参考vitis的官方代码:Vitis_Accel_Examples/host/mult_compute_units at main · Xilinx/Vitis_Accel_Examples · GitHub
想要完成板卡上多核并行计算任务,需要包含多个例化单元的xclbin,对于要例化为多个计算单元的同一内核,可以使用nk标志指定 conn_u200.cfg 配置文件中的计算单元数量。同时,可以使用sp标志和slr标志指定 conn_u200.cfg 配置文件中的DDR和SLR连接方式,按照经验来说,注释掉sp标志和slr标志可以达到更高的时钟频率,但生成的DDR和SLR连接方式不固定。
示例配置文件将Vadd_Kernel的nk标志设置为4,即例化了4个Vadd_Kernel计算单元,第一次实验的conn_u200.cfg配置如下:
`[connectivity]`
`nk=Vadd_Kernel:``4`
`sp=Vadd_Kernel_1.m_axi_gmem0:DDR[``0``]`
`sp=Vadd_Kernel_1.m_axi_gmem1:DDR[``1``]`
`sp=Vadd_Kernel_1.m_axi_gmem2:DDR[``2``]`
`# slr=Vadd_Kernel_1:SLR0`
`sp=Vadd_Kernel_2.m_axi_gmem0:DDR[``0``]`
`sp=Vadd_Kernel_2.m_axi_gmem1:DDR[``1``]`
`sp=Vadd_Kernel_2.m_axi_gmem2:DDR[``2``]`
`# slr=Vadd_Kernel_2:SLR0`
`sp=Vadd_Kernel_3.m_axi_gmem0:DDR[``0``]`
`sp=Vadd_Kernel_3.m_axi_gmem1:DDR[``1``]`
`sp=Vadd_Kernel_3.m_axi_gmem2:DDR[``2``]`
`# slr=Vadd_Kernel_3:SLR1`
`sp=Vadd_Kernel_4.m_axi_gmem0:DDR[``0``]`
`sp=Vadd_Kernel_4.m_axi_gmem1:DDR[``1``]`
`sp=Vadd_Kernel_4.m_axi_gmem2:DDR[``2``]`
`# slr=Vadd_Kernel_4:SLR2`
host端代码主要对CommandQueue的执行逻辑进行了更改:
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``krnls[i].setArg(``0``, chunk_size);`
` ``krnls[i].setArg(``1``, buffer_in1[i]);`
` ``krnls[i].setArg(``2``, buffer_in2[i]);`
` ``krnls[i].setArg(``3``, buffer_output[i]);`
` ``q.enqueueMigrateMemObjects({buffer_in1[i], buffer_in2[i]},<span> </span>``0``, nullptr, &events_write[i]);`
`}`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``std::vector<cl::Event> events_vector{events_write[i]};`
` ``q.enqueueTask(krnls[i], &events_vector, &events_kernel[i]);`
`}`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``std::vector<cl::Event> events_vector{events_kernel[i]};`
` ``q.enqueueMigrateMemObjects({buffer_output[i]}, CL_MIGRATE_MEM_OBJECT_HOST, &events_vector, &events_read[i]);`
`}`
`q.finish();`
每个核都使用一套独立的任务单元,独立运行,无需等待其他核的任务完成。
测试数据为512MB,使用单个核,Kernel的处理时间为52.444ms,运行总时间为515.947ms,运行信息如下: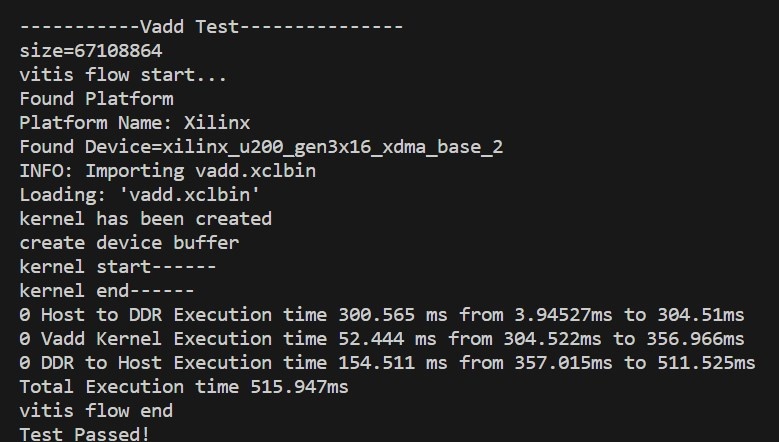
测试数据为512MB,使用多个核的运行总时间为355.438ms。注意到0,1,2,3将数据从Host运送到DDR的开始时间不同。
运行结果与理论值300.565ms+(52.444/4)ms+(154.511/4)ms = 352.303ms基本一致,并且明显有一个核的运行时间较短,可以复现,运行信息如下: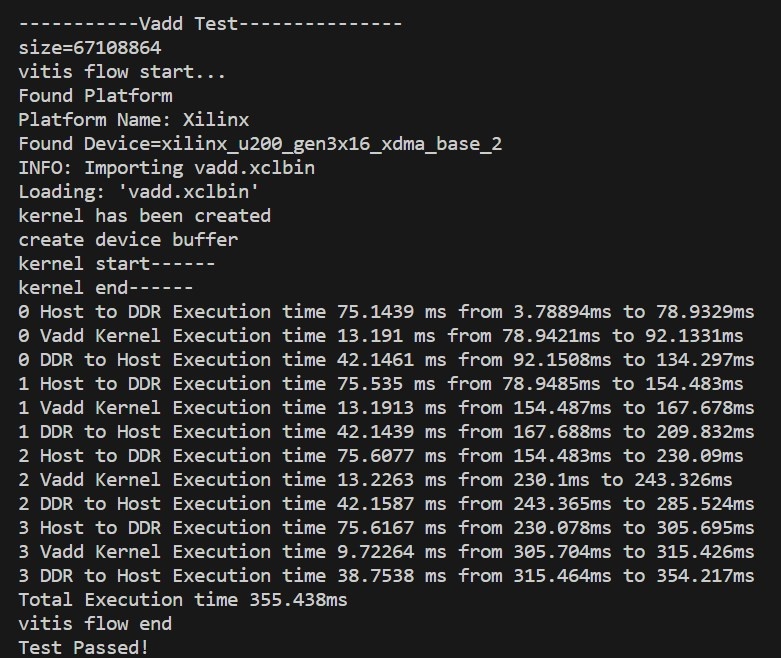
如果在Host to DDR的循环后加上 q.finish(); ,那么就能模拟加速核同一时刻开始运行的情况。注意到0,2和1,3将数据从DDR运送到Host的开始时间不同。
更改后,测试数据为512MB,Kernel的处理时间为32.2ms,相比于单核运行提升了40%的速率: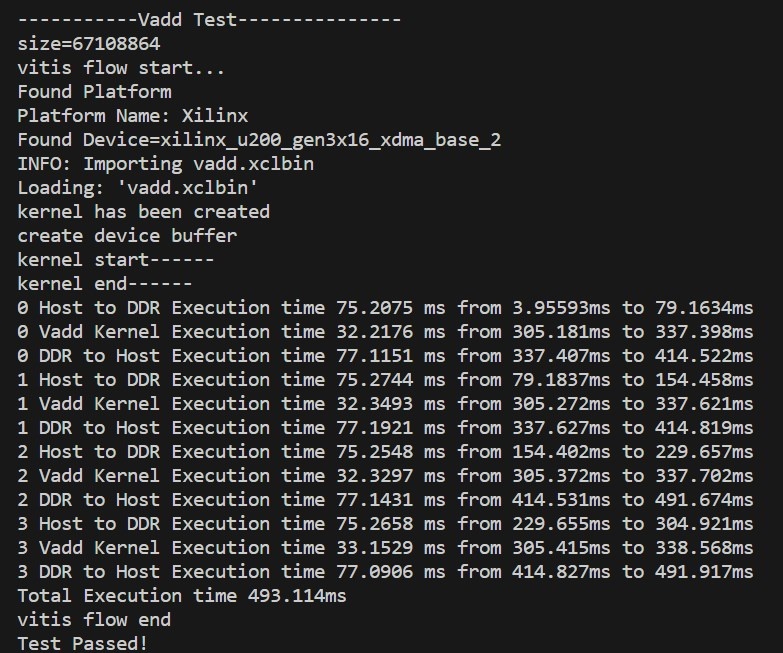
第二次实验修改了Kernel的例化方式,main函数端使用计算单元名称将连接相同的CU(对称计算单元)整合到一组中,让xrt自动调度:
`// std::vector<cl::Kernel> krnls(num_cu);`
`// for (int i = 0; i < num_cu; i++) {`
`// std::string krnl_name_full = "Vadd_Kernel:{Vadd_Kernel_" + std::to_string(i + 1) + "}";`
`// krnls[i] = cl::Kernel(program, krnl_name_full.c_str(), &cl_err);`
`// }`
`std::string krnl_name_full =<span> </span>``"Vadd_Kernel:{Vadd_Kernel_1,Vadd_Kernel_2,Vadd_Kernel_3,Vadd_Kernel_4}"``;`
`cl::Kernel krnls = cl::Kernel(program, krnl_name_full.c_str(), &cl_err);`
`...`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``krnls.setArg(``0``, chunk_size);`
` ``krnls.setArg(``1``, buffer_in1[i]);`
` ``krnls.setArg(``2``, buffer_in2[i]);`
` ``krnls.setArg(``3``, buffer_output[i]);`
` ``q.enqueueMigrateMemObjects({buffer_in1[i], buffer_in2[i]},<span> </span>``0``, nullptr, &events_write[i]);`
`}`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``krnls.setArg(``0``, chunk_size);`
` ``krnls.setArg(``1``, buffer_in1[i]);`
` ``krnls.setArg(``2``, buffer_in2[i]);`
` ``krnls.setArg(``3``, buffer_output[i]);`
` ``std::vector<cl::Event> events_vector{events_write[i]};`
` ``q.enqueueTask(krnls, &events_vector, &events_kernel[i]);`
`}`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``std::vector<cl::Event> events_vector{events_kernel[i]};`
` ``q.enqueueMigrateMemObjects({buffer_output[i]}, CL_MIGRATE_MEM_OBJECT_HOST, &events_vector, &events_read[i]);`
`}`
`q.finish();`
只使用一组中的一个Kernel,测试数据为512MB,Kernel的处理时间为52.4423ms,运行总时间为516.355ms,运行信息如下: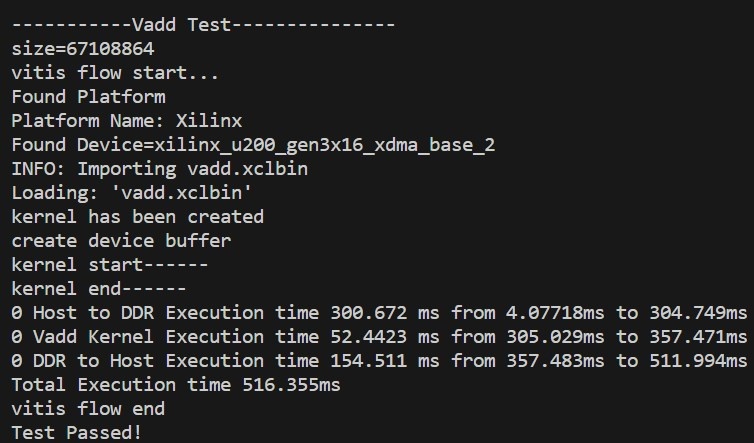
使用一组中的所有(四个)Kernel,测试数据为512MB,运行总时间为359.116ms,和多个Kernel对应多个对称计算单元结果基本相同: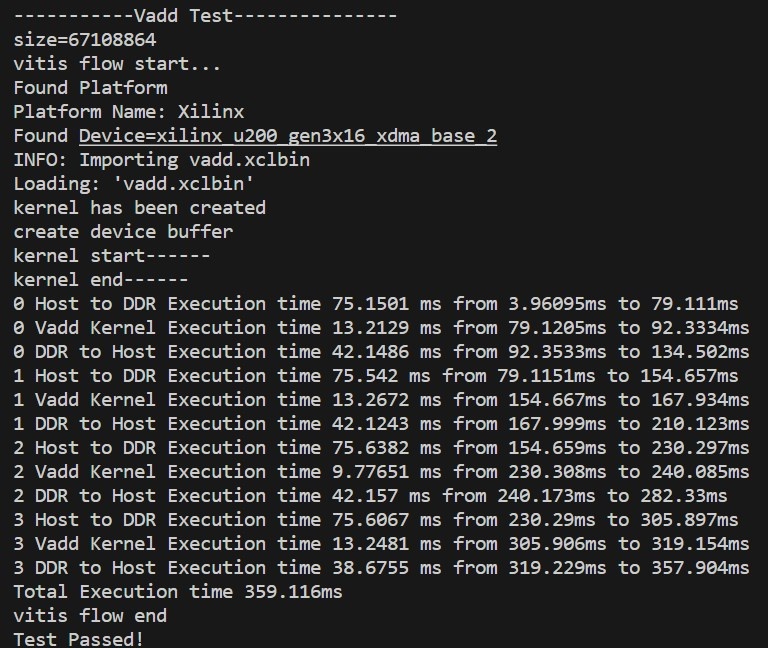
在Host to DDR的循环后加上 q.finish(),测试数据为512MB,Kernel的处理时间为32.2ms,和多个Kernel对应多个对称计算单元结果基本相同: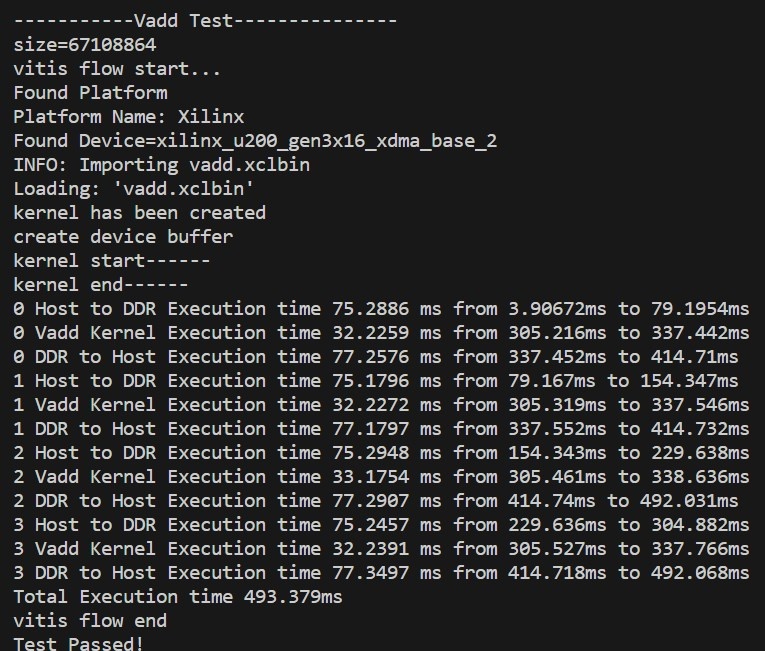
需要注意到的一点是,这种方式在kernel运行时调用了setArg。这种方式单线程可以支持,多线程是不支持的。
测试多线程需要在for循环前加上 #pragma omp parallel for num_threads(X),调用openmp库:
`// std::vector<cl::Kernel> krnls(num_cu);`
`// for (int i = 0; i < num_cu; i++) {`
`// std::string krnl_name_full = "Vadd_Kernel:{Vadd_Kernel_" + std::to_string(i + 1) + "}";`
`// krnls[i] = cl::Kernel(program, krnl_name_full.c_str(), &cl_err);`
`// }`
`std::string krnl_name_full =<span> </span>``"Vadd_Kernel:{Vadd_Kernel_1,Vadd_Kernel_2,Vadd_Kernel_3,Vadd_Kernel_4}"``;`
`cl::Kernel krnls = cl::Kernel(program, krnl_name_full.c_str(), &cl_err);`
`...`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``krnls.setArg(``0``, chunk_size);`
` ``krnls.setArg(``1``, buffer_in1[i]);`
` ``krnls.setArg(``2``, buffer_in2[i]);`
` ``krnls.setArg(``3``, buffer_output[i]);`
` ``q.enqueueMigrateMemObjects({buffer_in1[i], buffer_in2[i]},<span> </span>``0``, nullptr, &events_write[i]);`
`}`
`#pragma omp parallel<span> </span>``for` `num_threads(``4``)`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``krnls.setArg(``0``, chunk_size);`
` ``krnls.setArg(``1``, buffer_in1[i]);`
` ``krnls.setArg(``2``, buffer_in2[i]);`
` ``krnls.setArg(``3``, buffer_output[i]);`
` ``std::vector<cl::Event> events_vector{events_write[i]};`
` ``q.enqueueTask(krnls, &events_vector, &events_kernel[i]);`
`}`
`for` `(``int` `i =<span> </span>``0``; i < num_cu; i++) {`
` ``std::vector<cl::Event> events_vector{events_kernel[i]};`
` ``q.enqueueMigrateMemObjects({buffer_output[i]}, CL_MIGRATE_MEM_OBJECT_HOST, &events_vector, &events_read[i]);`
`}`
`q.finish();`
第三次实验修改了DDR的连接方式,修改后的conn_u200.cfg的配置如下:
`[connectivity]`
`nk=Vadd_Kernel:``4`
`sp=Vadd_Kernel_1.m_axi_gmem0:DDR[``0``]`
`sp=Vadd_Kernel_1.m_axi_gmem1:DDR[``0``]`
`sp=Vadd_Kernel_1.m_axi_gmem2:DDR[``0``]`
`# slr=Vadd_Kernel_1:SLR0`
`sp=Vadd_Kernel_2.m_axi_gmem0:DDR[``1``]`
`sp=Vadd_Kernel_2.m_axi_gmem1:DDR[``1``]`
`sp=Vadd_Kernel_2.m_axi_gmem2:DDR[``1``]`
`# slr=Vadd_Kernel_2:SLR0`
`sp=Vadd_Kernel_3.m_axi_gmem0:DDR[``2``]`
`sp=Vadd_Kernel_3.m_axi_gmem1:DDR[``2``]`
`sp=Vadd_Kernel_3.m_axi_gmem2:DDR[``2``]`
`# slr=Vadd_Kernel_3:SLR1`
`sp=Vadd_Kernel_4.m_axi_gmem0:DDR[``3``]`
`sp=Vadd_Kernel_4.m_axi_gmem1:DDR[``3``]`
`sp=Vadd_Kernel_4.m_axi_gmem2:DDR[``3``]`
`# slr=Vadd_Kernel_4:SLR2`
测试数据为512MB,使用单个核,Kernel的处理时间为91.1519ms,运行总时间为554.525ms: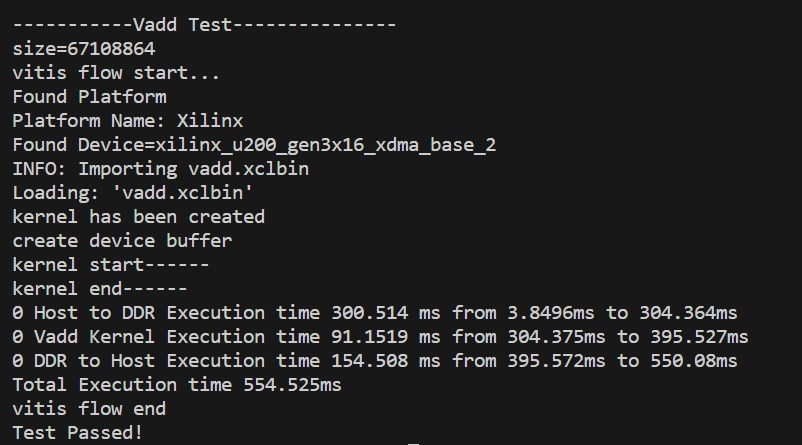
测试数据为512MB,使用多个核,不添加 q.finish()函数,运行总时间为368.643ms,与理论值300.514ms+(91.1519/4)ms+(154.508/4)ms = 361.928ms基本一致: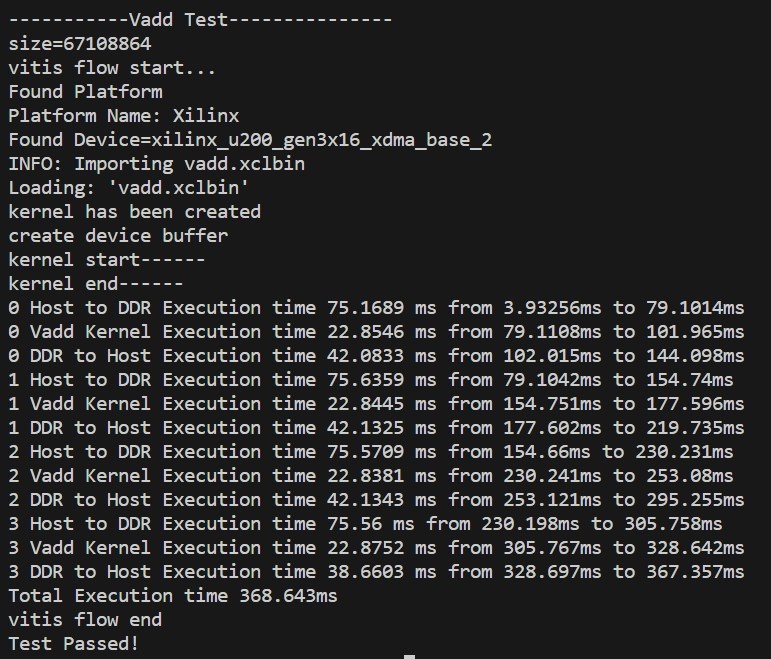
测试数据为512MB,使用多个核,在Host to DDR的循环后加上 q.finish()后,Kernel的处理时间约为22.8ms,相比于单核运行提升了75%的速率: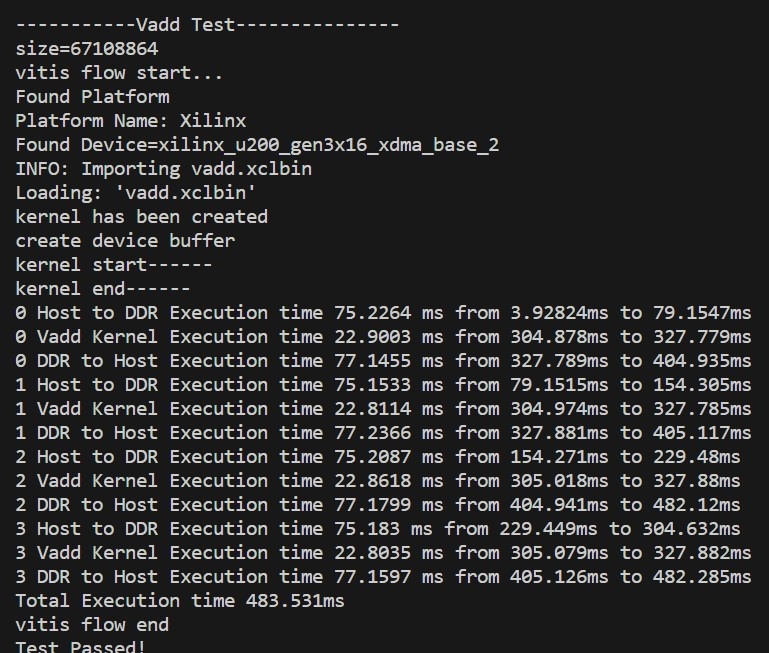
总结测试表格如下:
| 测试配置 | kernel处理时间 | 运行总时间 |
|---|---|---|
| -------------------------------------------------------------------- | ||
| 多个Kernel对应多个对称计算单元,DDR012+单核 | 52.444ms | 515.947ms |
| - | - | - |
| 多个Kernel对应多个对称计算单元,DDR012+多核,无finish函数 | 13.1*3 + 9.7 = 49ms | 355.438ms |
| 多个Kernel对应多个对称计算单元,DDR012+多核,有finish函数 | 32.2ms | 493.114ms |
| 一组Kernel对应多个对称计算单元,DDR012+单核 | 52.4423ms | 516.355ms |
| 一组Kernel对应多个对称计算单元,DDR012+多核,无finish函数 | 13.2*3 + 9.7 = 49.3ms | 359.116ms |
| 一组Kernel对应多个对称计算单元,DDR012+多核,有finish函数 | 32.2ms | 493.379ms |
| DDR000+单核 | 91.1519ms | 554.525ms |
| DDR000+多核,无finish函数 | 22.8*4 = 91.2ms | 368.643ms |
| DDR000+多核,有finish函数 | 22.8ms | 483.531ms |
[](https://confluence.yusur.tech/pages/viewpage.action?pageId=125475513)
更多回帖
 长按上方图片保存到相册
长按上方图片保存到相册
 复制链接
复制链接