开启该帖子的消息推送
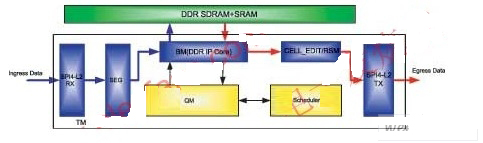
随着通信协议的发展及多样化,协议处理部分PE在硬件转发实现方面,普遍采用现有的商用芯片NP(Network Processor,网络处理器)来完成,流量管理部分需要根据系统的需要进行定制或采用商用芯片来完成。
更多回帖
无需安装、支持浏览器和手机在线查看、实时共享
登录更多精彩功能!


 举报
举报
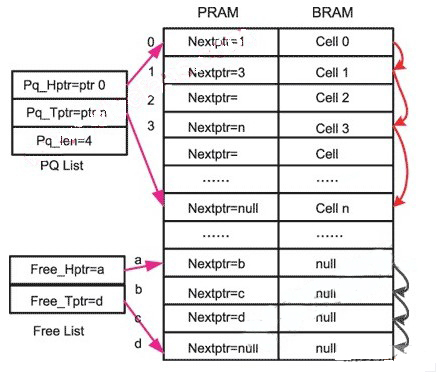
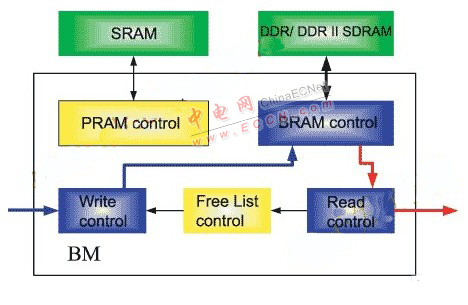
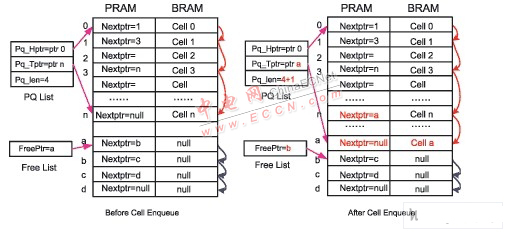
 举报
举报

 举报
举报



