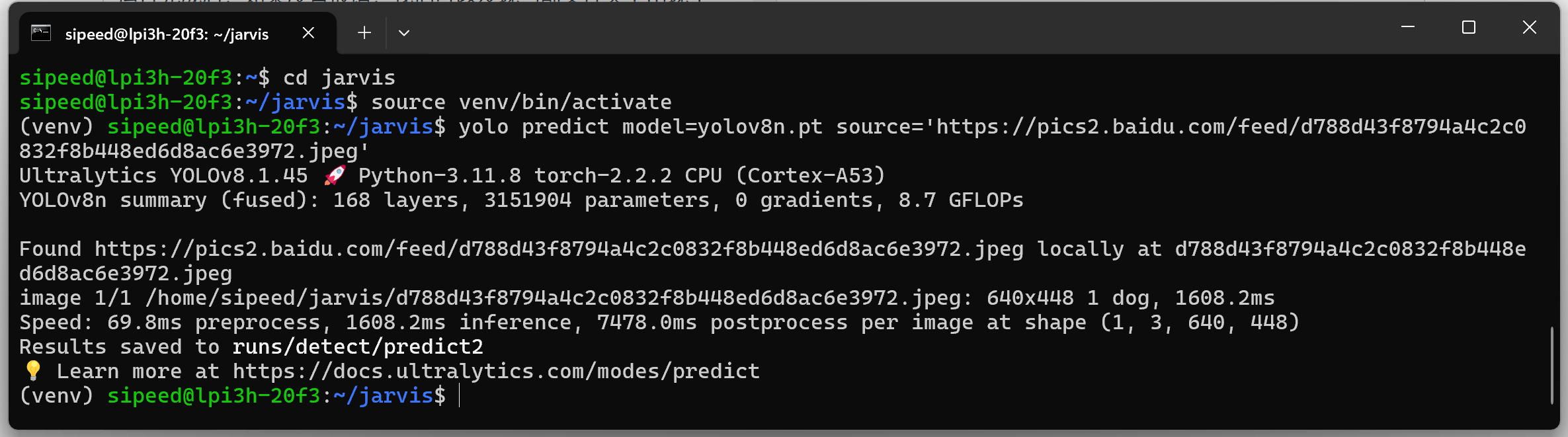
感谢发烧友论坛和Sipeed举办的本次活动,让我有机会可以体验到Longan Pi 3H这块超迷你的H618开发板。我打算用这块板子作为服务器,实现一个可以对话交互并且具备可视能力的ChatGPT助手。
我计划先在板子上上尝试部署CNN卷积神经网络,利用webcam获取实时图像,实现物体识别。同时利用麦克风实现语音输入与文字识别。当触发语音识别后,会同时进行语音识别与图像识别操作。识别完成后将结果整合,整合后再输入ChatGPT或其他大语言模型。最后再将大语言模型的输出结果利用TTS转化为语音进行播放。实现Chatgpt多模态输入(图像输入,语音输入),在赋予ChatGPT视觉的同时添加语音对话能力。
目前计划使用的具体方案和流程如下:
快递很快,没两天就收到了,先看看东西有哪些。

盒子很迷你,里面填充了满满的泡沫,板子保护的非常好。这个盒子大小适中,拿来做零件盒也是很好的。
打开盒子后,里面就是一块开发板,核心板和底板已经组装在一起了,不需要自己再另行组装。


看了下板子上内存和EMMC型号,发现是最高配的版本,4G内存,这个在刷好固件后使用btop --utf-force也可以看到。
当然了这是后话,那么现在我们就开始烧录固件。
这块板卡自带了EMMC,但同样支持从内存卡启动。因此最简单最快速的使用方式就是直接使用内存卡来运行系统。平时我自己在使用这一类板卡时也更倾向于使用内存卡或U盘这一类可移动设备来作为flash使用。虽然EMMC的速度和稳定性会更好,但我们知道flash是有擦写次数限制的,尤其是在使用SWAP分区的情况下,flash寿命会大大减少。因此如果使用外置储存,flash损坏后更换起来非常便捷;而更换EMMC就麻烦了很多。另外一点更重要的是,如果手上有多台设备,可以用一张卡玩遍所有设备,而不需要每一套设备都需要单独烧录一个系统,单独去更新软件包。
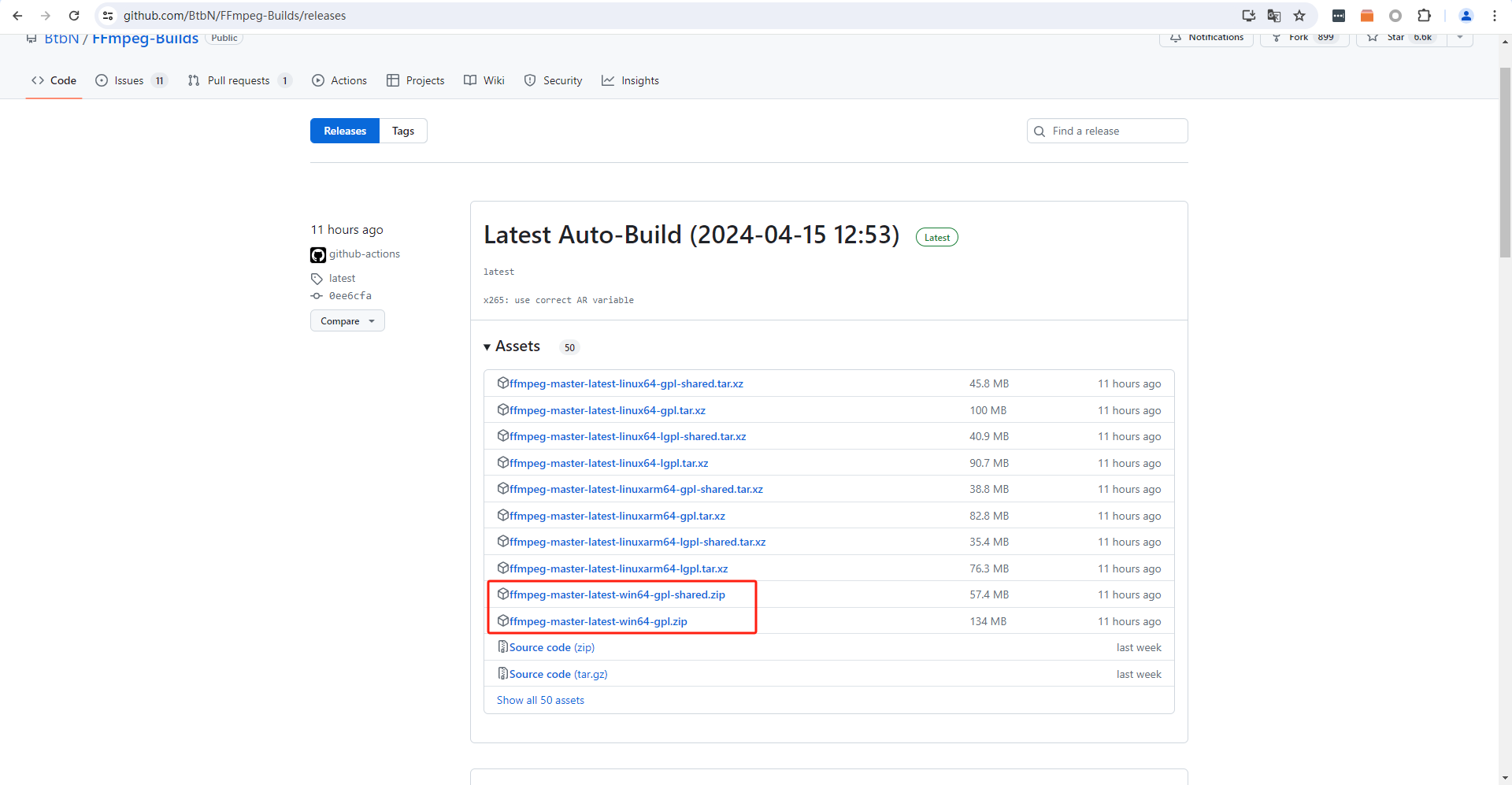
闲话说到这。我们先去官网上下载最新的Debian镜像,最新镜像地址在官方wiki上有:
https://wiki.sipeed.com/hardware/zh/longan/h618/lpi3h/3_images.html
注意镜像版本要使用SD版本的镜像。
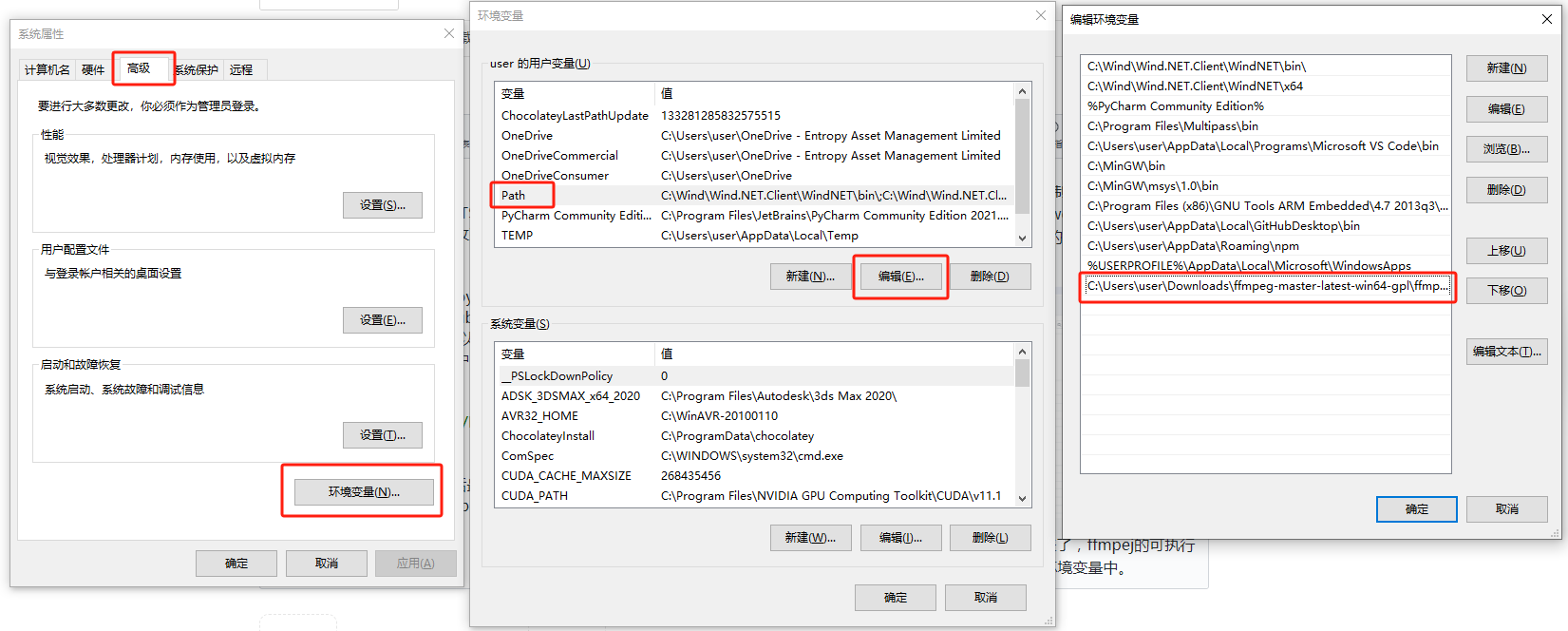
接下来还需要烧录工具,我使用的是balenaEtcher便携版。虽然这个工具体积大一点,但使用起来非常无脑,一键烧录。而且便携版也不需要安装,还算比较方便。
接着我们找一张16G以上的内存卡,插入电脑,打开balenaEtcher,选择镜像和内存卡,点击烧录,接着等待完成即可。
刷完后,将内存卡插入开发板,就算完成所有准备工作。开发板的内存插槽比较隐蔽,在这个位置:
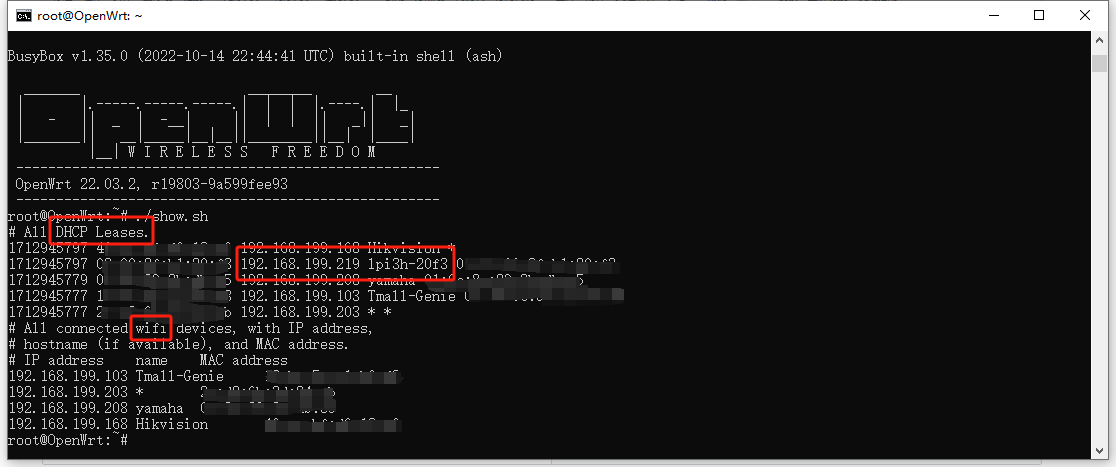
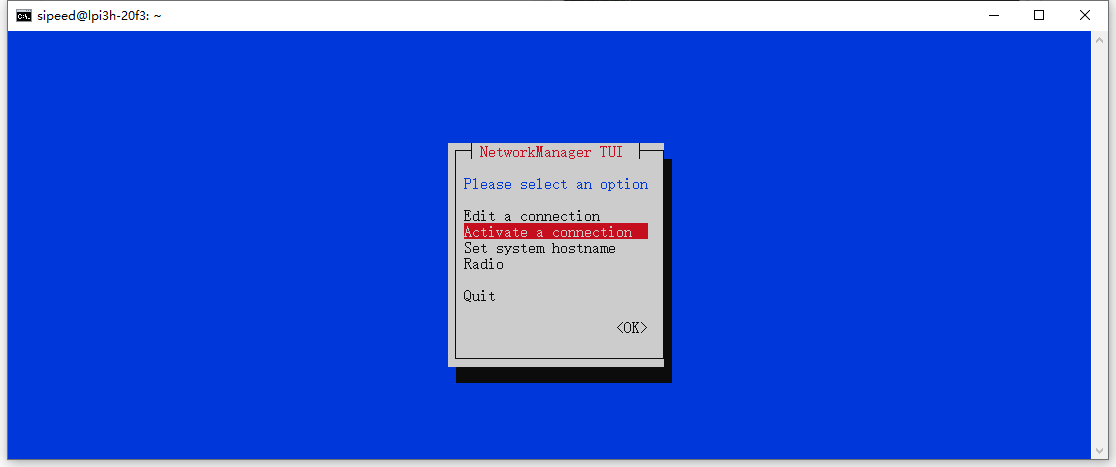
由于我没有HDMI显示器和键盘,因此无法像官方WIKI那样使用桌面系统。因此首次开机我也需要用无头方式配置无线网络。具体操作我们下期在评论区中再见。


 1
举报
1
举报
 1
举报
1
举报
 1
举报
1
举报

 1
举报
1
举报

 1
举报
1
举报




 1
举报
1
举报
 1
举报
1
举报
更多回帖