1.率失真代价计算模型
HEVC 的最大编码单元为 LCU,即 64×64 的 CU,对一个 LCU 选择最佳 CU编码深度,需要遍历所有 64×64 到 8×8 的分割,一共 85 个 CU,通过计算率失真代价选择此 LCU 的最佳分割方式。对于每一个 CU,遍历帧内和帧间所有可选的预测模式,根据率失真代价选择最佳 PU 预测模式。对于每一种 PU 预测模式,TU的分割方式由当前 CU 的大小PU 的预测模式以及最大 TU 分割深度等因素决定,选择过程也需要计算率失真代价。可以看出,在 HEVC 编码过程中,任何一个划分方式或预测模式的选择,都需要计算率失真代价, HM 的编码器中,率失真代价的计算模型有以下两种:
1、非 RDO 模型
非 RDO 模型可用于帧内预测、运动估计、最佳 MVP 的选择 及 merge 模式中最佳运动参数集的选择等。
2、RDO 模型
所有有关分割方式的选择都采用 RDO 模型计算率失真代价。
2.LCU 编码深度选择过程
当 LCU 的大小为 64×64,最大编码深度为 3,则 LCU 编码深度的选择过程可如下图表示。
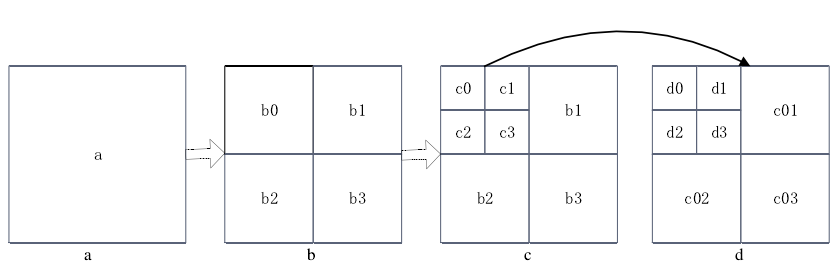
第一步,如图 a),对大小为 64×64 深度为 0 的编码单元 a 遍历所有帧间和帧内预测模式,得到深度为 0 时的最优预测模式和率失真代价 Ra。
第二步,如图 b),对 a 进行一次 CU 划分,得到四个子 CU:b0,b1,b2,b3,此时编码深度为 1,并对编码单元 b0 遍历所有帧间和帧内预测模式,得到 b0的最优预测方式和率失真代价 Rb0。
第三步,如图 c),对 b0 进行进一步的 CU 划分,得到四个子 CU:c0,c1,c2 和 c3,此时编码深度为 2,并对编码单元 c0 遍历所有可能的预测模式,得到 c0的最优预测模式和率失真代价 Rc0。
第四步,如图 d),对 c0 做进一步 CU 划分,得到四个子 CU:d0,d1,d2和 d3,此时编码深度为 3,已达到最大编码深度,不能再进行 CU 划分。依次对d0、d1、d2 和 d3 进行预测模式选择,得到各自对应的最优预测方式和率失真代价Rd0、Rd1、Rd2以及 Rd3,计算四个 CU 的率失真代价之和,并与 Rc0进行比较,选择较小的值作为 c0 的最优率失真代价(记为 Min-Rc0),其对应的预测方式以及分割方式即为 c0 的最优预测方式和分割方式。
第五步,仿照第四步,依次对 c1、c2 和 c3 进行划分与预测模式选择,分别得到各自对应的最优预测方式和率失真代价 Min-Rc1、Min-Rc2、Min-Rc3,并计算当前编码深度的四个 CU 的率失真代价之和,与 Rb0比较,得到较小的率失真代价(记为 Min-Rb0),其所对应的预测模式以及分割方式即为 b0 的最优预测模式和分割方式。
第六步,仿照第二步到第五步,依次对 b1、b2 和 b3 进行划分与预测模式选择,分别得到各自对应的最优预测方式和率失真代价 Min-Rb1、Min-Rb2、Min-Rb3,计并计算当前编码深度的四个 CU 的率失真代价之和,并与 Ra 比较,得到较小的率失真代价(记为 Min-Ra),找出该 LCU 的最佳划分方式以及最优预测模式。
3.CU 的预测模式选择过程
在 LCU 的最佳划分方式的选择过程中,对于每一个编码深度的 CU,做 PU 预测模式选择,一个大小为 2N×2N 的 CU,PU 帧间预测模式有 skip、2N×2N、2N×N、N×2N、N×N、2N×nU、2N×nD、nL×2N 以及 nR×2N。其中 skip 模式对应的 CU划分方式为 2N×2N,N×N 模式只有在 CU 的大小为 8×8 时才会使用。后四种模式统称为 AMP 模式,AMP 模式可以根据需要在参数配置中直接关闭。在 AMP 模式打开的情况下,这四种模式的选择与前面的选择结果相关。帧内模式 PU 的大小可以为 2N×2N 或 N×N,N×N 只能适用于深度为最大编码深度的 CU。对于每一个
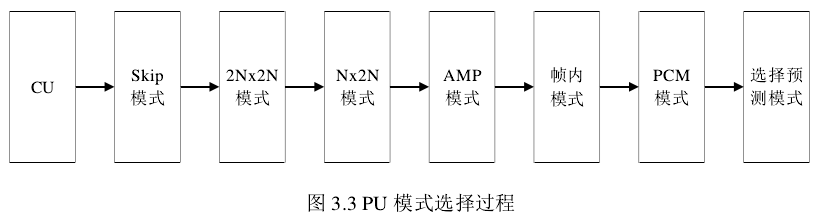
PU,共有 35 种帧内预测模式。PU 的模式选择过程如图 3.3 所示:
第一步,计算 skip 模式的率失真代价,skip 模式运用到了 HEVC 中的新引入的运动合并技术。运用运动参数候选列表中的每个运动参数集找到预测块,与原始块做差值并进行变换,量化和熵编码。最后用编码的比特数和重构块以及原始块的失真计算出率失真代价,找到最佳的 merge-index。
第二步,计算 2N×2N 模式的率失真代价,首先运用 AMVP 技术得到 MVP 列表;然后运用非 RDO 方法计算率失真代价得到最佳 MVP;最后做运动搜索,找到预测块,与原始块做差值并进行变换、量化和熵编码,运用编码比特数以及重构块和原始块的 SSD 计算出率失真代价。与 skip 模式的率失真代价进行比较,在skip 和 2N×2N 中找出最佳 PU 模式。
第三步,计算 2N×N 和 N×2N 模式的率失真代价,首先运用 AMVP 技术,找到最佳 MVP 并作运动搜索找到预测块;然后运用运动合并技术技术,得到最佳merge-index 对应的率失真代价,根据率失真代价确定最佳预测模式;最后对最佳模式得到的残差做变换量化和熵编码运用RDO计算出当前PU模式的率失真代价,并与第二步得到的最佳 PU 模式的率失真代价做比较,得到最佳 PU 模式。
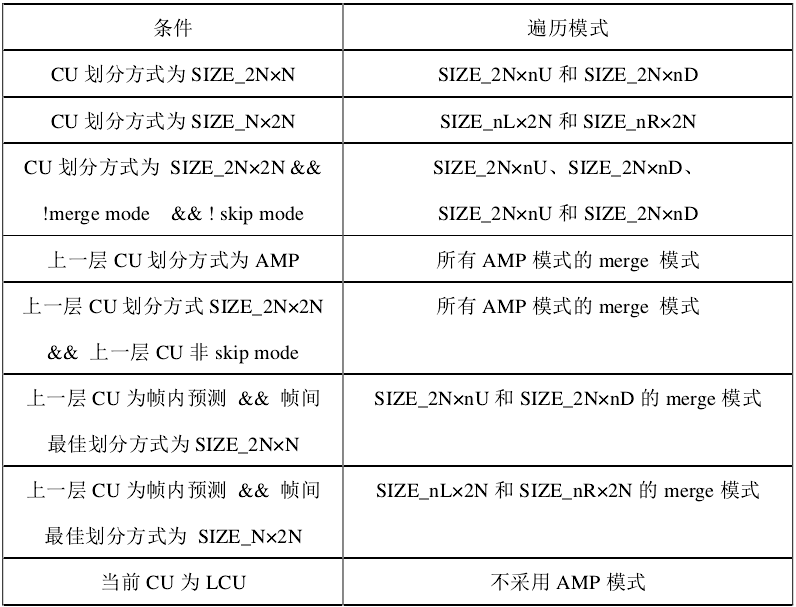
第四步,计算 AMP 模式的率失真代价,AMP 模式包括四种分割方式,但是为了减小编码复杂度,编码过程中并没有遍历所有的模式,而是根据前三步选出的最佳PU模式以及上一层的CU的最佳分割模式以及预测模式选择部分做模式判决。具体选择如下表:
第五步,帧内预测模式选择,对于 I_SLICE 或非 I_SLICE 中需要编码的量化系数不全为 0 的 CU,需要做帧内预测的分割方式和帧内预测模式选择,选择过程如下:
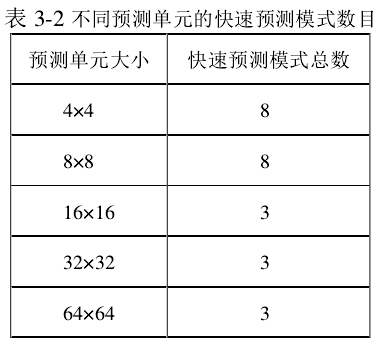
1、预测单元 PU 大小与 CU 大小一致为 2N×2N,用非 RDO 模型计算率失真代价,从 35 种帧内预测模式中找到率失真代价较小的 n 中预测模式作为候选模式,n 的大小与 PU 的大小相关,如表 3-2 所示。
2、将当前 PU 上侧和左侧相邻 PU 采用的帧内预测模式,即当前 PU 最有可能的预测模式(MPM)加入到该步骤的候选模式中,此时候选模式 k 最多为(n+2)。
3、运用 RDO 模型计算率失真代价在 k 种最佳候选模式中选出最佳亮度的帧内预测模式。
4、根据亮度的帧内预测模式选择结果,做色度的帧内预测模式选择。
5、如果当前编码单元的编码深度为最大编码深度,将当前编码单元分为 4 个N×N 的 PU,对于每一个 PU 重复 1~4 步,找到每一个 PU 的最佳帧内预测模式以及最佳预测模式对应的率失真代价。
6、根据前几步得到率失真代价的值,决定当前 CU 的最佳划分方式及帧内预测模式。
第六步,计算 PCM 模式的率失真代价。
由上述描述可知,对于一个 LCU 想要得到最佳 CU 划分方式,需要遍历其所有的 CU,对每个 CU 还需要遍历各种预测模式,得到其最小的率失真代价。为加快编码速度,模式选择过程的优化可从 CU 编码深度的选择,PU 模式选择和 TU分割方式的选择三个方面进行研究和分析。因为 PU 模式选择和 TU 分割方式选择都是为了计算当前深度下,编码 CU 的率失真代价,减少 CU 遍历的次数,同时也减少了 PU 模式选择的次数和 TU 分割方式选择的次数。因此,基于 CU 编码深度选择过程做算法优化是最有效的。
1.率失真代价计算模型
HEVC 的最大编码单元为 LCU,即 64×64 的 CU,对一个 LCU 选择最佳 CU编码深度,需要遍历所有 64×64 到 8×8 的分割,一共 85 个 CU,通过计算率失真代价选择此 LCU 的最佳分割方式。对于每一个 CU,遍历帧内和帧间所有可选的预测模式,根据率失真代价选择最佳 PU 预测模式。对于每一种 PU 预测模式,TU的分割方式由当前 CU 的大小PU 的预测模式以及最大 TU 分割深度等因素决定,选择过程也需要计算率失真代价。可以看出,在 HEVC 编码过程中,任何一个划分方式或预测模式的选择,都需要计算率失真代价, HM 的编码器中,率失真代价的计算模型有以下两种:
1、非 RDO 模型
非 RDO 模型可用于帧内预测、运动估计、最佳 MVP 的选择 及 merge 模式中最佳运动参数集的选择等。
2、RDO 模型
所有有关分割方式的选择都采用 RDO 模型计算率失真代价。
2.LCU 编码深度选择过程
当 LCU 的大小为 64×64,最大编码深度为 3,则 LCU 编码深度的选择过程可如下图表示。
第一步,如图 a),对大小为 64×64 深度为 0 的编码单元 a 遍历所有帧间和帧内预测模式,得到深度为 0 时的最优预测模式和率失真代价 Ra。
第二步,如图 b),对 a 进行一次 CU 划分,得到四个子 CU:b0,b1,b2,b3,此时编码深度为 1,并对编码单元 b0 遍历所有帧间和帧内预测模式,得到 b0的最优预测方式和率失真代价 Rb0。
第三步,如图 c),对 b0 进行进一步的 CU 划分,得到四个子 CU:c0,c1,c2 和 c3,此时编码深度为 2,并对编码单元 c0 遍历所有可能的预测模式,得到 c0的最优预测模式和率失真代价 Rc0。
第四步,如图 d),对 c0 做进一步 CU 划分,得到四个子 CU:d0,d1,d2和 d3,此时编码深度为 3,已达到最大编码深度,不能再进行 CU 划分。依次对d0、d1、d2 和 d3 进行预测模式选择,得到各自对应的最优预测方式和率失真代价Rd0、Rd1、Rd2以及 Rd3,计算四个 CU 的率失真代价之和,并与 Rc0进行比较,选择较小的值作为 c0 的最优率失真代价(记为 Min-Rc0),其对应的预测方式以及分割方式即为 c0 的最优预测方式和分割方式。
第五步,仿照第四步,依次对 c1、c2 和 c3 进行划分与预测模式选择,分别得到各自对应的最优预测方式和率失真代价 Min-Rc1、Min-Rc2、Min-Rc3,并计算当前编码深度的四个 CU 的率失真代价之和,与 Rb0比较,得到较小的率失真代价(记为 Min-Rb0),其所对应的预测模式以及分割方式即为 b0 的最优预测模式和分割方式。
第六步,仿照第二步到第五步,依次对 b1、b2 和 b3 进行划分与预测模式选择,分别得到各自对应的最优预测方式和率失真代价 Min-Rb1、Min-Rb2、Min-Rb3,计并计算当前编码深度的四个 CU 的率失真代价之和,并与 Ra 比较,得到较小的率失真代价(记为 Min-Ra),找出该 LCU 的最佳划分方式以及最优预测模式。
3.CU 的预测模式选择过程
在 LCU 的最佳划分方式的选择过程中,对于每一个编码深度的 CU,做 PU 预测模式选择,一个大小为 2N×2N 的 CU,PU 帧间预测模式有 skip、2N×2N、2N×N、N×2N、N×N、2N×nU、2N×nD、nL×2N 以及 nR×2N。其中 skip 模式对应的 CU划分方式为 2N×2N,N×N 模式只有在 CU 的大小为 8×8 时才会使用。后四种模式统称为 AMP 模式,AMP 模式可以根据需要在参数配置中直接关闭。在 AMP 模式打开的情况下,这四种模式的选择与前面的选择结果相关。帧内模式 PU 的大小可以为 2N×2N 或 N×N,N×N 只能适用于深度为最大编码深度的 CU。对于每一个
PU,共有 35 种帧内预测模式。PU 的模式选择过程如图 3.3 所示:
第一步,计算 skip 模式的率失真代价,skip 模式运用到了 HEVC 中的新引入的运动合并技术。运用运动参数候选列表中的每个运动参数集找到预测块,与原始块做差值并进行变换,量化和熵编码。最后用编码的比特数和重构块以及原始块的失真计算出率失真代价,找到最佳的 merge-index。
第二步,计算 2N×2N 模式的率失真代价,首先运用 AMVP 技术得到 MVP 列表;然后运用非 RDO 方法计算率失真代价得到最佳 MVP;最后做运动搜索,找到预测块,与原始块做差值并进行变换、量化和熵编码,运用编码比特数以及重构块和原始块的 SSD 计算出率失真代价。与 skip 模式的率失真代价进行比较,在skip 和 2N×2N 中找出最佳 PU 模式。
第三步,计算 2N×N 和 N×2N 模式的率失真代价,首先运用 AMVP 技术,找到最佳 MVP 并作运动搜索找到预测块;然后运用运动合并技术技术,得到最佳merge-index 对应的率失真代价,根据率失真代价确定最佳预测模式;最后对最佳模式得到的残差做变换量化和熵编码运用RDO计算出当前PU模式的率失真代价,并与第二步得到的最佳 PU 模式的率失真代价做比较,得到最佳 PU 模式。
第四步,计算 AMP 模式的率失真代价,AMP 模式包括四种分割方式,但是为了减小编码复杂度,编码过程中并没有遍历所有的模式,而是根据前三步选出的最佳PU模式以及上一层的CU的最佳分割模式以及预测模式选择部分做模式判决。具体选择如下表:
第五步,帧内预测模式选择,对于 I_SLICE 或非 I_SLICE 中需要编码的量化系数不全为 0 的 CU,需要做帧内预测的分割方式和帧内预测模式选择,选择过程如下:
1、预测单元 PU 大小与 CU 大小一致为 2N×2N,用非 RDO 模型计算率失真代价,从 35 种帧内预测模式中找到率失真代价较小的 n 中预测模式作为候选模式,n 的大小与 PU 的大小相关,如表 3-2 所示。
2、将当前 PU 上侧和左侧相邻 PU 采用的帧内预测模式,即当前 PU 最有可能的预测模式(MPM)加入到该步骤的候选模式中,此时候选模式 k 最多为(n+2)。
3、运用 RDO 模型计算率失真代价在 k 种最佳候选模式中选出最佳亮度的帧内预测模式。
4、根据亮度的帧内预测模式选择结果,做色度的帧内预测模式选择。
5、如果当前编码单元的编码深度为最大编码深度,将当前编码单元分为 4 个N×N 的 PU,对于每一个 PU 重复 1~4 步,找到每一个 PU 的最佳帧内预测模式以及最佳预测模式对应的率失真代价。
6、根据前几步得到率失真代价的值,决定当前 CU 的最佳划分方式及帧内预测模式。
第六步,计算 PCM 模式的率失真代价。
由上述描述可知,对于一个 LCU 想要得到最佳 CU 划分方式,需要遍历其所有的 CU,对每个 CU 还需要遍历各种预测模式,得到其最小的率失真代价。为加快编码速度,模式选择过程的优化可从 CU 编码深度的选择,PU 模式选择和 TU分割方式的选择三个方面进行研究和分析。因为 PU 模式选择和 TU 分割方式选择都是为了计算当前深度下,编码 CU 的率失真代价,减少 CU 遍历的次数,同时也减少了 PU 模式选择的次数和 TU 分割方式选择的次数。因此,基于 CU 编码深度选择过程做算法优化是最有效的。

 举报
举报




