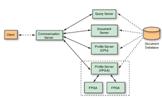
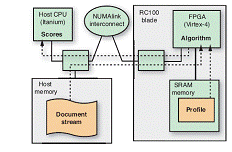
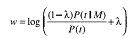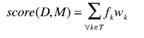定制硬件平台
我们用这个项目探讨了 FPGA 加速的可能性,并展示了 FPGA 作为数据中心绿色环保技术的巨大潜力。我们希望进一步扩展这项研究,调查文档处理所需的全系列工作任务,如语法分析、词干、索引、搜索以及过滤等。我们清楚地认识到,现有系统在节能潜力方面很有限,我们希望研究能以业界最高效率专门执行信息检索任务的可定制硬件平台。这样,我们就能显著加速算法的执行,同时大幅度降低能耗,从而开发出更加环保、速度更快的数据中心。
定制硬件平台
我们用这个项目探讨了 FPGA 加速的可能性,并展示了 FPGA 作为数据中心绿色环保技术的巨大潜力。我们希望进一步扩展这项研究,调查文档处理所需的全系列工作任务,如语法分析、词干、索引、搜索以及过滤等。我们清楚地认识到,现有系统在节能潜力方面很有限,我们希望研究能以业界最高效率专门执行信息检索任务的可定制硬件平台。这样,我们就能显著加速算法的执行,同时大幅度降低能耗,从而开发出更加环保、速度更快的数据中心。

 举报
举报