
![]()
![]()
MMU
回帖(1)

2022-2-23 10:44:19
划分空间
在32位ARM架构下,我们可用使用的地址空间为4G(0x0000 0000 ~ 0xFFFF FFFF ),也就是我们能操作的地址空间范围,但是这只是我们软件上的可操作范围。
实际上我们的物理内存可能低于4G或者超过4G,超过4G空间我们就需要用64位的ARM,64位的ARM理论上是没有物理内存范围限制的。
还有就是你所选的ARM,他具体支持多大的物理内存,不是所有的32位ARM都支持4G物理内存,这个和SOC公司相关,SOC公司会根据ARM核心(v7/v8)来重新设计外设,包括存储。
我们举个例子,下面是全志公司基于ARMv7指令集架构,Cortex-A7核心的32位芯片,我们查看芯片的memory map
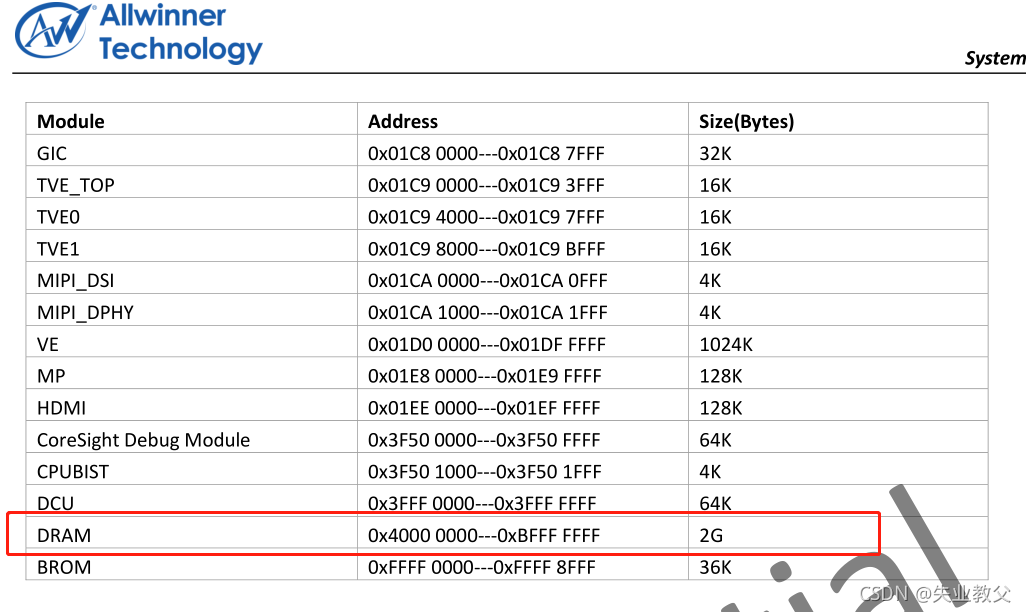 我们可以看到,芯片为DRAM只划分了2G的地址空间,也就是说我们实际上能够使用的外部RAM物理空间只有2G。
好了现在问题来了,对于应用开发者来说,我写程序,我操作存储空间,是希望在(0x0000 0000 ~ 0xFFFF FFFF )这个空间来说,都是可用的,至于最终操作的物理空间是不是这个地址,应用开发者不关心。
所以我们现在就要解决2个问题
我们可以看到,芯片为DRAM只划分了2G的地址空间,也就是说我们实际上能够使用的外部RAM物理空间只有2G。
好了现在问题来了,对于应用开发者来说,我写程序,我操作存储空间,是希望在(0x0000 0000 ~ 0xFFFF FFFF )这个空间来说,都是可用的,至于最终操作的物理空间是不是这个地址,应用开发者不关心。
所以我们现在就要解决2个问题
- 如何把用户操作的(0x0000 0000 ~ 0xFFFF FFFF )映射到真实可用的物理内存
- 如果真实的物理内存低于4G空间,这个映射又如何完成
如何映射地址空间
在没有MMU的ARM上,MCU单片机就是个典型的例子,地址空间是无法进行映射的,用户操作的所有地址都是真是的物理地址,这样虽然很高效,但是这种操作也很危险,很容易引起硬件异常从而造成系统崩溃。
虚拟地址(VA)
我们把(0x0000 0000 ~ 0xFFFF FFFF )称为虚拟地址空间,这是和应用开发者使用的编译器或者操作系统决定的,和芯片和物理内存是没有关系的
物理地址(PA)
这是真实的物理内存芯片上的地址,他的范围由ARM的memory map决定,比如说上面的芯片,物理地址空间就在(0x4000 0000 ~ 0xBFFF FFFF),最大2G,如果超过2G,也是不能访问后面的空间的,所以物理地址是针对ARM芯片来定义的
MMU怎么工作
目标:把(0x4000 0000 ~ 0xBFFF FFFF)映射到(0x0000 0000 ~ 0xFFFF FFFF )
前提:要把2G空间转换4G,从原理上是做不到真实的1:1映射的,我们只能做出一种假象,让用户以为他可用随意使用4G空间,我们发明一种机制,在用户使用虚拟地址的时候,我们用MMU把他转换为2G空间的物理地址即可,一般用户实际的程序对内存的需求都是低于2G。
但是如果用户真的需要超过2G的的空间的时候,我们有两种办法:
- 用磁盘来进行内存交换
- 升级物理内存空间,并同时升级芯片到64位,这样你就可用随意扩展你的真是内存空间了
我们先不考虑64位的事儿,先来搞定32位下如何映射
前面说到,可以借助MMU来完成VM到PM,那这个过程究竟如何完成呢?
步骤很简单,我们来简单描述下这个过程
页表是做啥?
在32位操作系统中,我们一般会把4G虚拟地址空间划分为用户空间和内核空间,拿Linux来说,(0x0000 0000 ~ 0xBFFF FFFF)3G低端内存为用户空间,(0xC000 0000 ~ 0xFFFF FFFF)1G高端内存用作内核空间。说起来很简单,究竟如何实现,很多人都没有说,其实也很简单,你只需要借助链接器就可以完成这个工作,比如说,你现在有2个程序,一个是内核的hello_world,一个是用户的hello_world,我们可以通过ld来为两个不同的程序指定程序实际的代码和数据运行时所在的位置。具体我们编写两个链接脚本就可以实现了,具体就不细说了。
好了,完成了上面这一步,我们完成万里长征第一步,继续加油!
根据链接脚本,我们已经划分好了内核空间和用户空间,这个和地址空间映射暂时还没有什么关系,我们先停下脚步,开始说说页表。
现在我们假设我们还没有划分用户空间和内核空间,整个虚拟地址空间都还纯洁的像一张白纸,如何完成地址映射呢?
首先我们来模拟一下MMU是如何工作的,你就明白了80%了。
当我们开启MMU后,ARM读取虚拟地址后,经过MMU单元,会硬件自动转换成物理地址,最后访问内存。注意,这是硬件自动完成的,你只需要设置好TTB的基地址就可以了。
映射流程:
- cpu获取虚拟地址VA
- 读取CP15中的C13将不同进程的相同虚拟地址转换成MVA,修正后的虚拟地址
- 读取CP15寄存器的C2寄存器,得到TTB的基地址,注意TTB是存放在物理地址中,在编译链接时确定。
- 通过查找页表,最后得到真实的物理地址
我们来简单描述一下:
MMU得到VA,首先根据进程号修正VA得到MVA,我们暂时还没有使用多进程,这个过程暂时跳过,得到VA后,再读取CP15得到TTB,这个非常重要,这个是地址转换的第一步,TTB里描述了整个VA到PA的转换规则,是段式还是页式,是一级页表,还是二级页表,这个过程是硬件自动完成的,我们要做的只是设置好TTB里的内容,这个和MMU的转换恰好是一个逆向过程。
比如说我想把0x0000 0000 ~ 0x1000 0000 映射到 0x5000 0000 ~ 0x6000 0000,我们只需要根据你选择的映射规则逆向的计算出TTB的值,等到MMU转换的时候,就可以正向解释进行正确映射了。
好了,总结一下,要想让MMU正常工作,你需要完成哪些工作?
- 为TTB分配好空间,注意这个地址是真实的物理地址,这个时候MMU还没有开启,你必须把他放在真实的物理地址空间,这个一般都是静态分配的,实际上就是一个数组
- 根据你所需要映射的内存区域,配置好TTB的内容
- 如果你只有一个页表,那么设置好这个一个TTB就可以了,MMU来临时就会根据你的TTB规则去转换
- 如果你分为了几个区域,这是就会产生几个不同的页表,不同页表所映射的区域内容是不一样的权限也不一样,就想之前说的用户空间和内核空间,他们的页表就不一样,使用用户空间的页表是无法访问到内核空间的内存的,这样会引起缺页异常并进入到内核态,交给缺页中断进行处理,必须先切换到内核页表才能访问,所以这样也就实现了地址空间的隔离
问题
说了半天,好像我们要开始实现一个操作系统了,没错,地址空间管理就是操作系统内核核心的模块之一,既然说到这里,我们就列举一下操作系统内核的几个关键模块:
- 内存管理
- 地址空间管理
- 任务调度
- 中断管理
- IPC
你要是把这几大模块搞定了,你就可以随随便便写一个操作系统内核了。
路漫漫其修远兮,吾将上下而求索…
划分空间
在32位ARM架构下,我们可用使用的地址空间为4G(0x0000 0000 ~ 0xFFFF FFFF ),也就是我们能操作的地址空间范围,但是这只是我们软件上的可操作范围。
实际上我们的物理内存可能低于4G或者超过4G,超过4G空间我们就需要用64位的ARM,64位的ARM理论上是没有物理内存范围限制的。
还有就是你所选的ARM,他具体支持多大的物理内存,不是所有的32位ARM都支持4G物理内存,这个和SOC公司相关,SOC公司会根据ARM核心(v7/v8)来重新设计外设,包括存储。
我们举个例子,下面是全志公司基于ARMv7指令集架构,Cortex-A7核心的32位芯片,我们查看芯片的memory map
我们可以看到,芯片为DRAM只划分了2G的地址空间,也就是说我们实际上能够使用的外部RAM物理空间只有2G。
好了现在问题来了,对于应用开发者来说,我写程序,我操作存储空间,是希望在(0x0000 0000 ~ 0xFFFF FFFF )这个空间来说,都是可用的,至于最终操作的物理空间是不是这个地址,应用开发者不关心。
所以我们现在就要解决2个问题
- 如何把用户操作的(0x0000 0000 ~ 0xFFFF FFFF )映射到真实可用的物理内存
- 如果真实的物理内存低于4G空间,这个映射又如何完成
如何映射地址空间
在没有MMU的ARM上,MCU单片机就是个典型的例子,地址空间是无法进行映射的,用户操作的所有地址都是真是的物理地址,这样虽然很高效,但是这种操作也很危险,很容易引起硬件异常从而造成系统崩溃。
虚拟地址(VA)
我们把(0x0000 0000 ~ 0xFFFF FFFF )称为虚拟地址空间,这是和应用开发者使用的编译器或者操作系统决定的,和芯片和物理内存是没有关系的
物理地址(PA)
这是真实的物理内存芯片上的地址,他的范围由ARM的memory map决定,比如说上面的芯片,物理地址空间就在(0x4000 0000 ~ 0xBFFF FFFF),最大2G,如果超过2G,也是不能访问后面的空间的,所以物理地址是针对ARM芯片来定义的
MMU怎么工作
目标:把(0x4000 0000 ~ 0xBFFF FFFF)映射到(0x0000 0000 ~ 0xFFFF FFFF )
前提:要把2G空间转换4G,从原理上是做不到真实的1:1映射的,我们只能做出一种假象,让用户以为他可用随意使用4G空间,我们发明一种机制,在用户使用虚拟地址的时候,我们用MMU把他转换为2G空间的物理地址即可,一般用户实际的程序对内存的需求都是低于2G。
但是如果用户真的需要超过2G的的空间的时候,我们有两种办法:
- 用磁盘来进行内存交换
- 升级物理内存空间,并同时升级芯片到64位,这样你就可用随意扩展你的真是内存空间了
我们先不考虑64位的事儿,先来搞定32位下如何映射
前面说到,可以借助MMU来完成VM到PM,那这个过程究竟如何完成呢?
步骤很简单,我们来简单描述下这个过程
页表是做啥?
在32位操作系统中,我们一般会把4G虚拟地址空间划分为用户空间和内核空间,拿Linux来说,(0x0000 0000 ~ 0xBFFF FFFF)3G低端内存为用户空间,(0xC000 0000 ~ 0xFFFF FFFF)1G高端内存用作内核空间。说起来很简单,究竟如何实现,很多人都没有说,其实也很简单,你只需要借助链接器就可以完成这个工作,比如说,你现在有2个程序,一个是内核的hello_world,一个是用户的hello_world,我们可以通过ld来为两个不同的程序指定程序实际的代码和数据运行时所在的位置。具体我们编写两个链接脚本就可以实现了,具体就不细说了。
好了,完成了上面这一步,我们完成万里长征第一步,继续加油!
根据链接脚本,我们已经划分好了内核空间和用户空间,这个和地址空间映射暂时还没有什么关系,我们先停下脚步,开始说说页表。
现在我们假设我们还没有划分用户空间和内核空间,整个虚拟地址空间都还纯洁的像一张白纸,如何完成地址映射呢?
首先我们来模拟一下MMU是如何工作的,你就明白了80%了。
当我们开启MMU后,ARM读取虚拟地址后,经过MMU单元,会硬件自动转换成物理地址,最后访问内存。注意,这是硬件自动完成的,你只需要设置好TTB的基地址就可以了。
映射流程:
- cpu获取虚拟地址VA
- 读取CP15中的C13将不同进程的相同虚拟地址转换成MVA,修正后的虚拟地址
- 读取CP15寄存器的C2寄存器,得到TTB的基地址,注意TTB是存放在物理地址中,在编译链接时确定。
- 通过查找页表,最后得到真实的物理地址
我们来简单描述一下:
MMU得到VA,首先根据进程号修正VA得到MVA,我们暂时还没有使用多进程,这个过程暂时跳过,得到VA后,再读取CP15得到TTB,这个非常重要,这个是地址转换的第一步,TTB里描述了整个VA到PA的转换规则,是段式还是页式,是一级页表,还是二级页表,这个过程是硬件自动完成的,我们要做的只是设置好TTB里的内容,这个和MMU的转换恰好是一个逆向过程。
比如说我想把0x0000 0000 ~ 0x1000 0000 映射到 0x5000 0000 ~ 0x6000 0000,我们只需要根据你选择的映射规则逆向的计算出TTB的值,等到MMU转换的时候,就可以正向解释进行正确映射了。
好了,总结一下,要想让MMU正常工作,你需要完成哪些工作?
- 为TTB分配好空间,注意这个地址是真实的物理地址,这个时候MMU还没有开启,你必须把他放在真实的物理地址空间,这个一般都是静态分配的,实际上就是一个数组
- 根据你所需要映射的内存区域,配置好TTB的内容
- 如果你只有一个页表,那么设置好这个一个TTB就可以了,MMU来临时就会根据你的TTB规则去转换
- 如果你分为了几个区域,这是就会产生几个不同的页表,不同页表所映射的区域内容是不一样的权限也不一样,就想之前说的用户空间和内核空间,他们的页表就不一样,使用用户空间的页表是无法访问到内核空间的内存的,这样会引起缺页异常并进入到内核态,交给缺页中断进行处理,必须先切换到内核页表才能访问,所以这样也就实现了地址空间的隔离
问题
说了半天,好像我们要开始实现一个操作系统了,没错,地址空间管理就是操作系统内核核心的模块之一,既然说到这里,我们就列举一下操作系统内核的几个关键模块:
- 内存管理
- 地址空间管理
- 任务调度
- 中断管理
- IPC
你要是把这几大模块搞定了,你就可以随随便便写一个操作系统内核了。
路漫漫其修远兮,吾将上下而求索…

 举报
举报
更多回帖



