完善资料让更多小伙伴认识你,还能领取20积分哦, 立即完善>
3天内不再提示
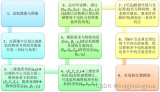
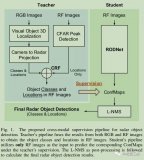
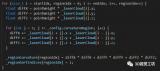





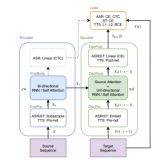



 /6
/6 
关注我们的微信

下载发烧友APP

电子发烧友观察

版权所有 © 湖南华秋数字科技有限公司
电子发烧友 (电路图) 湘公网安备 43011202000918 号 电信与信息服务业务经营许可证:合字B2-20210191 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号










