利用包括 OpenVINOTM 工具包在内的各种英特尔软件, 创建端到端 AI/ML( 人工智能/ 海洋学习) 管道, 演示量化- 软件培训和推断。 工作流程通过 Helm * 通过微型服务和 Docker* 图像进行部署 。
选定配置 下载下载工作流程。
完成时间 :10分钟 10分钟
语言:皮松*
可用软件 :Op
timim* Intel-接口、Docker*、Kubernetes*、Helm* Optim*
如何运作
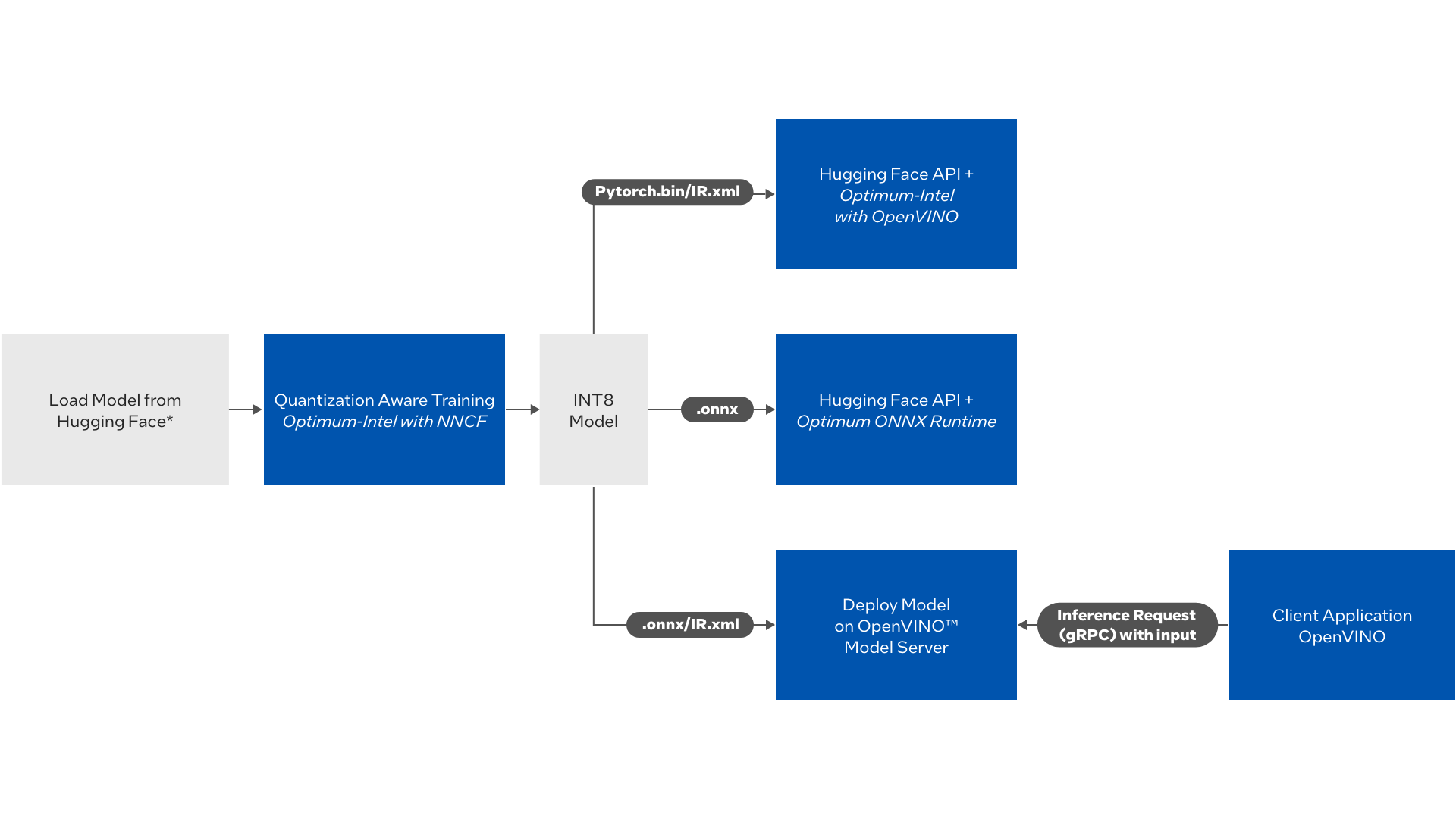
图1:流程图图
工作流程执行如下:
管道触发器来自 Hugging Face 的自然语言处理模型(NLP) 的量化- 软件培训。 该容器的输出为存储在本地/ 库德存储的INT8 优化模型 。
一旦该模型产生,那么推论应用即可与下列一种动保单一起部署:
使用“最佳情报”的 包装脸型API的推论
使用 最大 ONNX 运行时间 使用 抱抱脸API 的推论
使用 OpenVINOTM 模拟服务器部署模型并发送 grpc 请求
开始
先决条件
您需要一个符合下述边缘节点和软件要求的Kubernetes* 群集。
边缘节点要求
下列处理器之一:
Itel Xeon Platinum 8370C 处理器@ 2. 80GHz (16 vCPUs)。
至少64GB内存。
NVIDIA* GPU的 Intel Xeon处理器
至少112GB内存。
至少256GB硬盘。
互联网连接。
Ubuntu* 20.04 LTS.
软件要求
安装 docker Dockcker 合成器。
任何库伯涅茨变异的味道
本项目使用Rancher* K3S* 安装。
curl -sfL
https://get.k3s.io | sh -s - --write-kubeconfig-mode 644export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
主节点上安装了赫尔姆
简单命令列表如下。详情请参见Helm安装指示。
curl -fsSL -o get_helm.sh
https://raw.githubusercontent.co ... pts/get-helm-3chmod 700 get_helm.sh./get_helm.sh
步骤1:安装和运行工作流程
下载源代码
选择以下选项之一 :
选定配置 下载下载工作流程。
配置 下载
或,运行命令 :
git clone
https://github.com/intel/nlp-training-and-inference-openvinocd nlp-training-and-inference-openvino/#checkout latest tagtag=$(git describe --tags `git rev-list --tags --max-count=1`)echo $taggit checkout $tag -b latest
修改 Helm 图表值
编辑编辑管理图/ qat/ values.yaml如下文件 :
替换《current_working_gitfolder》下 下挂载路径 :当前的工作回收目录 。
注:相对路径对赫尔姆不起作用 。
编辑编辑管理图/ qat/ values.yaml用于文件的《train_node》和《inference_node》数值之下图标选择器键。
选择任何可用的节点, 与此命令的节点名称进行训练和推断 。
kubectl get nodes --show-labels 值.yaml 文件
图标选择器: trainingnode: 《train_node》 inferencenode: 《inference_node》
编辑编辑编辑编辑管理图/ qat/ values.yaml具有更高数值的文件最大培训量(_train_ samples)和最大值(_eval_samples)默认值为 50 个样本。
查找所有参数的详细信息参数参数表。
步骤2:运行螺旋图
本节载有分步骤的细节,以安装具体的赫尔姆海图,同时提供训练和推论。了解更多有关赫尔姆命令的信息 。
使用案例1:使用Optimim* Intel* 界面使用 Optimum* 的 Optimim* Intel* 接口使用 OptVINOTM 推断的QAT
我们有两个方法可以进行推论:
使用输入 CSV 文件( 默认) 。
使用参数(备选) - 问题和上下文参数。 我们需要编辑部署量- 最佳部署量- yaml根据问题和背景论据进行推论。部署量- 最佳部署量- yaml:
args: [“-c”, “chown openvino -R /home/inference cd /home/inference 。/run_onnx_inference.sh ‘Who is sachin’ ‘Sachin is a cricket player’”]
训练舱通过先安装_ job.yaml。在 CPU 上进行默认培训。要启用 GPU 来进行培训,请参见启用 NVIDIA GPU 用于培训。
推断舱通过部署量- 最佳部署量- yaml.
cd helmcharthelm install qatchart qat --timeout 《time》 排《time》具有格式的值n 当当当当量,其中s秒。上述硬件配置和最大培训量_ 样本=50我们建议您设置《time》值为480个。您可以增加减少硬件配置的值。请参看排除故障发生超时错误时。
确认训练是否已经部署
kubectl get pods 如果训练舱位于“运行”状态,则该舱已经部署。否则,通过运行命令检查任何错误:
kubectl describe pod 《pod_name》 训练舱在完成训练后将处于“完成”状态。培训产出科详细信息。
一旦培训完成, 推论舱将自动部署。 推论舱使用 OpenVINOTM 运行时间作为 Hugging Face APIs 的后端, 并使用训练舱生成的模型作为输入 。
最佳推断产出
对推断舱的输入将取自开放光量_ optimum_ 推断/数据文件夹。
OpenVINOTM 与最佳* 推断舱整合的输出将存储在开阔线_optimim_ inference/ logs. txt文件。
查看日志时使用 :
kubectl logs 《pod_name》
使用例2:使用 OpenVINOTM 型服务器推断QAT
训练舱通过先安装_ job.yaml。 OpenVINOTM 模拟服务器舱通过部署@ oms.yaml.
复制件副本部署@ oms.yaml调自管理图/部署_yaml文件夹中掌上型图/卡特/板板确保只有一个部署a.yaml用于单个部署的模板文件夹中的文件 。
遵循与使用情况1.
OpenVINOTM 模型服务器推断输出
OpenVINOTM 模型服务器从训练容器中部署优化模型。 使用命令查看日志 :
kubectl logs 《pod_name》
客户端可以使用 OpenVINOTM APIs 将 Grpc 请求发送到服务器 。
查找更多详细信息OpenVINOTM 示范服务器适应器 API.
OpenVINOTM 客户端应用程序样本运行如下 。
打开一个新终端以运行客户端程序。更改《hostname》在运行前的下面命令中。
《hostname》OpenVINOTM 型服务器部署所在的节点主机名 。
kubectl get nodes azureuser@SRDev:~/nlp-training-and-inference-openvino/question-answering-bert-qat/openvino_optimum_inference$ kubectl get nodes NAME STATUS ROLES AGE VERSION srdev 圆 Ready control-plane,master 16d v1.24.6+k3s1 在这种情况下,主机名应该是srdev 圆。
运行向 OpenVINOTM 模型服务器发送请求的客户端程序
这将下载从打开_ model_ zoo并使用 ovms 服务器进行推断。
cd 《gitrepofolder》/openvino_inference docker run -it --entrypoint /bin/bash -v “$(pwd)”:/home/inference -v “$(pwd)”/。./quantization_aware_training/models/bert_int8/vocab.txt:/home/inference/vocab.txt --env VOCAB_FILE=/home/inference/vocab.txt --env INPUT=“
http://en.wikipedia.org/wiki/bert_(sesame_street)” --env MODEL_PATH=《hostname》:9000/models/bert openvino/ubuntu20_dev:2022.2.0 -c /home/inference/run_ov_client.sh 客户应用程序将触发一个互动终端终端,根据具体背景提出问题。
http://en.wikipedia.org/wiki/bert_(sesame_street)这是作为输入提供的。请输入一个问题。
使用案例3:通过Optimim* ONNX运行时间使用 Optimim* OnNX 执行提供方使用 OptVINOTM 执行推论QAT
训练舱通过先安装_ job.yaml.
使用 OpenVINOTM 执行提供者舱的 Optim ONNX 运行时间部署nnnx.yaml.
复制件副本部署nnnx.yaml调自管理图/部署_yaml文件夹中掌上型图/卡特/板板确保只有一个部署a.yaml模板文件夹中的文件 。
遵循与使用情况1.
Onnnxrun 时间 推断输出
对推断舱的输入将取自onnxovep_optimum_inference/ 数据文件夹。
onnxrun时间推断舱的输出将存储在onnxovep_optimum_ inference/ logs.txt 上传信息文件。
查看日志时使用 :
kubectl logs 《pod_name》
案例4:仅使用推定
在触发推断之前,确保您能够访问模型文件,并编辑qat/价值.yaml文件。
只保留一个部署a.yaml文件中qat/板板以只部署一个推论应用程序的文件夹。
使用 OpenVINOTM Intel 的 泡泡脸 API 使用部署量- 最佳部署量- yaml。可接受的模型格式为pytorch 或 IR.xml
OpenVINOTM 模型服务器,使用部署@ oms.yaml。模式格式格式为IR.xml
使用 OpenVINO-EP 运行时间部署nnnx.yaml文件。 模式格式为.onnx
要运行推断,请使用以下命令:
cd helmcharthelm install qatchart qat --no-hooks 清理清理
使用后,使用命令清理资源:
helm uninstall qatchart 有用命令
解除安装螺旋 : (如果需要)
sudo rm -rf /usr/local/bin/helm 卸载 K3S : (如果需要)
/usr/local/bin/k3s-uninstall.sh 引用到解除安裝Rancher K3S 的步骤。
步骤3:评价使用个案产出
查看通过 Helm Chart 部署的电流, 命令如下 :
kubectl get pods 从 pods 列表中取出 pod_ name, 运行 :
kubectl logs 《pod_name》 如果播客处于完成状态, 这意味着他们已经完成运行任务 。
培训产出
培训集装箱产出将是培训集装箱中产生的最佳INT8模型。quantization_aware_training/model文件夹。
校验是否所有模型文件都在《output》文件夹。
A logs.txt生成文件以存储包含准确性细节的培训容器日志 。
推断输出
推断输出的结果将是推断时间和对问题的答案,每个问题将回答到作为输入提供的上下文文件
在推断文件夹中生成日志文件名为logs.txt
设置 Azure 存储( 可选)
使用不均度†多节点 Kubernetes 设置的存储, 如果您想要在所有节点上使用相同的存储 。
参考文献
Azure File Storage
设置步骤
Azure门户网站上的开放Azure CLI终端。
创建资源组 :
az group create --name myResourceGroup --location eastus
创建存储账户 :
STORAGEACCT=$(az storage account create --resource-group “myResourceGroup” --name “mystorageacct$RANDOM” --location eastus --sku Standard_LRS --query “name” | tr -d ‘“’)
创建存储键 :
STORAGEKEY=$(az storage account keys list --resource-group ”myResourceGroup“ --account-name $STORAGEACCT --query ”[0].value“ | tr -d ‘”’)
创建文件共享 :
az storage share create --name myshare --quota 10 --account-name $STORAGEACCT --account-key $STORAGEKEY
创建挂载点 :
mkdir -p /mnt/MyAzureFileShare
挂载共享 :
sudo mount -t cifs //$STORAGEACCT.file.core.windows.net/myshare /mnt/MyAzureFileShare -o vers=3.0,username=$STORAGEACCT,password=$STORAGEKEY,serverino
在 Helm 图表中使用 Azure 存储
在 /nt/ MyAzureFileShare 中克隆 git_repo , 并使之成为您的工作目录 。
编辑编辑编辑编辑《current_working_directory》内。/管理图/ qat/ values.yaml要反映相同的文件。
所有其他指示与安装赫尔姆海图和触发输油管的上述步骤相同。
培训完成后,您可以查看Azure门户网站,并在文档中检查模型的生成情况。


