嵌入式人工智能(EAI)将人工智能集成到机器人等物理实体中,使它们能够感知、学习环境并与之动态交互。这种能力使此类机器人能够在人类社会中有效地提供商品及服务。
数据是互联网和机器人领域货币化的重要工具,在互联网领域,公司主要将用户数据用于定向广告和个性化内容。这种有针对性的方法不仅可以增加销售额,还可以提高用户参与度,从而导致更高的订阅费用或增加使用量。同时,在EAI领域,数据对于训练增强和优化机器人能力的深度学习模型至关重要。
从财务上讲,用户数据对互联网公司具有重要价值,估计每个用户 600 美元,考虑到大规模商业化后每个机器人的估计成本为 35000 美元,可以保守预测的是机器人公司有愿意将每个机器人成本的大约 3% 投入到数据收集和生成中。这项投资旨在开发先进的 EAI 功能,估计 EAI 数据的市场价值超过 10 万亿美元,是互联网行业的三倍。
由此可见EAI 的巨大潜在数据,如今 EAI 的数据收集和生成行业仍处于起步阶段。

图 1 数据货币化
虽然 EAI 数据行业的未来看起来一片光明,但如今 EAI 系统的可扩展性受到重大数据瓶颈的严重阻碍。与主要由用户生成的输入组成且相对容易收集和汇总的 Internet 数据不同,EAI 的数据涉及机器人与其动态环境之间的复杂交互。这一根本差异意味着,虽然可以从跨数字平台的用户活动中挖掘互联网数据,但 EAI 数据必须在各种且通常不可预测的环境中捕获无数物理交互。
例如,虽然易于访问的聊天数据允许使用 570 GB 的文本训练 ChatGPT 4,并展示了对聊天任务的非凡熟练程度,但由于其多模态性质,训练 EAI 模型需要更多的机器人数据。这些机器人数据包括各种传感输入和交互类型,不仅极具挑战性,而且收集成本高昂。
训练 EAI 的第一个挑战是访问广泛、高质量和多样化的数据集。例如,自主导航机器人需要处理大量环境数据,以增强其路径规划和避障能力。此外,数据的精度直接影响机器人的性能;从事高精度任务的工业机器人需要极其精确的数据,其中微小的误差可能会导致生产质量出现重大问题。此外,机器人在不同环境中适应和泛化的能力取决于它处理的数据的多样性。例如,家庭服务机器人必须适应各种家庭环境和任务,要求它们从广泛的家庭环境数据中学习,以提高其泛化能力。
训练 EAI 的第二个挑战是 “数据孤岛”。获取如此全面的数据充满了挑战,包括高成本、耗时要求和潜在的安全风险。大多数 EAI 机器人组织仅限于在特定的受控环境中收集数据。实体之间缺乏数据共享加剧了这种情况,导致重复工作和资源浪费,并造成“数据孤岛”。这些孤岛严重阻碍了 EAI 的进展。
为了解决 EAI 开发中的数据可用性瓶颈,强大的数据捕获和生成管道至关重要,图 2 是这种管道的架构。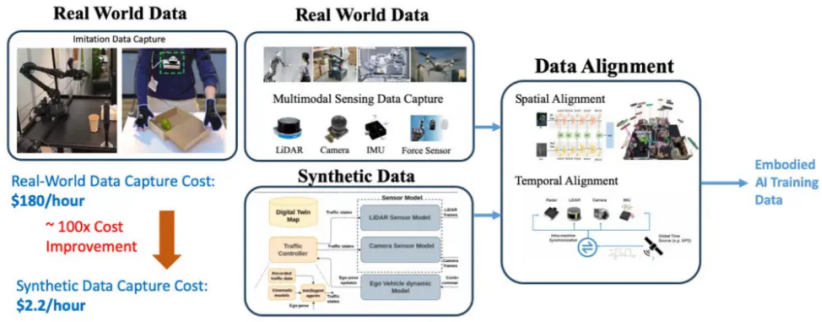
图 2 数据捕获和生成
此管道的第一个组件涉及捕获真实世界的数据,它包括从人类与物理环境的交互中收集数据以进行模仿学习,如捕获复杂交互任务的 Mobile-Aloha和专注于捕获与人类手部动作相关的数据的 PneuAct等研究项目中即可见到。此外,该管道涉及从多模态机器人传感器来收集数据,以捕获机器人对其物理环境的感知。
其次,鉴于获取大量高质量和多样化的 EAI 数据的成本高得令人望而却步,而基于数字孪生的仿真则被证明是一种有效的解决方案。它显著降低了数据收集成本,提高了开发效率。例如,为自动驾驶汽车捕获一小时的多模态机器人数据的成本为 180 美元,而模拟相同的数据成本仅为 2.20 美元,减少了近 100 倍 。此外,Sim2Real 技术的进步也促进了技能与知识从模拟环境到实际应用的转移。这项技术在虚拟空间中训练机器人和 AI 系统,使它们能够安全有效地学习任务,而不受现实世界的物理风险及限制。因此,真实数据和合成数据的结合是克服 EAI 中数据可用性挑战的战略方法。
另外,收集的数据和生成的数据都必须经过时间和空间对齐,这一点至关重要。它确保了来自各种传感器的数据既准确又同步,从而提供了对机器人环境和动作的统一和详细的理解。只有在这些过程之后,数据才能有效地用于训练 EAI 系统。
目前,应用 Sim2Real 技术的主要障碍是“现实差距”,即模拟环境与现实世界之间的差异,包括物理、照明和意外交互的差异。克服这一差距需要创新技术,例如域随机化(将各种场景整合到模拟中)和域自适应(调整 AI 的响应以更好地与现实世界的条件保持一致)。这些策略对于有效弥合模拟训练和实际应用之间的差距至关重要。
更多回帖

