| SGD (随机梯度下降优化) | keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False) |
| Adagrad (自适应梯度下降算法) | keras.optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0) |
| Adadelta (自适应学习速率算法) | keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=None, decay=0.0) |
| RMSprop(均方差传播算法) | keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0) |
| Adam(自适应动量估计) | keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) |
| Adamax(自适应最大阶动量估计) | keras.optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0) |
| Nadam(Nesterov加速自适应动量估计) | keras.optimizers.Nadam(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, schedule_decay=0.004) |
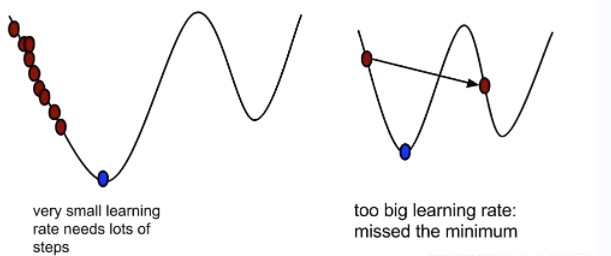
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
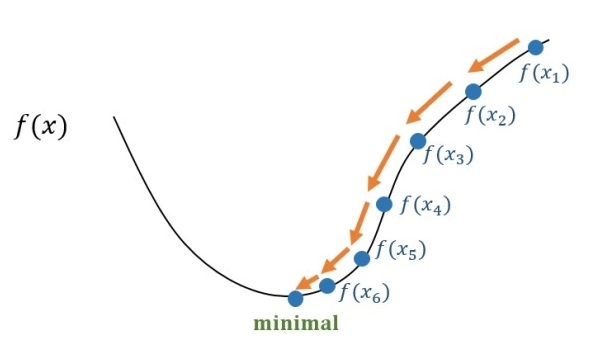
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点
更多回帖

