三、硬件加速之—使用PL加速FFT运算(Vivado)
前四期测评计划:
一、开箱报告,KV260通过网线共享PC网络
二、Zynq超强辅助-PYNQ配置,并使用XVC(Xilinx Virtual Cable)调试FPGA逻辑
三、硬件加速之—使用PL加速FFT运算(Vivado)
四、硬件加速之—使用PL加速矩阵乘法运算(Vitis HLS)
FFT(Fast Fourier Transform)快速傅里叶变换强大和实用性不言而喻,哪哪儿都能见到其身影,比如:
以上只是一些常见的应用,FFT还有很多其他的应用,比如在数学,密码学,天文学,地震学,生物学等领域。
本文主旨
利用PL端的并行性和灵活性来实现高效的FFT运算,在KV260搭建一个硬件加速算法,作为对比,我同时使用ARM核进行fft运算,验证PL硬件加速的效果。
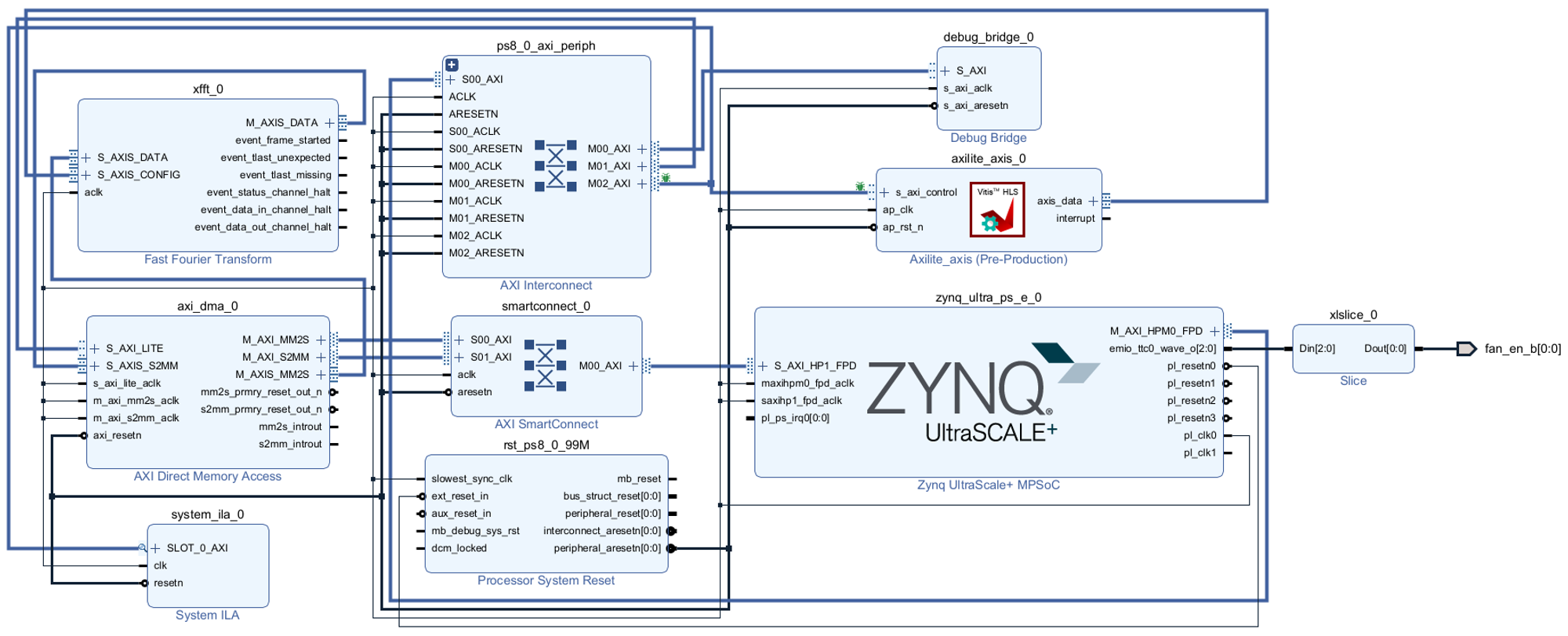
该系统的架构图如下:

该系统是一个基于KV260的FFT加速器,它可以对输入的时域信号进行快速傅里叶变换,从而得到信号的频域表示。
这个系统的架构分为两个部分,PS(Processing System)和PL(Programmable Logic)。PS部分是基于ARM的处理器核心,它负责控制整个系统的运行,以及与外部设备的通信。PL部分是由FPGA实现的可编程逻辑,它负责执行FFT的核心算法,以及与PS部分的数据交换。
PS部分包含了以下的组件:
ARM Core:这是一个基于ARM架构的处理器核心,它运行着我在上一章节介绍的PYNQ系统。它可以通过AXI Lite接口与PL部分的HLS核进行配置和控制,以及通过AXI1接口与PL部分的AXI DMA进行数据传输。
DDR:用来存储FFT的输入和输出的信号数据,它可以通过AXI1接口与PL部分的AXI DMA进行数据交换。
PL部分包含了以下的组件:
AXI DMA:这是一个基于AXI协议的直接存储器访问控制器,它负责在PS部分的DDR和PL部分的FFT IP核之间进行高速的数据传输,以及在PL部分的FFT IP核和HLS核之间进行数据传输。它可以通过AXI1接口与PS部分的ARM Core和DDR进行通信,以及通过AXI Stream接口与PL部分的FFT IP核。
FFT IP Core:这是一个基于IP核(Intellectual Property Core)的FFT模块,它实现了FFT的核心算法,可以对输入的时域信号进行快速傅里叶变换,从而得到信号的频域表示。它可以通过AXI Stream接口与PL部分的AXI DMA进行数据交换。
HLS Core:这是一个基于HLS(High-Level Synthesis)的自定义模块,ARM Core可以通过AXI Lite接口对FFT IP核的工作模式进行配置。
Vivado 工程
创建一个vivado工程,如下:
其中,HLS模块的功能是将一个32位的无符号整数(ap_uint<32>)从AXI Lite接口读入,并将其低24位作为一个数据包(pkt)发送到AXI Stream接口。代码如下:
#include "ap_int.h"
#include "ap_axi_sdata.h"
#include "hls_stream.h"
typedef ap_axiu<24, 0, 0, 0> pkt;
void axilite_axis(ap_uint<32> axi_data,
hls::stream<pkt>& axis_data) {
#pragma HLS INTERFACE mode=s_axilite port=return
#pragma HLS INTERFACE mode=s_axilite port=axi_data
#pragma HLS INTERFACE mode=axis port=axis_data
pkt v;
v.data = axi_data.range(23, 0);
v.last = 1;
axis_data.write(v);
}
现对其关键语句进行说明:
...
#pragma HLS INTERFACE mode=s_axilite port=return // HLS指令,指定函数的返回端口使用AXI Lite接口模式
#pragma HLS INTERFACE mode=s_axilite port=axi_data // HLS指令,指定函数的axi_data参数使用AXI Lite接口模式
#pragma HLS INTERFACE mode=axis port=axis_data // HLS指令,指定函数的axis_data参数使用AXI Stream接口模式
...
v.last = 1; // 将1赋值给v的last字段,表示这是一个数据包的最后一个字节
axis_data.write(v); // 调用axis_data对象的write方法,将v写入到AXI Stream接口
在vitis hls编译完成后,可以查看其寄存器的偏移地址:
* S_AXILITE Registers
+---------------+----------+--------+-------+--------+----------------------------------+----------------------------------------------------------------------+
| Interface | Register | Offset | Width | Access | Description | Bit Fields |
+---------------+----------+--------+-------+--------+----------------------------------+----------------------------------------------------------------------+
| s_axi_control | CTRL | 0x00 | 32 | RW | Control signals | 0=AP_START 1=AP_DONE 2=AP_IDLE 3=AP_READY 7=AUTO_RESTART 9=INTERRUPT |
| s_axi_control | GIER | 0x04 | 32 | RW | Global Interrupt Enable Register | 0=Enable |
| s_axi_control | IP_IER | 0x08 | 32 | RW | IP Interrupt Enable Register | 0=CHAN0_INT_EN 1=CHAN1_INT_EN |
| s_axi_control | IP_ISR | 0x0c | 32 | RW | IP Interrupt Status Register | 0=CHAN0_INT_ST 1=CHAN1_INT_ST |
| s_axi_control | axi_data | 0x10 | 32 | W | Data signal of axi_data | |
+---------------+----------+--------+-------+--------+----------------------------------+----------------------------------------------------------------------+
在vivado工程的最后一步,是生成bitstream,我们需要用到两个文件:
<porj folder>/porj_name.runs/impl_1/design_1_wrapper.bit
<porj folder>/porj_name.gen\\sources_1\\bd\\design_1\\hw_handoff/design_1.hwh
design_1_wrapper.bit 文件,是 Vivado 软件生成的 bitstream 文件,它包含了 overlay 的硬件配置信息,可以用来编程 FPGA 的 PL 部分。
design_1.hwh 文件,是 Vivado 软件生成的 hardware handoff 文件,它包含了 overlay 的系统配置信息,比如 IP 的版本,中断,复位,控制信号等。PYNQ 可以根据这个文件来自动识别 overlay 的结构,分配驱动,启用或禁用功能,将信号与 Python 方法对应等。
以相同的文件名重命名以上两个文件,并拷贝到PYNQ对应目录中,比如:
/home/root/jupyter_notebooks/fft
-rw-r--r-- 1 root root 7797812 Oct 1 09:37 tt_fft.bit
-rw-r--r-- 1 root root 633459 Oct 1 09:37 tt_fft.hwh
在PYNQ调用
新建Notebook,可以随意命名,本文中保持与bit文件同名。
/home/root/jupyter_notebooks/fft
-rw-r--r-- 1 root root 7797812 Oct 1 09:37 tt_fft.bit
-rw-r--r-- 1 root root 633459 Oct 1 09:37 tt_fft.hwh
-rw-r--r-- 1 root root 318571 Oct 1 10:03 tt_fft.ipynb
首先导入需要用到的模块:
from pynq import Overlay, allocate, time
import numpy as np
import cProfile
from pynq.lib.debugbridge import DebugBridge
import matplotlib.pyplot as plt
%matplotlib inline
加载Overlay,并显示所有IP
ovfft = Overlay('./tt_ffta.bit')
ovfft.ip_dict
会得到如下结果:
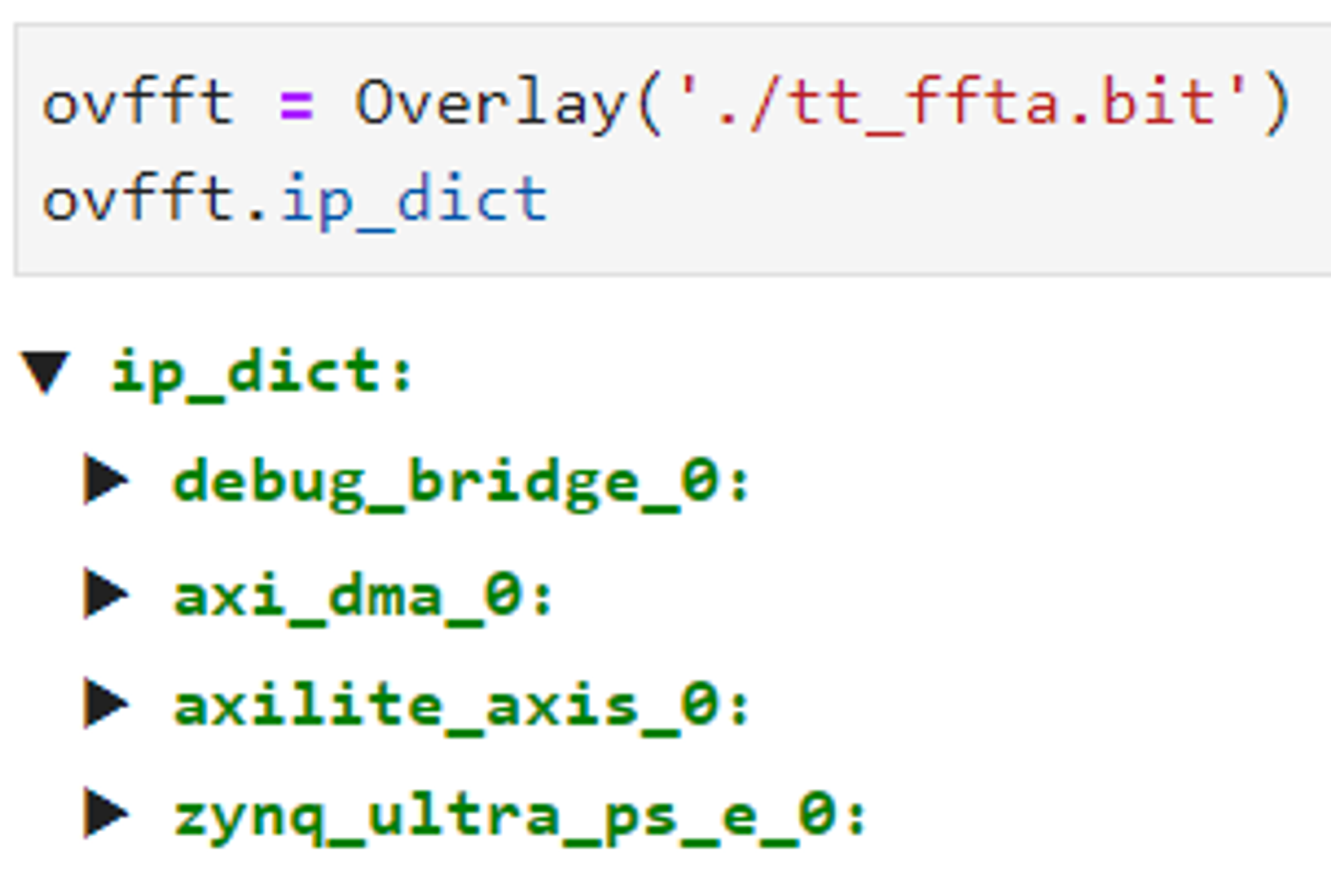
可以看到,挂载到AXI总线的设备包含4个,分别是:
PS系统
debug_bridge
axi_dma
axilite_axis
点击三角符号展开,还可以查看更加详细的IP信息,比如寄存器信息、基地址、偏移地址等。
接下来我们生成原始波形,我会将使用这些数据测试pl端和ps端fft的差异:
# 分配内存
fft_N = 16384
fftIn = allocate(shape=(fft_N,), dtype=np.csingle)
fftOut_pl = allocate(shape=(fft_N,), dtype=np.csingle)
frequency = 10
n = np.arange(fft_N)
fftIn.real = np.sin(2 * np.pi * frequency * n / fft_N) # 赋值实数部分
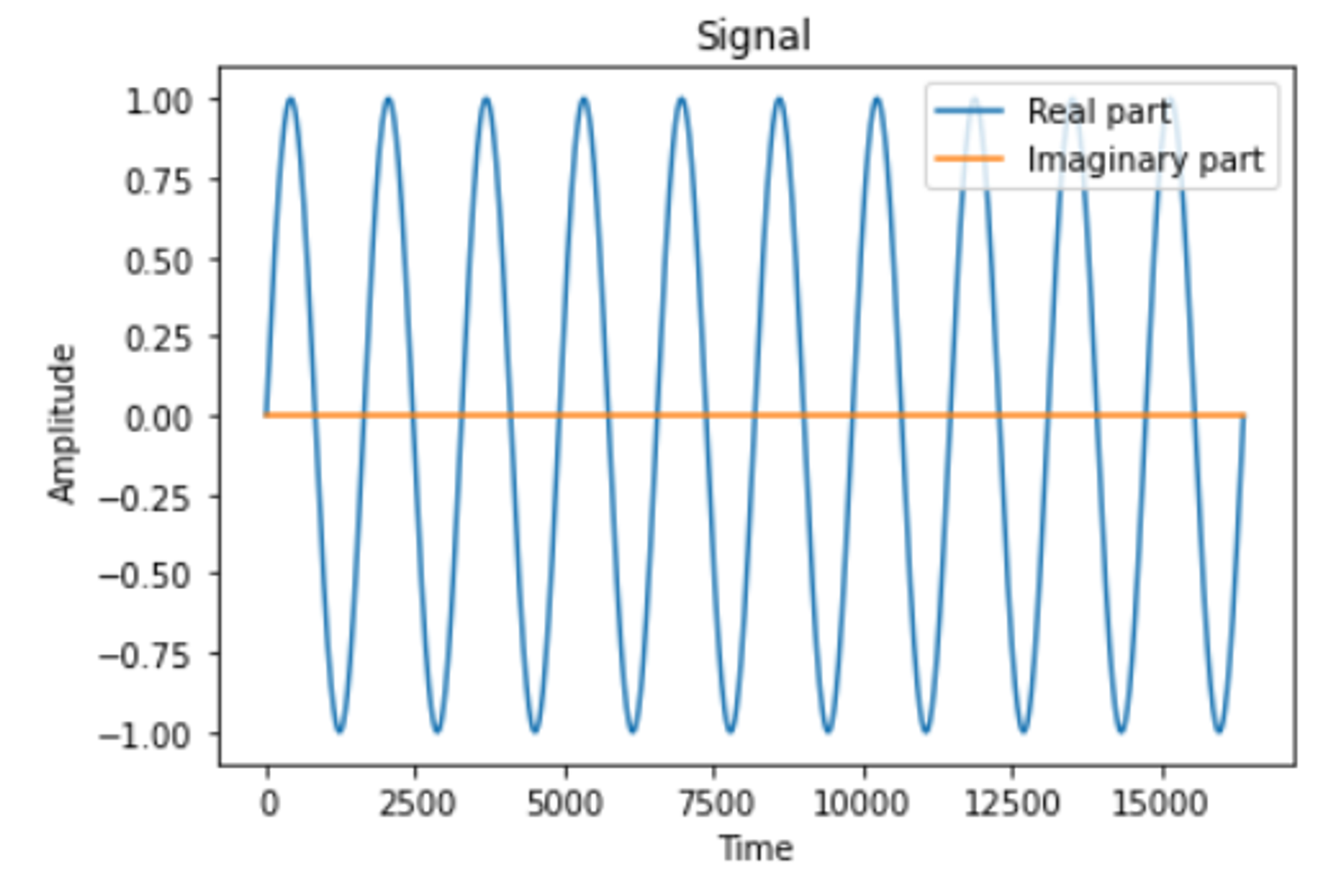
# 绘制原波形图
plt.plot(n, fftIn.real, label='Real part')
plt.plot(n, fftIn.imag, label='Imaginary part')
plt.xlabel('Time')
plt.ylabel('Amplitude')
plt.title('Signal')
plt.legend()
plt.show()
定义两个函数,分别对应使用ps端和pl端进行fft运算:
def psfft (): # numpy自带的fft运算
fftOut_np = np.fft.fft(fftIn)
def plfft (): # 使用pl端资源进行计算
dma = ovfft.axi_dma_0
dma.sendchannel.transfer(fftIn)
dma.recvchannel.transfer(fftOut_pl)
dma.sendchannel.wait()
dma.recvchannel.wait()
接下来我们分别测试两者的差异,首先测试ps端运算fft的性能:
cProfile.run ('psfft ()') # 分析ps端fft性能
---
11 function calls in 0.006 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.006 0.006 2008801880.py:1(npfft)
1 0.000 0.000 0.006 0.006 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 _pocketfft.py:118(_fft_dispatcher)
1 0.000 0.000 0.006 0.006 _pocketfft.py:122(fft)
1 0.000 0.000 0.006 0.006 _pocketfft.py:49(_raw_fft)
1 0.000 0.000 0.000 0.000 _pocketfft.py:78(_get_forward_norm)
1 0.000 0.000 0.006 0.006 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method numpy.asarray}
1 0.000 0.000 0.000 0.000 {built-in method numpy.core._multiarray_umath.normalize_axis_index}
1 0.006 0.006 0.006 0.006 {built-in method numpy.fft._pocketfft_internal.execute}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
测试ps端运算fft的性能:
cProfile.run ('plfft ()') # 分析pl端fft性能
---
150 function calls in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.002 0.002 259443043.py:1(plfft)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 buffer.py:104(flush)
1 0.000 0.000 0.000 0.000 buffer.py:109(invalidate)
6 0.000 0.000 0.000 0.000 buffer.py:89(physical_address)
2 0.000 0.000 0.000 0.000 buffer.py:93(virtual_address)
2 0.000 0.000 0.000 0.000 dma.py:106(transfer)
2 0.000 0.000 0.002 0.001 dma.py:166(wait)
4 0.000 0.000 0.000 0.000 dma.py:68(running)
23 0.000 0.000 0.001 0.000 dma.py:73(idle)
21 0.000 0.000 0.000 0.000 dma.py:82(error)
6 0.000 0.000 0.000 0.000 mmio.py:130(write_mm)
71 0.001 0.000 0.001 0.000 mmio.py:82(read)
1 0.000 0.000 0.000 0.000 overlay.py:357(__getattr__)
1 0.000 0.000 0.000 0.000 overlay.py:464(is_loaded)
2 0.000 0.000 0.000 0.000 xrt.py:517(xclSyncBO)
1 0.000 0.000 0.000 0.000 xrt_device.py:383(flush)
1 0.000 0.000 0.000 0.000 xrt_device.py:394(invalidate)
1 0.000 0.000 0.002 0.002 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method builtins.getattr}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
ps端耗时是pl端的3倍。
考虑到我pl端fft ip核运行速度只有100M,MSPS也仅仅设置为10M,复数乘法配置也是以资源优先,再加上axi dma ip核本身的延迟,实际应用中ps与pl端的差异会更大。
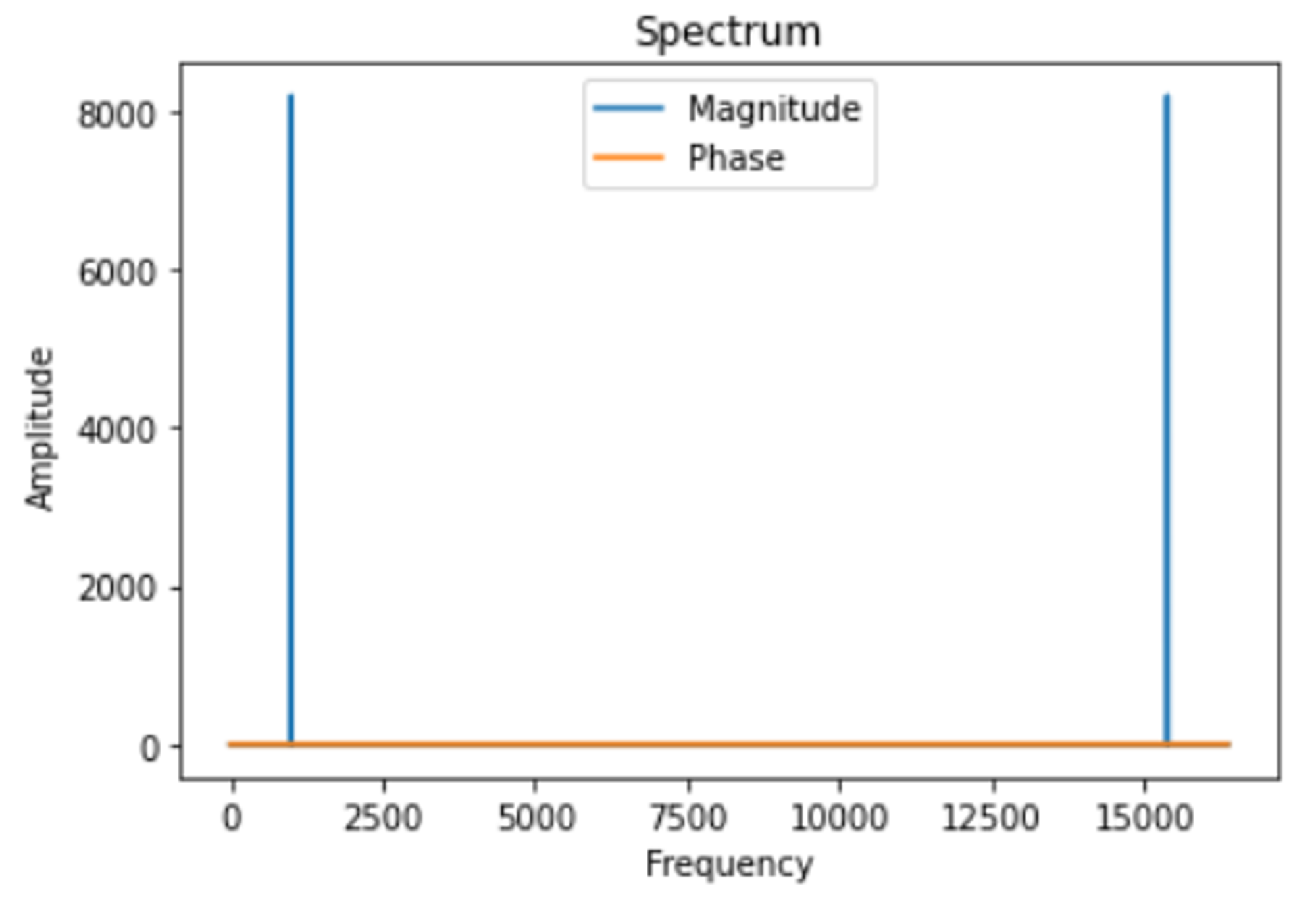
既然到这里了,我还是打印出fft运算的结果吧,毕竟使用PYNQ方便之处就是进行数据处理和可视化:
plt.plot(n, np.abs(fftOut_pl), label='Magnitude')
plt.plot(n, np.angle(fftOut_pl), label='Phase')
plt.xlabel('Frequency')
plt.ylabel('Amplitude')
plt.title('Spectrum')
plt.legend()
plt.show()
总结:
即使我在pl端的fft ip核并未发挥出充分的性能的情况,pl的运算速度已经明显超越ps端,可见使用PL硬件加速是一种高效、低功耗、低延迟、高灵活性的技术,它可以为各种算法或应用提供优化的解决方案。
 2
2
 举报
1
举报
举报
1
举报
更多回帖

