0 引言
对于大多数人来说,都会有这样的客户体验:去银行或者保险公司办理业务,或者接收他们的保单宣传,我们所面对和接收的都是一张张一样的表单,然后上面有一些空白的表格或者下划线,然后将客户的信息填上去。这样的做法有以下两个缺点:
(1)客户体验差。所有客户拿到的都是一样的表单,因为考虑特殊的情况,表单里面的空白的地方都会比较大,所以一般会出现大片空白的区域。
(2)对于每种不同的客户或者不同的业务会需要不同的表单,对于客户信息变动的情况,需要人工完成,比较繁琐。
为了更好的客户体验,越来越多的公司倾向于采用动态打印技术。这样每个客户接收到的文档或者打印件都是定制化的,这样就能克服以上缺点而做到:
(1)客户体验优。所有客户拿到的文档都是定制化的,表单里没有需要填空的地方,客户的数据都会被程序动态地植入表格模板里,就好像专门为客户定做的文档。
(2)我们可以在模板中定义一些规则,然后根据客户数据来采用相应的规则。例如,美国各个州的法律是不一样的,我们可以在编辑文档的时候就定义规则:如果客户是A州的,就用A条文,如果是B州的,就用B条文。这样当生成文档的时候,程序会根据当前客户是属于哪个州的,动态地加入这一段条文,而不需要人工的判定。并且,当客户从A州搬到B州,我们只需要更新一下客户的数据,客户下次就能拿到更新的正确的文档。

2019-7-19 11:17:31
1 动态文档发布系统
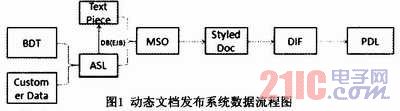
有了如上的需求,很多公司都加入了开发动态文档发布系统的行列。对于动态文档发布,简单说起来,一般的步骤是:1)建立文档模板;2)运行时,装载客户数据进入模板;3)拼接文档;4)排版;5)输出前处理;6)输出成不同格式的文档;7)发布和归档。
动态文档发布系统可以使客户高性能制作并发送设计精美、高度个性化的沟通材料,从合同、保险单、大批量的账户关系维护通知单,到定制的推广资料、商业信函等。客户可以在该系统平台上,运用自己熟悉的文档开发软件,如Word、Adobe Indesign、Dream Weaver,开发出文档模板,并根据系统提供的插件进行逻辑的设置。然后,该模板就能被送往系统,跟随提供的客户数据而批量地生成客户需要的定制文档。接着,生成的文件可以通过不同的途径,例如,邮件、e-mail、手机短信等方式发送到客户,使客户有良好的用户体验。
2 自动化测试的要求
对于这样一个复杂的系统,它的主要客户是一些保险公司和银行,而它的主要产出是保单和合同。同时,合同和保单都是很严肃和很严谨的文档。客户需要的是他们的客户在客户数据没有改变的情况下,得到的是一贯的体验。
但是同时,动态文档发布系统本身又是一个不断发展和改善的系统。它拥有非常复杂的排版逻辑,并且每个版本的升级都会有大量的新功能和新逻辑被引入,这样的逻辑改变如果哪怕有一点点的差错,原来客户的整个文档可能就会面目全非。如果老的客户需要升级这些新功能的话,我们需要保证客户得到一贯的体验。也就是说,他们用旧的版本系统生成的文档和在新的版本系统生成的文档要保持一致,除非新的版本生成的更好,并得到客户的同意。
这样,为了达到上面的目标,我们需要在新版本发布前,运行一些老客户的文档(挑选一些很典型的客户文档),并且一个个和老版本生产的文档进行比较。但是我们不能把这个过程推到新版本发布之前才做,因为那个时候整个项目已经积累了很多的不同点,很难追查到源头并加以改正。所以我们需要把这个过程提前,并且频繁地去检查。
由于需要频繁的检查,并且文档的比较是个很繁重的体力活,所以自动测试将会是很好的方法,它不仅能够节省绝对的人力,而且能够保证绝对的准确,不会被人为因素干扰。
我们可以把这个自动测试集成到日常的打包系统中,每次打包后就可以自动地完成运行,比较和生成报告。
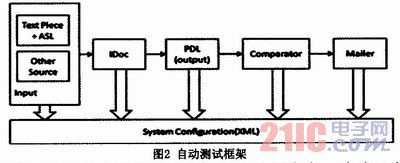
但是,我们不能在打包服务器上每次都去部署新的系统,因为那样太笨重了,并且会让环境问题和我们系统本身的问题经常性地纠缠不清。所以,我们需要自己建立一套轻量级的架构去承载这个测试过程:
(1)我们的系统是建立在基于应用服务器的EJB架构上的,并且EJB的主要操作是基于对数据库的操作,但是我们对于该自动测试的系统的要求是,对外部的依赖越少越好,因为这样的话,我们就能很方便地在各个相关程序员和测试人员以及配置人员之间进行部署和实施,所以我们希望他不要依赖应用服务器和数据库。
(2)我们要明确输入源和输出源,并且能够提供一些简单并且方便的配置,而且在很小代价的前提下,能够在不同的输入源和输出源之间随意切换。
(3)结果必须是可以有办法鉴别的,并且鉴别结果是能够很容易取得和方便查阅的。
1 动态文档发布系统
有了如上的需求,很多公司都加入了开发动态文档发布系统的行列。对于动态文档发布,简单说起来,一般的步骤是:1)建立文档模板;2)运行时,装载客户数据进入模板;3)拼接文档;4)排版;5)输出前处理;6)输出成不同格式的文档;7)发布和归档。
动态文档发布系统可以使客户高性能制作并发送设计精美、高度个性化的沟通材料,从合同、保险单、大批量的账户关系维护通知单,到定制的推广资料、商业信函等。客户可以在该系统平台上,运用自己熟悉的文档开发软件,如Word、Adobe Indesign、Dream Weaver,开发出文档模板,并根据系统提供的插件进行逻辑的设置。然后,该模板就能被送往系统,跟随提供的客户数据而批量地生成客户需要的定制文档。接着,生成的文件可以通过不同的途径,例如,邮件、e-mail、手机短信等方式发送到客户,使客户有良好的用户体验。
2 自动化测试的要求
对于这样一个复杂的系统,它的主要客户是一些保险公司和银行,而它的主要产出是保单和合同。同时,合同和保单都是很严肃和很严谨的文档。客户需要的是他们的客户在客户数据没有改变的情况下,得到的是一贯的体验。
但是同时,动态文档发布系统本身又是一个不断发展和改善的系统。它拥有非常复杂的排版逻辑,并且每个版本的升级都会有大量的新功能和新逻辑被引入,这样的逻辑改变如果哪怕有一点点的差错,原来客户的整个文档可能就会面目全非。如果老的客户需要升级这些新功能的话,我们需要保证客户得到一贯的体验。也就是说,他们用旧的版本系统生成的文档和在新的版本系统生成的文档要保持一致,除非新的版本生成的更好,并得到客户的同意。
这样,为了达到上面的目标,我们需要在新版本发布前,运行一些老客户的文档(挑选一些很典型的客户文档),并且一个个和老版本生产的文档进行比较。但是我们不能把这个过程推到新版本发布之前才做,因为那个时候整个项目已经积累了很多的不同点,很难追查到源头并加以改正。所以我们需要把这个过程提前,并且频繁地去检查。
由于需要频繁的检查,并且文档的比较是个很繁重的体力活,所以自动测试将会是很好的方法,它不仅能够节省绝对的人力,而且能够保证绝对的准确,不会被人为因素干扰。
我们可以把这个自动测试集成到日常的打包系统中,每次打包后就可以自动地完成运行,比较和生成报告。
但是,我们不能在打包服务器上每次都去部署新的系统,因为那样太笨重了,并且会让环境问题和我们系统本身的问题经常性地纠缠不清。所以,我们需要自己建立一套轻量级的架构去承载这个测试过程:
(1)我们的系统是建立在基于应用服务器的EJB架构上的,并且EJB的主要操作是基于对数据库的操作,但是我们对于该自动测试的系统的要求是,对外部的依赖越少越好,因为这样的话,我们就能很方便地在各个相关程序员和测试人员以及配置人员之间进行部署和实施,所以我们希望他不要依赖应用服务器和数据库。
(2)我们要明确输入源和输出源,并且能够提供一些简单并且方便的配置,而且在很小代价的前提下,能够在不同的输入源和输出源之间随意切换。
(3)结果必须是可以有办法鉴别的,并且鉴别结果是能够很容易取得和方便查阅的。

 举报
举报

2019-7-19 11:17:40
4 结论
由于文档发布系统的客户对于不同系统版本间文档一致性的高要求,使我们必须要提供一个长久的机制保证这个一致性。而要保证这个系统的一致性,我们提出了一个轻量级自动测试的方案。这里所说的轻量级,只是说该框架下运行方便,不需要受应用服务器和数据库的约束,但是理论它上提供了文档发布系统同样的功能和行为。实际上在整个过程中,我们尽量调用原先系统的程序,但是在解除对于服务器和数据库的依赖方面,我们通过仔细分析原来的动态文档发布系统各个模块的前提下,采用了用本地文件模拟数据库的方法,通过重载方法实现了对于数据库的解耦。该框架提供了强大的可配置功能,通过简单的XML设置,我们可以对整个过程进行配置,灵活实现不同的功能组合。
在未来,我们还会不断完善这个框架,例如会提供更多的输入选择,提供可视化的配置,提供尽量准确的诊断功能帮助程序员方便定位错误,并且根据动态文档发布系统的升级而相应提供更多的配置和功能。
4 结论
由于文档发布系统的客户对于不同系统版本间文档一致性的高要求,使我们必须要提供一个长久的机制保证这个一致性。而要保证这个系统的一致性,我们提出了一个轻量级自动测试的方案。这里所说的轻量级,只是说该框架下运行方便,不需要受应用服务器和数据库的约束,但是理论它上提供了文档发布系统同样的功能和行为。实际上在整个过程中,我们尽量调用原先系统的程序,但是在解除对于服务器和数据库的依赖方面,我们通过仔细分析原来的动态文档发布系统各个模块的前提下,采用了用本地文件模拟数据库的方法,通过重载方法实现了对于数据库的解耦。该框架提供了强大的可配置功能,通过简单的XML设置,我们可以对整个过程进行配置,灵活实现不同的功能组合。
在未来,我们还会不断完善这个框架,例如会提供更多的输入选择,提供可视化的配置,提供尽量准确的诊断功能帮助程序员方便定位错误,并且根据动态文档发布系统的升级而相应提供更多的配置和功能。
举报