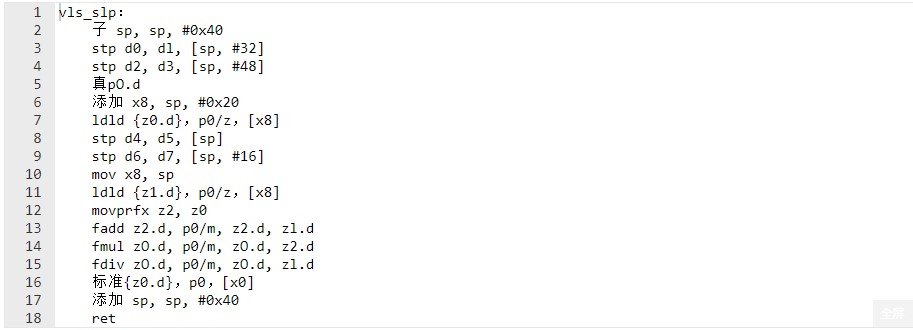
如果硬件 SVE 向量长度不是 256 位,则生成的代码将不会产生预期的结果。如果向量长度较短,则向量代码不会覆盖原始函数的所有代码行。如果向量长度较长,则存储可能会写入未分配的内存。它被调整为 256 的矢量宽度。
将此功能添加到 ACfL 允许它编译现有的 VLS SVE ACLE 代码,如 Grid 和 Gromacs。最新版本的 Gromacs 显示,在 A64FX 上从 Neon 切换到 VLS SVE 后性能提升了 15%。同时,上游 LLVM 对 VLS SVE 矢量化的支持发展良好,并将出现在未来版本的 Arm Compiler for Linux 中。
改进的优化备注
LLVM 优化器的一个有用特性是它的优化注释。这些是可以使用 -Rpass 选项启用的诊断消息,并向用户指示编译器的优化器在其代码通过编译器管道时对其执行的操作。最有用的是,用户可以启用注释,指出编译器无法在代码中应用关键优化的位置以及原因。这可以帮助有积极性的用户尝试手动优化他们的代码,以便通过将热门部分重写为编译器可以优化的形式来尽可能快地在他们的机器上运行。
Arm Compiler for Linux 对优化注释进行了许多下游改进,包括改进的注释文本和附加注释。有时,需要额外的分析代码才能发出高质量的评论。最近,Arm 对上游 LLVM 进行了一些改进,以帮助所有基于 LLVM 的编译器的用户更好地手动优化他们的代码。我们增强了五个注释,当循环依赖(即同一循环的两次迭代之间)阻止向量化时警告用户。
例如,此代码现在生成以下注释:
全屏

我们的修改扩展了注释以具体说明阻止优化的依赖类型,并使其引用源代码而不是 LLVM 中间表示的元素。新的措辞还指向依赖关系中涉及的两个内存访问,而不仅仅是碰巧引发评论的访问。
Arm 性能库 21.1
Arm Performance Libraries 是我们的“供应商”数学库解决方案。它主要部署在 HPC 和云用例中,作为向量和矩阵计算的高性能解决方案,主要围绕密集数据。此外,ArmPL 还为稀疏线性代数、FFT 和 libm 函数提供了解决方案。它既可以作为免费的独立产品使用,也可以作为Arm Allinea Studio中用于 Linux 的 Arm Compiler 的一部分提供。
BLAS 性能改进
自上一个版本以来,我们一直在继续改进 BLAS(基本线性代数子程序)函数的实现,特别关注改进我们处理小问题的方式。我们注意到解决许多小问题对于许多应用程序的重要性有所增加。有时,这来自应用程序级别的更细粒度的并行性,而在其他情况下,这是因为该库被用于处理传统 HPC 之外的新型工作负载(例如,在云中的数据科学中,链接 Python 包numpy 和 scipy 到 Arm PL)。有效地处理小问题意味着削减开销,例如不必要地设置多个线程,并最大限度地减少我们在优化内核中执行的填充数据的工作量。
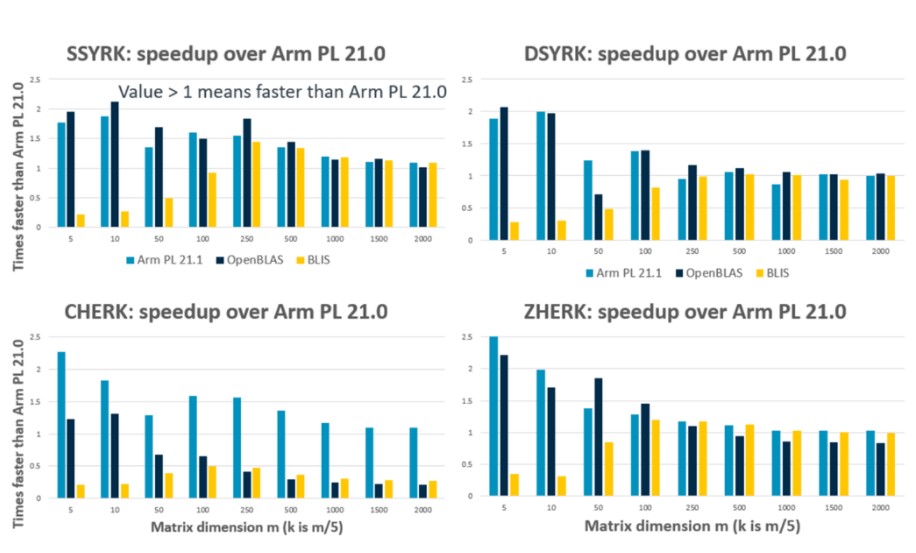
我们在库中使用统一的框架来开发密集的线性代数函数,这使我们能够在不同的函数中采用一致的方法。在改进我们框架的设计和使用方面,我们已经开始看到针对较小问题的改进,同时为引入新的高性能内核奠定了基础,例如即将推出的 Arm 内核中支持 SVE 的 BLAS 功能。例如,在 21.1 版本中,我们重组了 3 级 BLAS 矩阵秩更新函数(?SYRK、?SYR2K),这导致了一些良好的性能改进,如下图 ?SYRK 所示。这些基准测试使用 Graviton 2 和 Neoverse N1 AWS 实例 (c6g.2xlarge) 的单核运行。此处将改进的性能(尤其是对于小型案例)与开源替代方案的最新结果进行比较。
用于交错批处理功能的 SVE 内核
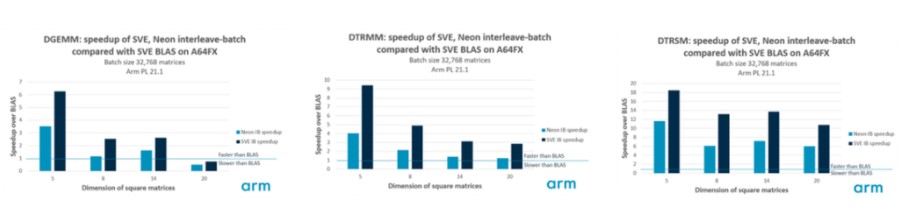
在 21.1 版本中,我们为 21.0 版本中引入的一些 interleave-batch 函数添加了 SVE 内核。Interleave-batch 函数有助于有效处理大量小矩阵,这些矩阵适用于图像信号处理、计算流体动力学、流体动力学和深度学习等许多领域。有关这些功能设计的更多信息, 请参阅此博客 关于这个话题。这里的更改包括对我们的 Neon 内核和新的 SVE 内核的一些改进,用于一般矩阵-矩阵乘法 (armpl_dgemm_interleave_batch)、三角矩阵-矩阵乘法 (armpl_dtrmm_interleave_batch) 和三角矩阵求解 (armpl_dtrsm_interleave_batch)。当交错因子 ninter 是 SVE 向量长度的 8 倍时(尽管函数在任何 ninter 值下都能正常工作),这些函数的 SVE 内核经过优化,可以发挥最佳性能。例如,当在向量长度为 512 位的 A64FX 上运行时,对于双精度实数据,我们的向量长度为 8 个元素,这意味着 ninter 的推荐值为 64。对于我们的 Neon 内核,ninter 的值=16 通常产生最好的性能。
下图显示了我们在 Arm PL 21.1 中使用单个 A64FX 内核对一组 32,768 个矩阵进行操作以选择方矩阵维度时的交错批处理功能的性能。结果显示,使用 Arm PL 的 SVE BLAS 实现,重复调用等效的 BLAS 函数可以获得加速。在每种情况下,我们调整了 interleave-batch 布局以利用推荐的交织因子,即对于 Neon ninter=16 和 nbatch=2048,对于 SVE ninter=64 和 nbatch=512。DGEMM 结果表明,interleave-batch 方法仅不适用于 A64FX 上大小为 20 的矩阵。在所有其他情况下,interleave-batch 方法比 BLAS 快数倍,并且我们的新 SVE 内核与 Neon 等效内核相比具有显着的性能改进。
改善对 Arm PL 的访问
除了致力于性能改进之外,Arm PL 团队还一直致力于改进可访问性。这项工作有几个不同的方面。
首先,我们开始了统一 Arm PL 的基础工作,这是一个构建单个库的项目,该库包含对 Neon 和 SVE 内核的优化。Arm PL 的 21.0 版本从为我们调整的每个微架构生成一个单独的库转变为生成两个库:一个用于所有仅 Neon 内核,一个用于支持 SVE 的内核。在 22.0 中,我们希望将这两个库合并到统一的 Arm PL 中,它同时包含 Neon 和 SVE(由编译器手动调整和自动矢量化),使库包更小、更易于使用和启用ISV 链接到库的单个副本,该副本将在我们支持的任何 AArch64 内核上以最佳方式工作。
除此之外,我们还在努力使该库可移植到其他平台(不仅仅是 Linux)。与 Windows 和 Mac 支持相关的探索性工作正在进行中。敬请关注。
Arm PL 和 Python
允许将 Arm PL 打包以在带有 Numpy 和 Scipy 的 Python 轮子中使用,要求该包可以安装在任何 Linux 发行版中。我们的库构建是针对几个流行的 Linux 发行版分别完成的(例如, 请参阅免费 Arm PL 的下载列表),并且每个构建都与特定的编译器和相关的运行时库相关联,包括 libgfortran 和 glibc。Numpy 开发人员向我们介绍了 manylinux 构建可移植 Python 包的标准,我们已经成功构建了兼容的 Arm PL 串行版本。作为这项工作的一部分,我们还必须消除 Arm PL 对 Fortran 运行时库的依赖(以避免 Python 用户必须单独下载 libgfortran),我们通过在 libarmpl 中隐藏我们需要的 Fortran 运行时对象来做到这一点。结果是该库的可移植串行构建,我们已准备好将其与 Numpy 和 Scipy 一起打包。
手臂锻造 21.1
随着 Arm Forge 21.1 的发布,我们为跨平台的 HPC 应用程序开发人员更新了我们的工具。在其他开发中,该版本通过 GPU 内存传输的可视化提供了增强的应用程序分析。
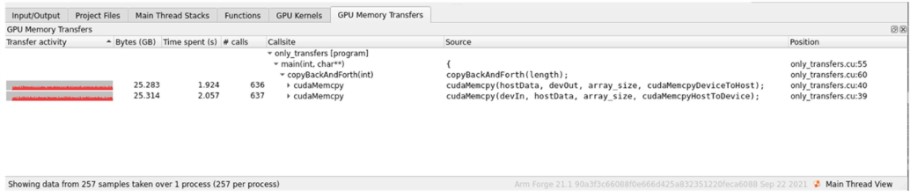
GPU 内存传输的可视化
GPU 内存传输会消耗大量互连带宽。为不同 GPU 优化软件的用户可以从可视化这种流量中受益,尤其是在大规模情况下。今天,Arm MAP 显示等待加速器所花费的时间,但并不能轻易地表示花费在实际 GPU 处理与内存传输上的时间的哪一部分。MAP 中新的内存传输分析功能可帮助用户区分有用的 GPU 计算与内存传输开销,从而为用户提供何时何地优化其软件的提示。
新的 MAP 功能甚至可以帮助用户区分不同类型的转账:
主机 → GPU
GPU → 主机
图形处理器 → 图形处理器
MAP 可以选择性地跟踪和显示堆栈跟踪和进行内存传输的源代码位置。
Forge 的其他改进
将默认的 DDT 调试器升级到 GDB 10.1。
GDB 11.1 添加为 DDT 的可选调试器。
添加了一条警告,以在调试器由于未知的库路径而无法调试共享库时进行通知。
添加了对 Arm Compiler for Linux 21.1 的支持。
添加了对 GCC 11 的支持。
原作者:Daniel Owens
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 4451
4451





 淘帖
淘帖





