感谢主办方抽中我作为本书的评测用户。收到书的那一刻内心是心潮澎湃的,却也倍感压力沉重。喜的是又能增长不少知识,丰富精神世界。不过与此同时,我也对书中不少技术词汇素未谋面,需要结合各种外界手段辅助拓展学习。不过我相信学习之路,I am not alone!在此,我首先分享我计划第一部分(本书1-4章)的阅读心得。
1 从TOP500到MLPerf:算力芯片的宏观格局
《算力芯片》一书开篇便通过TOP500和MLPerf两大基准测试,揭示了全球算力芯片的竞争态势。我想起古希腊哲学家赫拉克利特的名言:"没有什么是永恒的,除了变化本身。"在这个瞬息万变的科技世界里,这句话显得尤为贴切。TOP500的演变历程,从最初的向量超级计算机到如今的异构并行系统,就是生动诠释这一点的写照。TOP500采用HPL基准测试来评估超级计算机的性能,主要测量其在解决线性方程组时的浮点计算能力。这一方法突显了现代超算的核心优势——并行计算能力。举一个具体实例来说,天河二号采用了异构架构,集成了英特尔至强处理器和中国自主研发的申威众核加速器。这种CPU与协处理器的结合不仅提升了整体计算性能,还优化了能效比,使天河二号在Green500榜单上也表现出色。另一方面,MLPerf的出现标志着AI时代对算力需求的变化。它涵盖了图像分类、目标检测、自然语言理解、智能推荐算法、强化学习等多个AI任务,全面评估了芯片在实际AI工作负载中的表现。这两项基准测试共同构成了一个全面的算力评估体系,推动了芯片设计向多样化和专用化方向发展。
2 流水线与分支预测:CPU的华尔兹
第二章详细介绍了高性能CPU的流水线设计,这部分内容让我眼前一亮。流水线技术之于CPU,就如同流水线之于福特汽车制造——它彻底改变了游戏规则。从最初的5级流水线到如今的超流水线,每一步演进都是对效率的极致追求。深入探讨CPU微架构,指令集架构(ISA)是理解CPU工作原理的基础。CISC和RISC两种设计哲学反映了不同的计算机架构思路:CISC追求复杂指令集,每条指令可执行多个低级操作,适合处理复杂任务;而RISC则采用简单指令集,通过组合基本指令完成复杂操作,更适合并行执行。现代CPU如x86和ARM已经融合了这两种设计思想的优点。流水线技术是提高CPU效率的关键。经典的5级流水线(取指、译码、执行、访存、写回)通过并行处理指令的不同阶段,显著提升了CPU的指令吞吐量。超流水线技术通过增加流水线级数,进一步提高了并行度,但也带来了数据相关性和分支预测等挑战。分支预测技术,如感知机分支预测器和TAGE分支预测器,通过分析历史执行路径来预测未来的分支走向,有效减少了流水线停顿,提高了指令执行效率。
3. 缓存体系:CPU的记忆宫殿
第三章深入探讨了缓存硬件结构,这让我联想到了古希腊的"记忆宫殿"技巧。就像how内存选择存储哪些信息会极大影响人类的记忆和思考效率一样,CPU缓存的设计也直接关系到整个系统的性能。缓存系统设计是一个平衡速度、容量和成本的艺术。SRAM和DRAM的选择体现了这种权衡:SRAM速度快但成本高、密度低,适用于CPU内部缓存;DRAM容量大、成本低,但速度较慢,适用于主存。多级缓存结构(L1、L2、L3)通过不同容量和访问速度的组合,在性能和成本之间取得了平衡。缓存映射关系的选择(直接映射、全相联、组相联)影响了缓存命中率和硬件复杂度。写入策略(写直达、写回)和一致性协议(MESI、MOESI)则在多核系统中确保数据一致性和提升性能。旁路快表缓冲(TLB)作为虚拟内存技术的关键组件,通过缓存页表项加速地址转换过程,显著提升了内存访问速度。乱序执行引擎通过指令级并行(ILP)提高CPU性能,其中寄存器重命名、重排序缓冲区(ROB)、发射队列等技术解决了数据相关性和控制相关性问题,使得CPU能够动态调整指令执行顺序,最大化利用执行单元。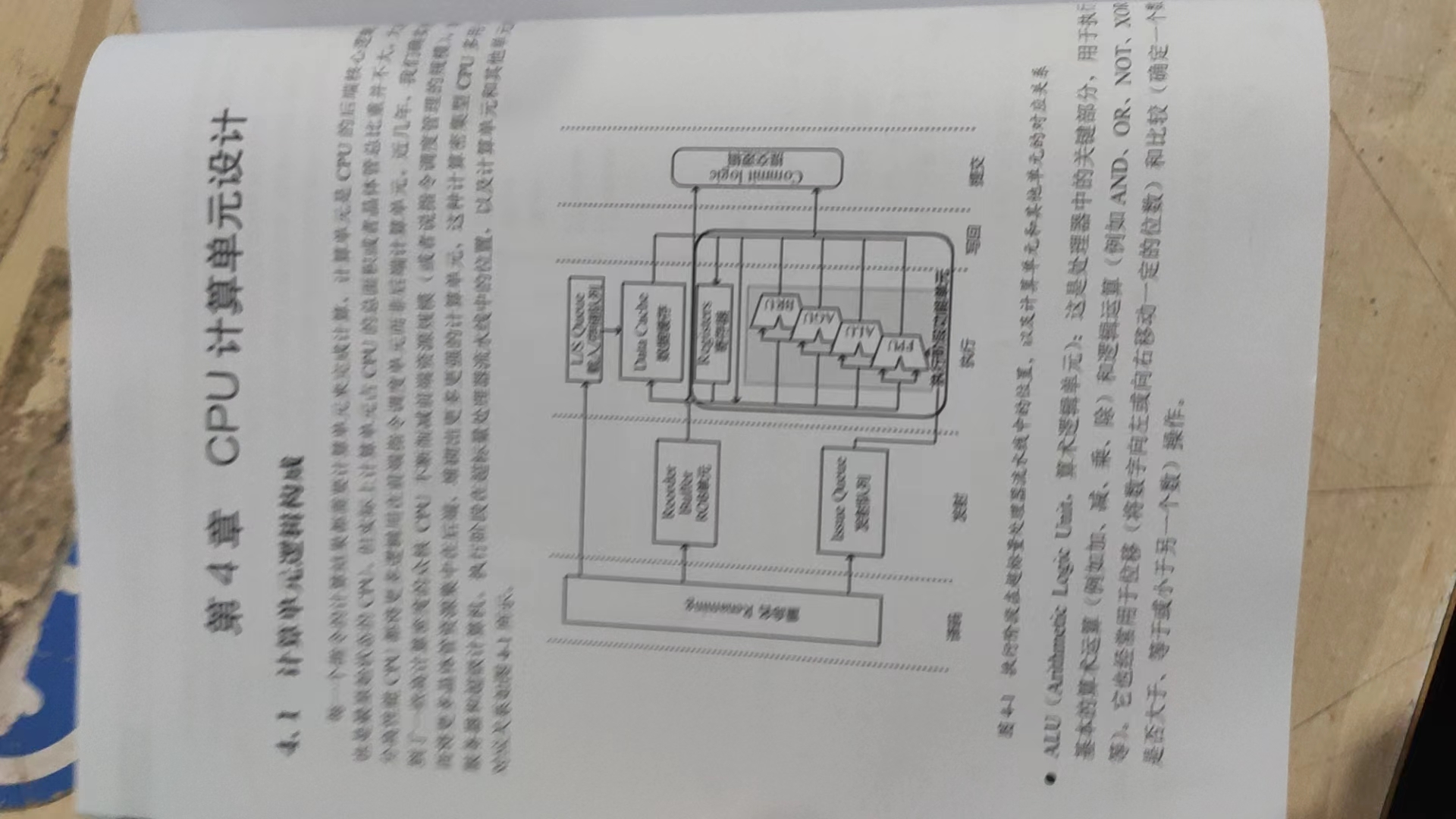
4. SIMD:并行计算的交响乐
第四章对CPU计算单元的讨论,尤其是对SIMD(单指令多数据)技术的深入分析,让我鼓掌叫好。SIMD就像是一位指挥家,用一个指令指挥整个乐团同时演奏,大大提高了计算效率。计算单元设计是CPU性能提升的另一重要方向。ALU(算术逻辑单元)作为CPU的核心,负责执行整数运算和逻辑运算。浮点数单元则专门处理浮点运算,其中加法器和乘法器的设计直接影响了CPU的浮点性能。SIMD(单指令多数据)技术如MMX、SSE、AVX等指令集的演进,体现了并行计算在CPU层面的应用。以AVX-512为例,它将SIMD寄存器宽度扩展到512位,每个时钟周期可以同时处理16个单精度或8个双精度浮点运算,大幅提升了向量化计算性能。这对科学计算、图形处理和机器学习等领域具有重大意义。ARM的SVE(可扩展向量扩展)指令集采用了可变长度向量的创新设计,为不同应用场景提供了灵活的SIMD支持。矩阵加速指令集的出现,如Intel的AMX,直接针对深度学习等应用中的矩阵运算进行优化,体现了通用CPU向AI友好型发展的趋势。
5.小结
通过这些设计和技术,现代CPU不仅在性能上得到了显著提升,还在能效比和灵活性方面取得了重要进展。这些进步不仅推动了高性能计算的发展,也为人工智能和其他计算密集型应用提供了强大的支持。现代CPU的设计不仅注重性能的提升,还特别关注能效比和灵活性,以适应不断变化的计算需求。算力芯片的发展史,某种程度上就是人类智慧的结晶。从单一的算术逻辑单元到复杂的超标量处理器,从简单的串行计算到高度并行的SIMD指令集,每一步演进都凝聚着工程师们的智慧和创新。正如爱因斯坦所说:"想象力是知识的预演。"今天的算力芯片,正是昨日科幻小说中的想象照进现实的结果。而未来,随着量子计算、神经形态计算等新技术的出现,我们或许会看到更加令人惊叹的算力革命。我还不禁想到了复杂系统理论。现代CPU就是一个典型的复杂系统,其中每一个组件都在相互影响、相互制约。正如蝴蝶效应所描述的那样,看似微小的设计变化可能会对整体性能产生巨大影响。这也是为什么CPU设计如此具有挑战性,同时又如此令人着迷。
宋代诗人有诗云"纸上得来终觉浅,绝知此事要躬行。"理论固然重要,但真正的理解和创新,还需要我们在实践中不断探索和验证。期待在未来的阅读和实践中,能够将这些知识转化为推动技术进步的动力。这本书的前四章为我打开了一扇通向计算机体系结构深处的大门。我期待着继续阅读后续章节,探索更多关于GPU和NPU的设计细节。在这个AI和大数据的时代,深入理解这些底层架构,对于我们每一个技术从业者来说,都是一笔无价的财富。
更多回帖

