在阅读第三章关于 DeepSeek 的模型架构部分时,我仿佛打开了一扇通往人工智能核心构造的大门。从架构图中,能清晰看到 Transformer 块、前馈神经网络、注意力机制等模块的协同运作 。这些组件并非孤立存在,而是像精密齿轮般相互咬合,构建起 DeepSeek 的运行基础。
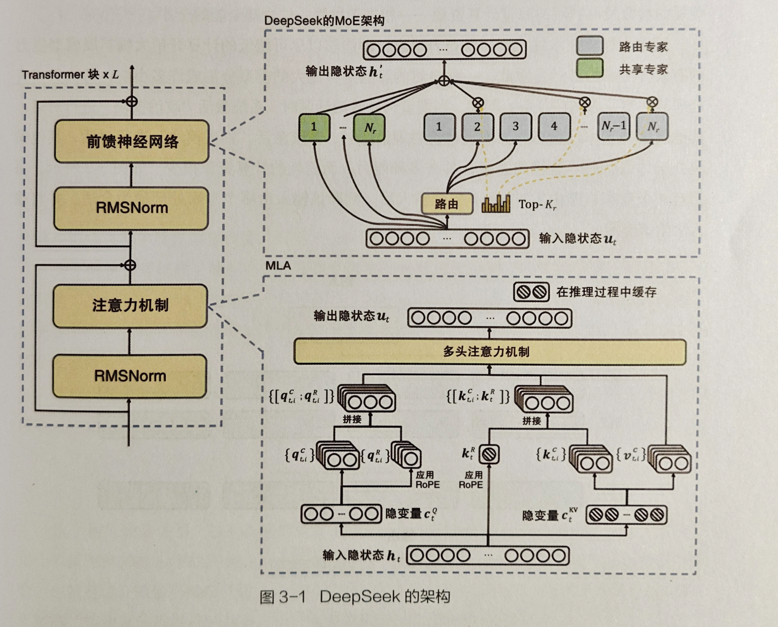
前馈神经网络的信息传递、注意力机制对关键内容的聚焦,让我理解到模型是如何对输入进行层层处理,从海量数据中挖掘有价值信息,这也让我意识到架构设计对模型性能起着根本性作用,是 AI 具备强大能力的 “骨骼” 支撑。
书中关于流水线并行的内容,展现了提升计算效率的巧妙思路。简单流水线并行虽存在资源利用率不高的问题,但它是基础探索,让
我看到将模型分段处理以实现流水线作业的初步尝试。

而 GPipe 方法的改进,通过微批次处理减少并行气泡,如同给流水线 “疏通血管”,让计算设备的闲置时间减少,数据处理更流畅。这让我联想到工业生产中的流水线,AI 训练在此处借鉴类似思路,通过优化任务分配和流程,突破硬件限制,追求更高效率,体现了技术发展中持续优化、突破瓶颈的智慧。

细粒度量化的讲解,让我接触到 AI 模型在精度和效率间寻求平衡的关键技术。不同量化方法,如 per tensor、per token 等,针对数据不同部分采用精细策略,就像给模型数据 “量身定制” 压缩方案,在降低计算资源消耗的同时,努力减少精度损失。
这背后反映的是 AI 技术发展中一个重要命题:如何在有限硬件条件下,让模型既跑得快(效率高)又跑得稳(精度够),这种平衡艺术,彰显了技术研发的细腻与深度,也让我明白追求极致性能需要在诸多矛盾中找到精妙的平衡点。
Transformer 中的 MoE 部分,呈现了模块创新带来的机遇与困境。将 MoE 思想融入 Transformer,通过替换 FFN 层、多机多卡训练等策略,试图拓展模型能力。看到模型容量因专家数量增加而扩展,能处理更复杂任务,让我感受到创新的潜力。但同时,通信成本高、训练稳定性不足等问题,又像横在发展路上的巨石,提醒我技术创新并非坦途,新架构在带来优势的同时,也会伴随新挑战。


读完第三章,DeepSeek - V3 的技术剖析让我从架构、效率优化、精度平衡到模块创新,全方位感受到 AI 大模型研发的复杂与精妙,每一项技术点都凝聚着智慧,也让我对人工智能技术的深度与广度有了新认知,期待后续探索能挖掘更多技术宝藏,见证 AI 发展的更多可能。
更多回帖

